vc++网络编程 多线程
As modern programs continue to get more complex in terms of both input and execution workloads, computers are designed with more CPU cores to match. To achieve high performance for these programs, developers must write code that effectively utilizes their multicore machines. For C++ programming language, this is accomplished through the usage of multithreading. Being able to efficiently execute programs in a multi-threading environment is a building block for effective modern programs.
随着现代程序在输入和执行工作负载方面变得越来越复杂,计算机被设计为具有更多可匹配的CPU内核。 为了实现这些程序的高性能,开发人员必须编写有效利用其多核计算机的代码。 对于C ++编程语言,这是通过使用多线程来完成的。 能够在多线程环境中高效执行程序是有效的现代程序的基础。
CPU time is a valuable resource for any program. It measures the amount of time for which CPU does useful work — performing arithmetic operations or processing instructions for computer programs. While multi-threaded execution delivers a much higher utilization of CPU time than sequential execution, a lack of hardware understanding or inefficient use of data objects and threads can be performance bottlenecks, erasing the speedup gained by using multi-threading in the first place. With this in mind, for this post, I’ll cover some common pitfalls and optimizations for C++ multi-threaded programs.
CPU时间是任何程序的宝贵资源。 它测量CPU进行有用工作的时间-对计算机程序执行算术运算或处理指令。 尽管多线程执行比顺序执行提供了更高的CPU时间利用率,但是对硬件的理解不足或对数据对象和线程的低效率使用可能会成为性能瓶颈,从而消除了首先使用多线程获得的加速。 考虑到这一点,在本文中,我将介绍C ++多线程程序的一些常见陷阱和优化。
This article is organized as follows:
这篇文章的结构安排如下:
- Software prerequisites
软件先决条件
- Understanding your hardware
了解您的硬件
- Performance implications of false sharing
错误共享的性能影响
- Scheduling with thread affinity
通过线程关联进行调度
- Thread pool
线程池
I.软件先决条件 (I. Software prerequisites)
Sample code snippets in this article are benchmarked and profiled using GoogleBenchmark and perf profiler in Linux. Please spend some time to download and set them up before running the code.
本文中的示例代码片段使用Linux中的GoogleBenchmark和perf分析器进行了基准测试和分析。 在运行代码之前,请花一些时间下载并设置它们。
二。 了解您的硬件 (II. Understanding your hardware)
Hardware knowledge is fundamental for writing fast code. Knowing how long it takes for a computer to execute an instruction or how data is stored and fetched to different types of memory allows programmers to optimize their code optimally. Here’s an example for a typical modern CPU:
硬件知识是编写快速代码的基础。 知道计算机执行一条指令要花费多长时间,或者知道如何将数据存储并提取到不同类型的存储器后,程序员才能最佳地优化其代码。 这是典型的现代CPU的示例:


A modern CPU generally consists of multiple processor cores, each has its own L1 data and instruction caches, but all share the same memory hierarchy. For a multi-threaded program, threads are scheduled into these cores and use provided core resources such as its L1 cache and instruction cache. Fetch instruction issued by a thread will go to the main memory, grab the data, and cache it in L1 for subsequent read instructions. In particular, data will be stored in a cache-line/block within a set of the cache. A write instruction issued by a thread to a memory location, first, will invalidate access to that location of other cores (to keep them from reading old/stale values) by invalidating (or evicting) the cache-line/block that contains the data. Typically, the size of a cache line is 64 bytes.
现代CPU通常由多个处理器内核组成,每个处理器内核都有自己的L1数据和指令高速缓存,但是都共享相同的内存层次结构。 对于多线程程序,将线程调度到这些内核中,并使用提供的内核资源,例如其L1缓存和指令缓存。 线程发出的获取指令将进入主存储器,获取数据,并将其缓存在L1中以供后续读取指令使用。 特别地,数据将被存储在一组缓存中的缓存行/块中。 线程发出的向存储位置的写指令首先将通过使包含数据的缓存行/块无效(或收回)来使对其他核心位置的访问无效(以防止它们读取旧值/陈旧值)。 。 通常,高速缓存行的大小为64字节。
三, 虚假共享及其性能影响 (III. False Sharing and its performance implications)
In a multi-threaded program, different threads can access and modify shared data. As stated above, threads are able to access and modify shared data while still maintaining consistent shared data’s value by invalidating cache-line/blocks of other cores that contain the cache the shared data (cache coherence protocol). This leads to a scenario when data from multiple threads that were not meant to share gets mapped to the same cache line/block. When this happens, cores accessing seemingly unrelated data can alternatively send invalidations to each other when performing write instructions, making it as if multiple threads are fighting over the same data. In particular, on subsequent data reads of other threads, these threads will encounter cache misses since cache lines/blocks that contain their data has been invalidated earlier, and they will have to go into memory to fetch their data again. This incident is known as false sharing.
在多线程程序中,不同的线程可以访问和修改共享数据。 如上所述,线程能够通过使包含高速缓存的其他内核的高速缓存行/其他内核的高速缓存行/块共享数据(高速缓存一致性协议),来访问和修改共享数据,同时仍保持一致的共享数据的值。 这就导致了一种情况,即来自多个线程的不希望共享的数据被映射到同一缓存行/块。 发生这种情况时,访问看似无关的数据的内核可以交替执行执行写指令时彼此发送无效信息,从而使多个线程好像在争夺同一数据。 特别是,在后续读取其他线程的数据时,这些线程将遇到高速缓存未命中,因为包含其数据的高速缓存行/块已在较早之前失效,因此它们将不得不进入内存以再次获取其数据。 此事件称为虚假共享。
Now, with the awareness of false sharing, how can we resolve itLet’s consider the following example where we will benchmark the performance of a program that atomically increases four variables, each by 100000 times. We have a simple update function:
现在,有了虚假共享的意识,我们该如何解决让我们考虑下面的示例,在该示例中,我们将基准测试一个程序的性能,该程序以原子方式增加四个变量,每个变量增加100000次。 我们有一个简单的更新功能:
The update function increases an atomic integer 100000 times. A single-threaded version for our example might look like this:
更新函数将原子整数增加100000次。 本示例的单线程版本可能如下所示:
Now, a fairly intuitive way to speed up the above sequential version is to assign each atomic integer to a thread and let each thread increases assigned an atomic integer on its own. This is a common optimization strategy in parallel programming:
现在,加快上述顺序版本的一种相当直观的方法是将每个原子整数分配给一个线程,并让每个线程增加对自己分配的原子整数的分配。 这是并行编程中的常见优化策略:
While it seems like we will attain some speed up from dividing the workload equally between four threads, we’ll see that this implementation is indeed a typical example of false sharing, and it performs even worse than the sequential version. Why’s thatLet’s figure out where four atomic integers a, b, c, and d sit in memory. We can print out their addresses as such:
虽然看起来我们可以通过在四个线程之间平均分配工作量来提高速度,但是我们会看到,该实现确实是错误共享的典型示例,并且其性能甚至比顺序版本差。 为什么让我们找出四个原子整数a,b,c和d在内存中的位置。 我们可以这样打印出他们的地址:
Compiling and executing with g++, I got the following addresses:
使用g ++进行编译和执行,我得到以下地址:
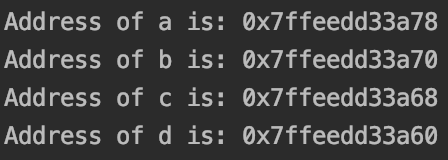
From the printed information, it’s obvious that our four atomic integers are four bytes away from each other. Since cache coherence is typically at the cache line/block granularity with typically 64-byte-size cache line, our four atomic variables will end up on the same line. Hence, when each thread grabs its dedicated atomic integer and modifies it, it invalidates the cache line that contains the modifying atomic integer in other cores, but this line is also the line that contains other cores’ atomic integers. This is where false sharing happens.
从打印的信息来看,很明显我们的四个原子整数彼此相距四个字节。 由于高速缓存一致性通常在高速缓存行/块粒度(通常为64字节大小的高速缓存行)中,因此我们的四个原子变量将最终出现在同一行上。 因此,当每个线程获取其专用的原子整数并对其进行修改时,它会使包含其他内核中的正在修改的原子整数的缓存行无效,但该行也是包含其他内核的原子整数的行。 这就是虚假共享的地方。
Let’s benchmark these two above approaches to verify the existence of false sharing. The profiling code using GoogleBenchmark looks like this:
让我们对上述两种方法进行基准测试,以验证错误共享的存在。 使用GoogleBenchmark的分析代码如下所示:
Running the benchmark using:
使用以下命令运行基准测试:
yields:
产量:

As we can see, the false-sharing version, even with the usage of multithreading, performs as twice as bad as the single-threaded version. Next, let’s use perf to confirm that this performance downgrade indeed comes from false sharing by measuring cache misses. Running perf for the single-threaded and false-sharing version using:
我们可以看到,即使使用了多线程,虚假共享版本的性能也比单线程版本高两倍。 接下来,让我们使用perf通过测量缓存未命中来确认这种性能降级的确是由于错误共享而引起的。 使用以下命令为单线程和错误共享版本运行perf:
yields:
产量:

Let’s notice the L1-dcache-load-misses metric. As we can see, the single-threaded version barely has L1 cache misses, 0.00% (too small compared to the total number of L1 loads), while the false-sharing version suffers from significantly higher L1 cache misses, 162x times higher than that of the single-threaded version. This confirms the existence of false sharing.
让我们注意L1-dcache-load-misses指标。 如我们所见,单线程版本几乎没有L1缓存未命中率,为0.00%(与L1负载总数相比太小),而错误共享版本遭受的L1缓存未命中率则高得多,是后者的162倍。单线程版本。 这证实了虚假共享的存在。
So, how can we resolve this false sharing issueRemember that false sharing happens because different variables accessed by different threads are mapped to the same cache line when they are fetched from the main memory. Therefore, an intuitive solution is to make different variables map to different cache lines by pad each variable with extra bytes so that each variable size fits the whole cache line where it’s mapped to. Sample code for this solution can look like this:
那么,我们如何解决这个虚假的共享问题呢请记住,会发生错误共享,因为从主内存中获取不同线程访问的不同变量时,它们会映射到同一缓存行。 因此,一种直观的解决方案是通过用额外的字节填充每个变量来使不同的变量映射到不同的缓存行,以使每个变量的大小适合其映射到的整个缓存行。 此解决方案的示例代码如下所示:
We can confirm now that these variables do not sit in the same cache line anymore by printing out their memory locations (this is left as an exercise to the reader). Benchmarking this multi-threaded version using GoogleBenchmark yields the following result:
现在我们可以通过打印出它们的存储位置来确认这些变量不再位于同一高速缓存行中(这留给读者练习)。 使用GoogleBenchmark对这个多线程版本进行基准测试会产生以下结果:

From figure 6, we can see that consumed time for using padded atomic integer version reduced significantly compared to the other two versions. Now, let’s profile the number of L1 cache miss for this version using perf:
从图6中,我们可以看到,与其他两个版本相比,使用填充原子整数版本所消耗的时间显着减少。 现在,让我们使用perf配置此版本的L1高速缓存未命中数:

Again, we can see that using a padded data structure reduces L1 cache misses caused by false sharing by a factor of 3.
再次,我们可以看到,使用填充数据结构将由于错误共享而导致的L1高速缓存未命中率降低了3倍。
VI。 通过线程关联进行调度 (VI. Scheduling with thread affinity)
Another optimization to look out for in a multi-threaded program is thread affinity: where to place threads that are in relation to each other. Placing threads that share data close to each other, or into certain cores, allows programmers to exploit inter-thread locality. In other words, thread affinity takes advantage of the fact that remnants of the threads that were run on a given core may remain in that core’s state (e.g data is still in the cache memory) when another thread, which is also in need of that remnants, takes place. Therefore, scheduling that thread to execute on the same core improves its performance by reducing performance-degrading events such as cache misses. Likewise, placing threads that share data far apart may result in contention, especially if the threads are scheduled to different NUMA nodes.
在多线程程序中要注意的另一种优化是线程亲和力:将相互关联的线程放在何处。 将共享数据的线程彼此靠近或放置在某些内核中,可使程序员利用线程间局部性。 换句话说,线程亲缘关系利用了这样一个事实:在给定内核上运行的线程的剩余部分可能在另一个线程也需要时,仍保留在该内核的状态(例如,数据仍在高速缓存中)。残留物发生。 因此,安排该线程在同一内核上执行将通过减少性能下降事件(例如缓存未命中)来提高其性能。 同样,将共享数据的线程分开放置可能会导致争用,尤其是如果线程被调度到不同的NUMA节点时。
Thread scheduling is handled by the underlying operating system. However, as OS does not take into account applications’ specific needs, it often makes sub-optimal decisions in scheduling threads into CPU cores. Therefore, it’s programmers’ job to give scheduling guidance to the OS on where threads should be scheduled. Now, let’s take a look at an example to see how sub-optimal scheduling can cause resource contention and how we can give scheduling guidance to resolve the problem:
线程调度由底层操作系统处理。 但是,由于OS并未考虑应用程序的特定需求,因此在将线程调度到CPU内核中时通常会做出次优决定。 因此,程序员的工作是向OS提供有关应该在何处调度线程的调度指导。 现在,让我们看一个示例,以了解次优调度如何导致资源争用以及如何提供调度指南来解决该问题:
In this example, we make use of the padded_atomic_int struct and update function in the previous section (Using padded_atomic_int ensures that our benchmark result eliminates the influence of false sharing between a and b). Threads t0 and t1 compete for padded_atomic_int a, while threads t2 and t3 compete for padded_atomic_int b. Here is the execution time for sub-optimal thread scheduling using GoogleBenchmark:
在此示例中,我们使用了上一节中的padded_atomic_int结构和更新函数(使用padded_atomic_int确保我们的基准测试结果消除了a和b之间错误共享的影响)。 线程t0和t1争夺padded_atomic_int a,而线程t2和t3争夺papped_atomic_int b。 这是使用GoogleBenchmark进行次优线程调度的执行时间:

In this case, we’re expecting heavy contention on two cache lines which contain padded_atomic_int a and b. Let’s useand to verify this expectation:
在这种情况下,我们期望两个包含padded_atomic_int a和b的缓存行发生激烈争用。 让我们使用和来验证这种期望:

Indeed, two cache lines that contain padded_atomic_int a and b are under heavy contention. Notice the term “HITM”, which stands for a load that hit in a modified cache line [1], is significantly high in both 0x7fffe9eef040 and 0x7fffe9eef080 cache line, which indicates the existence of false sharing for variable a and b. Remember that false sharing only occurs if two are more threads, which are scheduled into different cores, fight for exclusive access to a cache line so they can write to it. Therefore, an intuitive solution for this problem is to schedule the threads that want to access shared data into one core so that false sharing can be eliminated.
确实,包含padded_atomic_int a和b的两条高速缓存行处于激烈竞争中。 请注意,术语“ HITM”代表在修改的高速缓存行[1]中命中的负载,在0x7fffe9eef040和0x7fffe9eef080高速缓存行中都很高,这表明存在变量a和b的错误共享。 请记住,只有两个以上的线程(调度到不同的内核)争夺对缓存行的独占访问权,以便它们可以写入时,才会发生错误共享。 因此,针对此问题的一种直观解决方案是将要访问共享数据的线程调度到一个内核中,以便可以消除错误共享。
From C++11 and onwards, thread affinity is supported withpinning chosen threads to a single core using attribute objects. Here’s how the optimal thread scheduling implementation would look like:
从C ++ 11开始, 支持线程相似性使用属性对象将所选线程固定到单个核心。 最佳线程调度实现如下所示:
In order to make this code understandable, let’s go over the new data structures and functions and explain what their jobs are in our code. First, data structure represents a set of CPUs (physical cores, not threads). In line 5 and 6, we define two variables, each contains a separate set of CPUs, each of which specifies the CPUs that a thread can be scheduled to. is a provided macro to operate on the CPU set s, telling the OS that, initially, our CPU set s does not contain any core. We then use to add core c to CPU set s in line 13 and 14. In our case, we add core 0 to cpu_set_1 and core 1 to cpu_set_2. After creating four threads in line 17, we create twovariables, denoting the thread attribute objects through which we can set the attributes to the CPU sets that consumed them (line 25, 30). A thread, then, can base on the attribute object that is passed to it to determine what CPU set it belongs to (line 26, 27, 31, 32). By doing this, we have given guidance to the underlying OS on what threads should be scheduled on what core. In our case, we schedule pairs of threads that share the same variable a or b to the same core: pin threads t0 and t1 to physical core 0, and threads t2 and t3 to physical core 1. This means that our pairs of threads can share the same copy of the cache line containing their respective padded_atomic_int variable instead of trying to take it away from each other. Let’s check our execution time.
为了使该代码易于理解,让我们研究一下新的数据结构和函数,并解释它们在我们的代码中的作用。 首先, 数据结构表示一组CPU(物理内核,而不是线程)。 在第5行和第6行中,我们定义了两个变量,每个变量包含一组单独的CPU,每个变量指定可以将线程调度到的CPU。 是提供的宏,用于在CPU集s上运行,告诉操作系统,最初,我们的CPU集s不包含任何内核。 然后我们使用在第13和14行中将核心c添加到CPU集s。在本例中,我们将核心0添加到cpu_set_1并将核心1添加到cpu_set_2。 在第17行中创建了四个线程之后,我们创建了两个变量,表示线程属性对象,通过这些变量我们可以将属性设置为消耗它们的CPU集(第25、30行)。 然后,线程可以基于传递给它的属性对象来确定其所属的CPU集(第26、27、31、32行)。 通过这样做,我们为底层操作系统提供了有关应该在哪个内核上调度哪些线程的指导。 在我们的示例中,我们计划将共享相同变量a或b的线程对分配给同一核:将线程t0和t1分配给物理核心0,将线程t2和t3分配给物理核心1。这意味着我们的线程对可以共享包含它们各自的padded_atomic_int变量的缓存行的同一副本,而不是尝试使它们彼此分开。 让我们检查一下执行时间。

Over 3x speed up when we schedule the threads ourselves! Let’s have a look at the L1 hit rate:
当我们自己调度线程时,速度提高了3倍以上! 让我们来看看L1的命中率:

Now, very few L1 misses! This is because our pairs of threads are no longer invalidating each other.
现在,很少有L1错过! 这是因为我们的线程对不再彼此无效。
五,线程池 (V. Thread Pool)
In the previous two sections, we have dealt with situations that we know beforehand the number of threads needed for our program execution. However, in many scenarios, choosing how many threads a program should use is not trivial. Assuming that your application is a server that listens to certain URL ports. Whenever that server receives a request through these ports, it spawns a new thread to process this request, and by doing this, we are able to process these requests in an asynchronous and parallel manner.
在前两节中,我们处理了预先知道程序执行所需线程数的情况。 但是,在许多情况下,选择程序应使用多少个线程并非易事。 假设您的应用程序是一个侦听某些URL端口的服务器。 只要该服务器通过这些端口接收到请求,它就会生成一个新线程来处理此请求,并且通过执行此操作,我们能够以异步和并行的方式处理这些请求。
However, there are a couple of problems with this approach. One of them is that the server could end up creating too many threads, which can make the system slow. In particular, using too many threads can seriously “degrade program performance” as each thread is only “given too little work” with limited hardware resources”, while “the overhead of starting and terminating threads swamps the useful work” [2]. A simple solution to this designing pattern is to specify ahead of time the maximum amount of the number of threads to use. Sadly, as there seem to be no definitive rules to choose the right number for the number of threads for a program, the best thing to do is just take an informed guess, measure CPU usage & program performance, and repeat.
但是,这种方法存在两个问题。 其中之一是服务器最终可能会创建过多的线程,这可能会使系统变慢。 特别是,使用过多的线程会严重“降低程序性能”,因为每个线程仅在有限的硬件资源下“仅提供了很少的工作”,而“启动和终止线程的开销却淹没了有用的工作” [2]。 此设计模式的简单解决方案是提前指定要使用的最大线程数。 可悲的是,由于似乎没有确定的规则来为程序的线程数选择正确的数字,因此最好的办法就是做出明智的猜测,衡量CPU使用率和程序性能,然后重复执行。
After choosing the right number of threads to efficiently handle execution workloads, we can use thread pool, a software design pattern for concurrent systems. If a program uses thread pool, it starts by creating a set of threads even if there is no work for them to do. In our case, the number of threads equals the right amount of threads that we have chosen previously. The threads will wait in the pool until there is work to do. When the server receives a work request, it routes that request to the pool, and the pool will assign it to an available thread or put it in the pool queue until a thread becomes available. Here’s an abstracted diagram for a thread pool pattern:
选择正确数量的线程以有效处理执行工作负载后,我们可以使用线程池,这是用于并发系统的软件设计模式。 如果程序使用线程池,则即使没有工作要做,它也会从创建一组线程开始。 在我们的例子中,线程数等于我们先前选择的正确线程数。 线程将在池中等待直到有工作要做。 服务器收到工作请求后,会将请求路由到池中,并且池会将其分配给可用线程,或将其放入池队列中,直到线程可用为止。 这是线程池模式的抽象图:
While our server plays its part as one of the producers, threads created by thread pool act as consumers, or workers, that process the requests sent from the customers to the job queue. Thread pool is a fairly simple software design, but it provides a lot of flexibility and modularity for our codebase as it can be implemented, deployed, and maintained as a completely separated service. It also provides a convenient means of bounding and managing hardware resources for the threads.
当我们的服务器作为生产者之一发挥作用时,线程池创建的线程充当使用者或工作者,它们处理从客户发送到作业队列的请求。 线程池是一个相当简单的软件设计,但是它可以为我们的代码库提供很多灵活性和模块化,因为它可以作为完全独立的服务来实现,部署和维护。 它还为绑定和管理线程的硬件资源提供了一种方便的方法。
For C++ implementation of thread pool, readers can refer to this Github repo by Jakob Progsch, chapter 9 of C++ Concurrency in Action by Anthony D. Williams[3], or chapter 12 of Optimized C++ by Kurt Guntheroth [4] for more details.
对于C ++实现线程池,读者可以参考该Github上回购由雅各布Progsch,由Anthony D.威廉姆斯[3],或第12章优化的C ++通过库尔特Guntheroth [4]更多细节C ++中的并发操作的第9章。
VI。 参考文献 (VI. References)
[1] Joe Mario. C2C — False Sharing Detection in Linux Perf. My Octopress Blog, 01 Sep. 2016, https://joemario.github.io/blog/2016/09/01/c2c-blog/.
[1] Joe Mario。 C2C — Linux性能中的错误共享检测。 我的Octopress博客,2016年9月1日, https: //joemario.github.io/blog/2016/09/01/c2c-blog/。
[2] Shameem Akhter and Jason Roberts. Avoiding Classic Threading Problems. Dr. Dobb’s, 06 Jun. 2011, https://www.drdobbs.com/tools/avoiding-classic-threading-problems/231000499.
[2] Shameem Akhter和Jason Roberts。 避免经典线程问题。 Dobb博士,2011年6月6日,
来源:weixin_26746861
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!