磁共振成像初学者必看
- 一、浅谈功能脑网络
- 二、不同模态脑网络的构建
-
- 功能脑网络
- 结构脑网络
- 白质纤维束脑网络
- 加权网络
- 二值网络
- 三、趣谈散点图与相关系数
- 四、脑电信号频域变换
- 五、fMRI中的FDR校正
- 六、模板(mask)
-
- 1、模板(mask )往往是与ROI联系在一起的
- 2、mask作用的原理
- 3、常见的mask
- 七、假设检验和效果量
- 八、组水平标准化
- 九、由 ALFF 说开去
- 十、计算机存取MRI影像的那些事
- 十二、Linux基础命令
- 十三、浅谈标准空间模板和空间变换
-
- 一:标准空间模板
- 二:空间变换
- 十四 、 功能连接
- 十五、大脑激活与功能连接的联系
- 十六、浅谈小世界网络
- 十七、 独立成分分析
- 十八、广义线性模型GLM(上)
- 十九、Block 还是Event—来自任务态数据处理的逆思路答案
- 二十、Block 还是Event来自任务态数据处理的逆思路答案(下)
- 二十一、浅谈影像组学
-
- 1 影像数据获取
- 2 肿瘤分割
- 3 影像特征的提取
- 4 数据挖掘分析
-
- 4.1 特征筛选(降维)
- 4.2 模型建立:分类、预测
- 5 辅助诊断
- 二十二、任务态分析方法总汇——你还停留在单变量的激活时代吗/li>
一、浅谈功能脑网络
首先,甲学员从他人那里获取了每个脑区的信号序列。其次,计算任意两个信号序列间的相关(皮尔逊相关)。这样,把脑区视为节点,相关值视为边,功能网络就构建好啦!
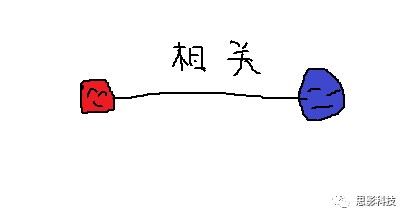

这样,包含两个节点(红色脑区和蓝色脑区)和一个连边的最小“脑网络”已经构建好了。当我们把任意两个脑区信号序列的相关计算出来后,一个完整的脑网络就计算好了!
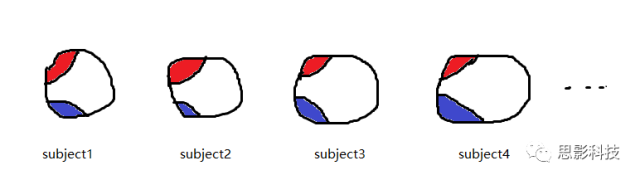
(只不过把time points换成了subject)
“你看,功能脑网络既然你已经会了,现在看一下结构脑网络。“
-
假定我们有100名被试,并计算出了红色脑区和蓝色脑区的平均灰质密度值(GMV),得到了100个红区的GMV和100个蓝区的GMV。
-
同样地,把红区的100个GMV值和蓝区的100个GMV值做相关,就得到了红区和蓝区的相关值,也就是红区和蓝区的连边。
-
当我们把所有脑区间的GMV相关计算出来后,就得到了所谓的结构共变脑网络。只不过,这个脑网络一组被试才能构建一个
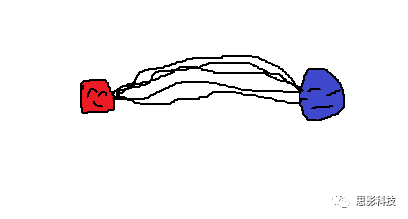
(红蓝脑区间追踪出了5条纤维束,依然是荡漾的画风)
现在看一下白质纤维束脑网络。首先,基于DTI成像,使用纤维追踪技术(以确定性纤维追踪为例)可以追踪出两个脑区间的纤维束。”
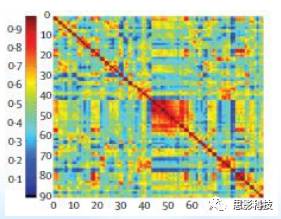
(加权脑网络的邻接矩阵表示)
“至此,你已经知道了4种脑网络构建方式。这里我再补充一个概念:加权网络和二值网络。每个脑网络都可以表示为邻接矩阵的形式,参考上图,横轴和纵轴都是脑区编号,横纵交叉的地方就是相应脑区间的连接值(颜色随连接值大小变化),这种网络就是加权网络。”
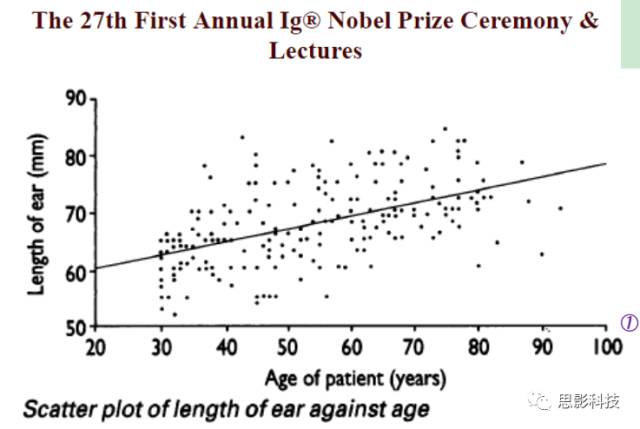
图1:Ref: JamesAH, BMJ, 1995, 311: 1668.
有一个人,他测量了一组人的“量表”。其中这个“量表”包含着年龄和耳朵长度。这样子他就得到一个二维小表格如下图示:
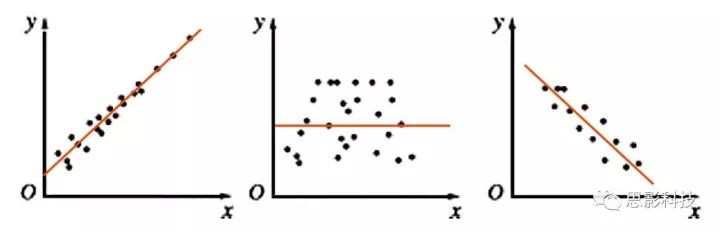
图3:散点图与拟合线(橙色),左:正相关;中:不相关;右:负相关
其实我告诉你,现在这根橙色拟合线的趋势就是相关性。如果这根线是朝着右上角走,就是正相关;如果这根线是朝着右下角走,就是负相关;如果这根线水平,就代表着不相关。
但是理想很美好,现实很残酷。真正拿到数据进行计算相关系数,多多少少会存在一定的相关性,真正不相关的例子太少太少。前一阵子有一篇文章说:中国三峡大坝是影响日本地震的原因。该文说这个相关性还是非常非常显著的。
那么问题来了:相关系数的计算怎么会有显著性呢/p>
多图警示!
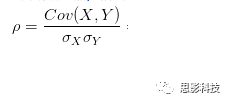
其中:
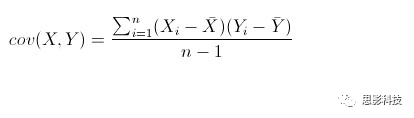
皮尔逊相关ρ,协方差Cov(x,y),标准差σx σy
注:在公式内并无显著性水平计算,显著性解释是作者领悟的。在matlab中,计算相关系数是有显著性输出的。此显著性并未通过多重比较较正。有关校正,敬请看后面推送。
现在说了这么多,让我来告诉你,一些在脑科学领域用散点图来解释的本质:
1、功能连接:功能连接最早的定义就是皮尔逊相关,而功能连接就是两个脑区时间点的散点图
2、结构上的协变连接:协变连接是用得最早的,在磁共振出现之前,前人研究PET就是采用协变连接。简单说,就是A、B两个脑区之间的散点图。
3、回归:有没有发现回归也是这样子的/p>
四、脑电信号频域变换
脑电信号频域变换的原理
在脑电数据处理中,我们经常要做信号的时、频域变换。许多初学者已经做过一些时、频域分析,但是仍然对时、频域信号没有一个直观的理解。那么,究竟什么是时域信号么又是频域信号呢/p>
首先,理解时域信号很简单。时域信号是什么是以时间为横轴,数据值为纵轴的信号呀。比如这样的:
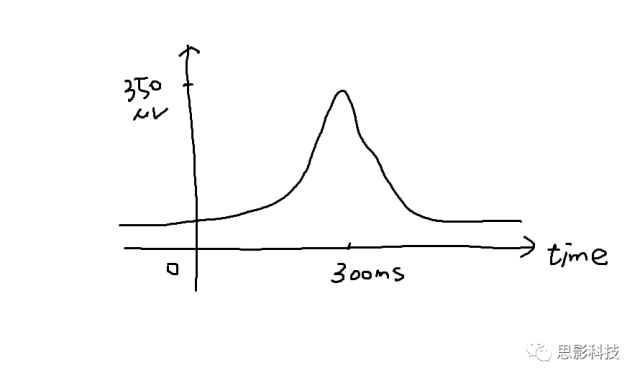
在事件(0秒处)发生的300ms后,有一个正的波形,这个可能就是P300成分(Positive, 300ms)。我们把300ms称为潜伏期,波形的高度,即350uV,称为幅值。
其实,在现实世界中,我们收集到的各种各样的数据,大都是时域信号。直到一位大神出现,他就是傅里叶!
傅大神发现了什么呢发现周期函数,像下图这样的,都可以用一系列的正弦(和余弦)波叠加近似地表示出来。想象一下,一个方波,它可以由一个大波浪,加一个小波浪,加一个小小波浪,加一个小小小波浪。这样表达出来!如下图所示。
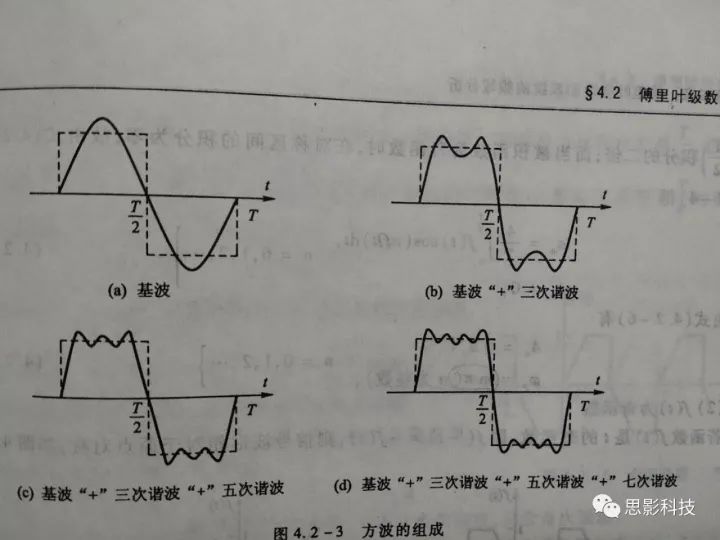
而且,不仅仅是方波,任何周期函数,像下图这样的,都可以用一系列(无限个)的正弦和余弦波来叠加表示。
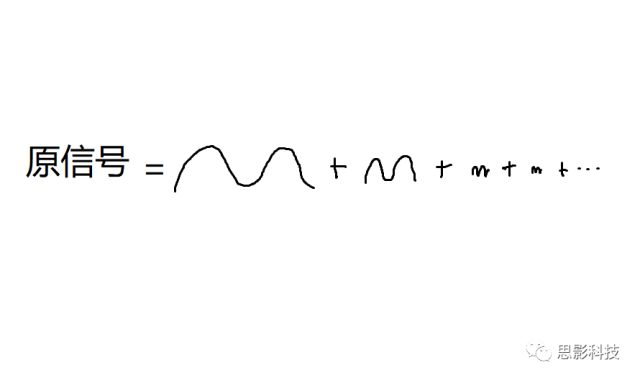
我们在中学数学中已经学习到,一个正弦(余弦)波,可以由频率、幅值、相位三者来决定
所谓频率,就是1秒内,这个波形走了几个周期;所谓幅值,就是波形的高度;所谓相位,就是在0时刻时,波形走到了一个周期的哪个进度。所以,现在,我们知道原信号可以由一系列不同频率的正弦(余弦)波来构成,如下图:
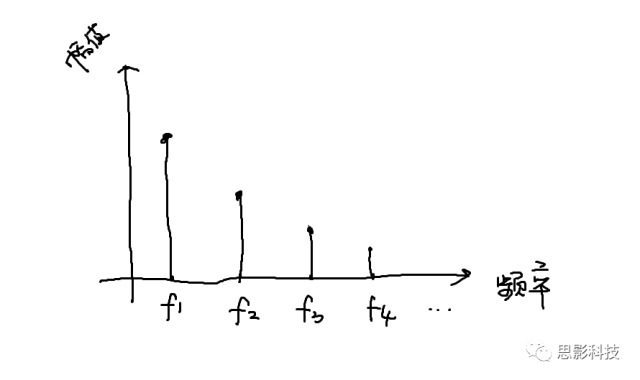
然而呢,大部分信号都是非周期信号,非周期信号的傅里叶变换如何呢要着急,傅大爷也给出了答案。
非周期信号由于没有周期,所以把原信号做傅里叶变换后,在频域上,需要用到所有频率(而不是特定的一些频率点)才能把原信号表示出来。
更进一步,现实中我们能采集到的信号都是有限非周期离散信号,于是又有人基于离散傅里叶变换提出了FFT(快速傅里叶变换)算法,可以把我们采集到的离散信号近似地表示成一系列频率点(不超过采样率的一半)的波形的集合。所以,现在我们明白了,所谓的频域信号,就是把原信号以频率为横轴表示出来。
在对每个通道的信号做了频域变换后,我们就可以考察特定频率或者频率带上的信息了。正是由于我们发现不同频率带上脑电信号的幅值在特定环境下会产生相应变化,我们才定义了Alpha波(813Hz)、Beta波(1330Hz)等脑电波段,到这里,整个过程是不是很熟悉了/p>
有关快速傅里叶的讲解:https://blog.csdn.net/enjoy_pascal/article/details/81478582
五、fMRI中的FDR校正
当我们招完被试,收完数据,做完预处理,统计,过五关斩六将,认为自己马上将要发SCI,走上人生巅峰的时候,不好意思,你还需要面对最残酷无情的对手:多重比较校正,比如FDR校正。
先解释一些概念:以任务态数据为例,先看一个体素。那么原假设(H0):该体素没有激活。从原假设基础上进行统计推断,得到P=0.02 < 0.05。所以我们拒绝原假设,然后推断出该体素激活。请注意:我们推断的这个结果有可能是错的,也就是说有可能错误地拒绝了原假设。这种犯错误的概率称之为假阳性率。这个例子里面假阳性率=2%,也就是说该体素激活的这种推断有2%的概率是错的。我们一般显著性水平设置为P=0.05。那么在1000次假设检验中,假阳性的结果就有1000*0.05=50次。我们希望的是假阳性是越少越好,所以要对假阳性进行校正。这个过程就称之为多重比较校正。
那什么是FDR校正呢/p>
先解释三个指标: Vaa,Via, Da=Vaa+Via。这个三个指标表示的是在V(比如这里V指体素个数)次测试中,它们各自出现了多少次。Vaa表示该体素本来就应该激活(Truly active),我们进行统计推断发现它确实激活了(Declared active)。Via表示该体素本来不应该激活(Truly inactive),我们进行统计推断发现它居然激活了(Declared active)。Da表示我们发现的激活的体素的个数。从上面可以看出,Vaa是我们想要的结果,而Via不是我们想要的结果(这里Via就是假阳性次数),因此我们要控制Via出现的次数。FDR公式如下:

FDR校正的是在检测出的激活的体素中(Da),伪激活(假阳性)的体素的个数(Via)。这里要注意和FWE校正的区别。FWE校正的是在所有被检测的体素中,假阳性体素的个数。
最后举个例子:假设大脑总共有50000个体素(V=50000),通过假设检验发现有20000个体素的P<0.05,也就是说Da=20000。FDR和FWE的校正水平都设为0.05。那么FDR说的是在20000个激活的体素中,假阳性的体素不超过20000*0.05=1000个。FWE说的是在总共50000个体素中(包括检测到的激活的体素和不激活的体素),假阳性的体素不超过50000*0.05=2500个。FWE比FDR严格,是因为FWE控制的是全脑中假阳性次数,FDR控制的是我们发现的激活(Declared active)的体素中假阳性次数。
总结起来就三句话:
(1)当同一个数据集有n次(n>=2)假设检验时,要做多重假设检验校正
(2)对于Bonferroni校正,是将p-value的cutoff除以n做校正,这样差异基因筛选的p-value cutoff就更小了,从而使得结果更加严谨
(3)FDR校正是对每个p-value做校正,转换为q-value。q=p*n/rank,其中rank是指p-value从小到大排序后的次序。举一个具体的实例:
我们测量了M个基因在A,B,C,D,E一共5个时间点的表达量,求其中的差异基因,具体做法:
(1)首先做ANOVA,确定这M个基因中有哪些基因至少出现过差异
(2)5个时间点之间两两比较,一共比较5*4/2=10次,则多重假设检验的n=10
(3)每个基因做完10次假设检验后都有10个p-value,做多重假设检验校正(n=10),得到q-value
(4)根据q-value判断在哪两组之间存在差异通过T检验等统计学方法对每个蛋白进行P值的计算。T检验是差异蛋白表达检测中常用的统计学方法,通过合并样本间可变的数据,来评价某一个蛋白在两个样本中是否有差异表达。
但是由于通常样本量较少,从而对总体方差的估计不很准确,所以T检验的检验效能会降低,并且如果多次使用T检验会显著增加假阳性的次数。
例如,当某个蛋白的p值小于0.05(5%)时,我们通常认为这个蛋白在两个样本中的表达是有差异的。但是仍旧有5%的概率,这个蛋白并不是差异蛋白。那么我们就错误地否认了原假设(在两个样本中没有差异表达),导致了假阳性的产生(犯错的概率为5%)。
如果检验一次,犯错的概率是5%;检测10000次,犯错的次数就是500次,即额外多出了500次差异的结论(即使实际没有差异)。为了控制假阳性的次数,于是我们需要对p值进行多重检验校正,提高阈值。方法一.Bonferroni
“最简单严厉的方法”
例如,如果检验1000次,我们就将阈值设定为5%/ 1000 = 0.00005;即使检验1000次,犯错误的概率还是保持在N×1000 = 5%。最终使得预期犯错误的次数不到1次,抹杀了一切假阳性的概率。
该方法虽然简单,但是检验过于严格,导致最后找不到显著表达的蛋白(假阴性)。方法二.FalseDiscovery Rate
“比较温和的方法校正P值”
FDR(假阳性率)错误控制法是Benjamini于1995年提出的一种方法,基本原理是通过控制FDR值来决定P值的值域。相对Bonferroni来说,FDR用比较温和的方法对p值进行了校正。其试图在假阳性和假阴性间达到平衡,将假/真阳性比例控制到一定范围之内。例如,如果检验1000次,我们设定的阈值为0.05(5%),那么无论我们得到多少个差异蛋白,这些差异蛋白出现假阳性的概率保持在5%之内,这就叫FDR<5%。
那么我们怎么从p value 来估算FDR呢,人们设计了几种不同的估算模型。其中使用最多的是Benjamini and Hochberg方法,简称BH法。虽然这个估算公式并不够完美,但是也能解决大部分的问题,主要还是简单好用!FDR的计算方法
除了可以使用excel的BH计算方法外,对于较大的数据,我们推荐使用R命令p.adjust。
1.我们将一系列p值、校正方法(BH)以及所有p值的个数(length§)输入到p.adjust函数中。
2.将一系列的p值按照从大到小排序,然后利用下述公式计算每个p值所对应的FDR值。
公式:p * (n/i), p是这一次检验的pvalue,n是检验的次数,i是排序后的位置ID(如最大的P值的i值肯定为n,第二大则是n-1,依次至最小为1)。
3.将计算出来的FDR值赋予给排序后的p值,如果某一个p值所对应的FDR值大于前一位p值(排序的前一位)所对应的FDR值,则放弃公式计算出来的FDR值,选用与它前一位相同的值。因此会产生连续相同FDR值的现象;反之则保留计算的FDR值。
4. 将FDR值按照最初始的p值的顺序进行重新排序,返回结果。
最后我们就可以使用校正后的P值进行后续的分析了。https://blog.csdn.net/zhu_si_tao/article/details/71077703
六、模板(mask)
在这里笔者讲述下mask,与mask使用的技巧与原则。
mask是谁,mask要做什么/p>
1、模板(mask )往往是与ROI联系在一起的
(region of interest感兴趣区,如果你一定要问我感兴趣区是什么,我觉得我们不在一个频道上,放手吧,我们俩是不可能的)
在小时候填写机答题卡的时候,老师改卷就是在正确答案上面挖洞,然后数个数。如图1示。
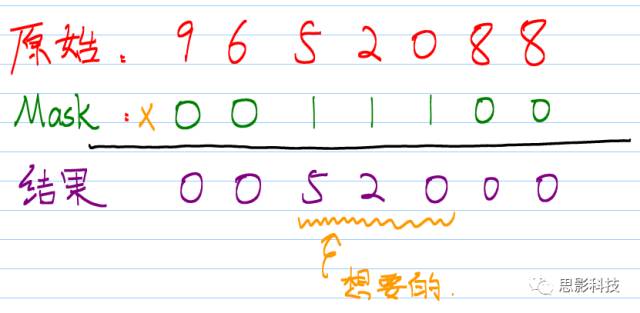
图2:mask在计算中处理的机理
这样就把感兴趣的区域信号“520” 提取出来了。
3、常见的mask
根据我们使用的需要,把mask做成:二值模板、多值模板、概率模板。
1)二值模板:
二值模板就是简单的卡一个阈值,白色的区域置为数字1,黑色区域设置为数字0。得到的区域就是我们想要得到的我们所感兴趣的区域。如果需要研究大脑灰质,则把白质、脑脊液与大脑外的区域滤除即可
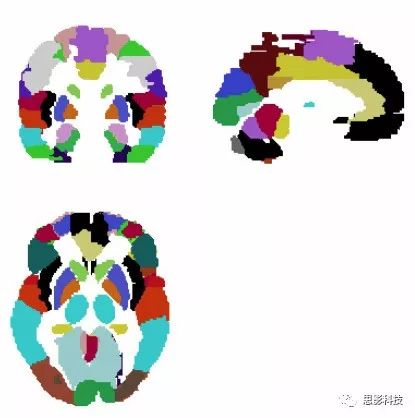
图4:AAL模板
如图4展现的AAL模板,每一个颜色的区块代表一个不同的区域。不同颜色代表一个不同的数字。然后特定数字对应特定脑区。
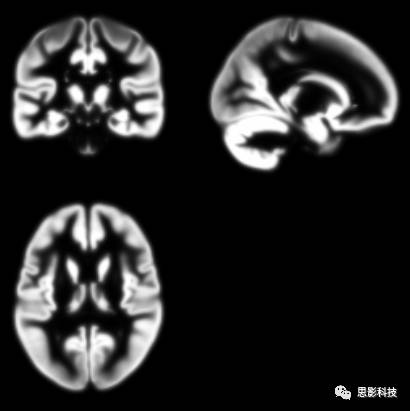
图6:灰质概率模板
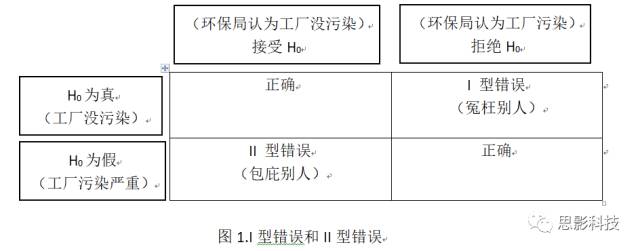
上面图表有两种正确的结果。一是工厂没污染,环保局鉴定过后确实没污染;二是工厂有污染,环保局鉴定后确实污染。这两种结果无需过多关注。我们更感兴趣的是I型错误和II型错误。
那么哪种错误更严重于环保局来说,肯定不能冤枉别人,所以应考虑控制I型错误。II型错误的后果是:工厂继续污染,没有得到惩罚,周围百姓继续忍受污染。对于周围百姓来讲,要控制II型错误。那么一个理想的方案是把I和II型错误都控制很小,然而现实是不可能的!!!!!比如要把P控制在P<0.0000000000001,这样我们才拒绝H0(非常小心求证)。那么要找1000条污染证据才能让P达到这样小。但事实上,结果我们只找到20条证据,这时候自己都会对自己说:证据这么少,这个工厂应该没有污染吧!看,II型错误显著上升了。那么有没有办法在其他条件一定的情况下,降低II型错误呢唯一的办法就是增加样本量(样本量增多,就有可能找到更多的证据)!!
下面介绍Power。Power=1 – II型错误。II型错误是工厂确实污染,环保局认为没污染。那么Power就是工厂确实污染,环保局认为工厂也污染(正确打击了这种危害性工厂)。所以Power指的是对真实存在的差异正确检测出来的能力。Power越大说明检测差异的能力越大。一种统计方法,即使差异再小,它都能把该差异检测出来,就说该统计方法的Power很大。比如比较两组人的ALFF,如果该统计方法的power=0.8,就是说10个脑区有真实差异,我就能检测出来8个。
下面介绍效果量。
当我们辛辛苦苦收集完数据,统计结果也显著(P值那是相当小),觉得非常perfect的时候,突然审稿人来了一句:请报一下研究的效果量!。你不觉会问:这是什么东东/p>
效果量,英文名为effectsize。假设对两组数据的均数差异进行统计推断,会得到统计值T值和P值,如果P<0.05,那么就说该差异显著。问题是这样的显著性差异在实际中有没有用计推断会受样本影响。比如调查男女身高的差异,在重庆收集了一批样本,发现男性身高显著高于女性。那么这种结论能否推广到其它城市然不能。统计推断还会受样本大小的影响。比如研究某治疗方法对治疗抑郁症是否有效,实际结果是实验组比控制组平均高4分,两组人数都是12人,标准差都是8。可以计算P>0.05,不显著。但当两组的人数增加到100(均数差异和标准差不变),差异极其显著。而下结论说该治疗方法有显著效果是不令人信服的。也就是说通过增大样本量达到的统计显著可能并没有实际效果。如果P值很小,但是效果量也很小,就说明即使该治疗方法效果显著,但并不能在实际当中使用。只有那种P值小,效果量也大的治疗方法才能推广使用。
所以效果量反应的是该差异在实际上是否“显著”(不受样本容量大小的影响),而**P值只反应该差异在统计上是否显著。**比如对于男女人数的显著差异(假设男人数>女人数),如果效果量大,表明随便往哪条大街上一站,就能看到男人多于女人。如果效果量很小,那么男人多于女人这种现象可能只限于某局部区域(如某某理工类高校!!!)。正因为效果量重要,所以美国心理学会1994年就发出通知,要求公开发表的研究报告需包含效果量的测定结果。
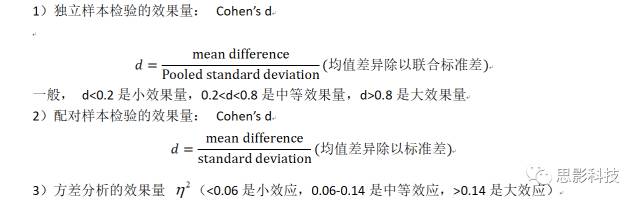
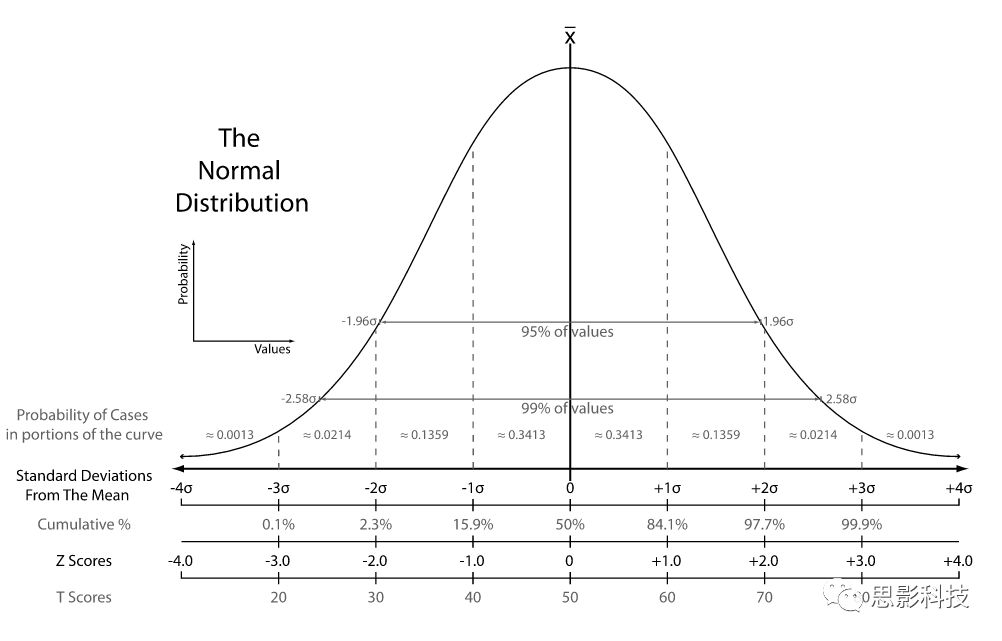
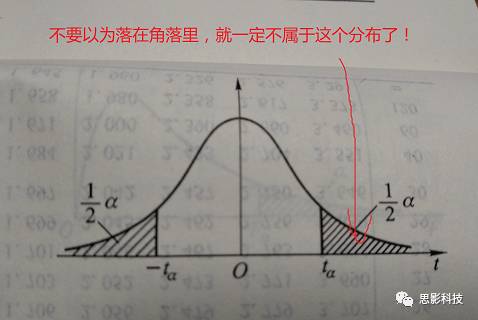
图1:标准正态分布图(from Wikipedia)
注:
Z-score的数学定义:
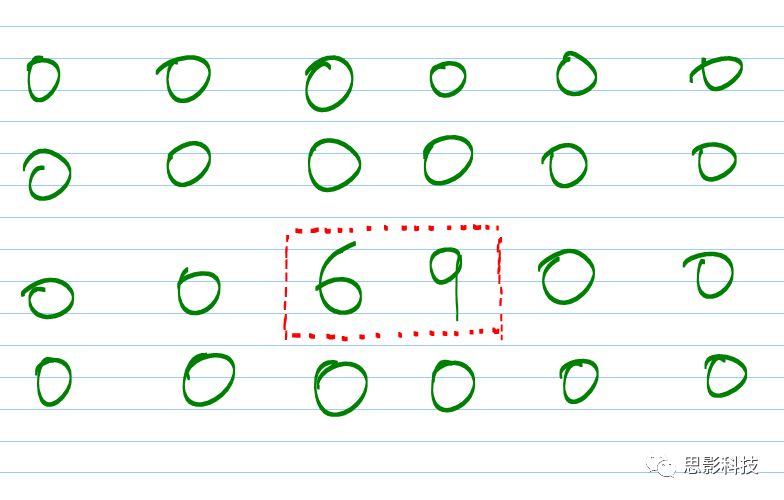
图2:极端化的大脑区域与外界区域
(2)Z-score 与 Fisher-Z 的区别
很多人在Z-score 与 Fisher’s z 变换上面傻傻分不清楚,包括某些文章上面所得到的结果就是错误的。因为某些文章把Z变换用成了fisher z。Z-score 与Fisher-Z其实没有任何联系,没有任何联系,没有任何联系。只不过名称相似,又常常同时在磁共振数据处理中使用,难免混淆。Z-score,又称Z分数化,“大Z变换”,Fisher-z,又称Fisher z-transformation,“小z变换”。
Fisher’s z 变换,主要用于皮尔逊相关系数的非线性修正上面。因为普通皮尔逊相关系数在0-1上并不服从正态分布,相关系数的绝对值越趋近1时,概率变得非常非常小。相关系数的分布非常像断了两头的正态分布。所以需要通过Fisherz-transformation对皮尔逊相关系数进行修正,使得满足正态分布。
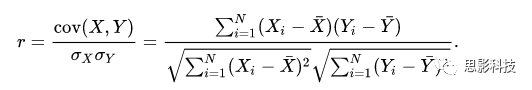
fisher‘s z transformation:
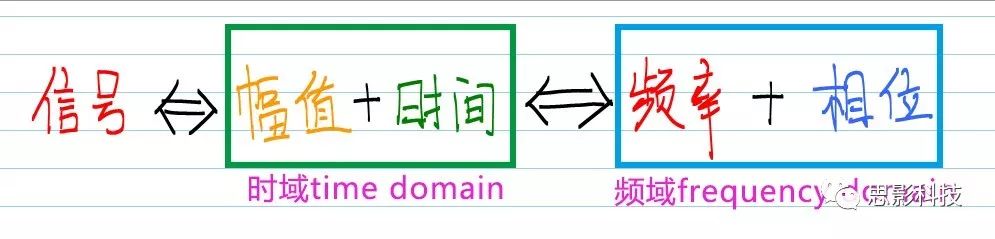
图1:信号,时域,频域公式
频域方面的计算永远不是脑电的代名词,相反,我们往往可以师夷长技以制夷。更换一种看问题的角度往往能够更好探究人脑的内部机制。例如把脑电的相关知识运用在磁共振脑成像领域中。当然在运用的时候需要严格把关底层的原理,否则就容易做成了四不像。本文最后提供部分频域方面的参考文献。
理解上面这个图,频域方面就可以PASS了。
小目标2:什么是ALFF/strong>
ALFF的全称: Amplitude of Low Frequency Fluctuations(低频振幅)
笔者找到推广ALFF的第一篇文章,截了一个图,并稍微做了些修改,为了方便理解把它分成了好几个大块。(记住这个图,后面的大话脑成像系列笔者还会再拿这张图说其他事 _)
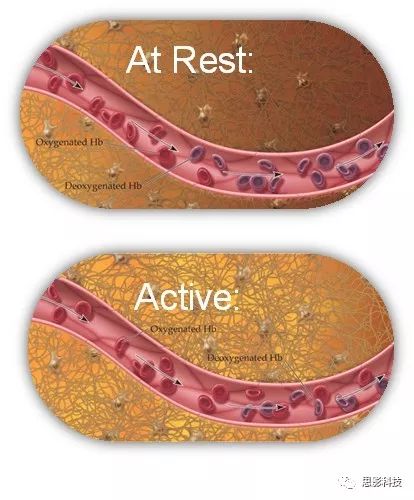
图3:BOLD机制
比较AL
来源:sta@ma@brain
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!