MySQL分区表概述
我们经常遇到一张表里面保存了上亿甚至过十亿的记录,这些表里面保存了大量的历史记录。 对于这些历史数据的清理是一个非常头疼事情,由于所有的数据都一个普通的表里。所以只能是启用一个或多个带where条件的delete语句去删除(一般where条件是时间)。 这对数据库的造成了很大压力。即使我们把这些删除了,但底层的数据文件并没有变小。面对这类问题,最有效的方法就是在使用分区表。最常见的分区方法就是按照时间进行分区。
分区一个最大的优点就是可以非常高效的进行历史数据的清理。
1. 确认MySQL服务器是否支持分区表
命令:
show plugins;

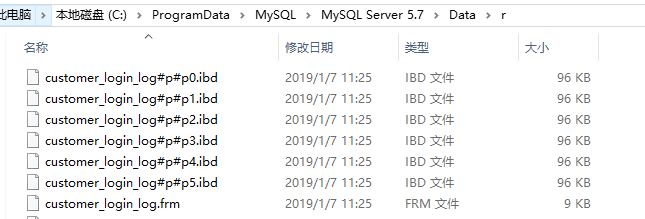
使用起来和不分区是一样的,看起来只有一个数据库,其实有多个分区文件,比如我们要插入一条数据,不需要指定分区,MySQL会自动帮我们处理
范围分区(RANGE)
RANGE分区特点
根据分区键值的范围把数据行存储到表的不同分区中
多个分区的范围要连续,但是不能重叠
默认情况下使用VALUES LESS THAN属性,即每个分区不包括指定的那个值
如何建立RANGE分区

如果插入一条login_type为10的数据行,则会报错
3. 如何为登录日志表(customer_login_log)分区
业务场景
用户每次登录都会记录customer_login_log日志
用户登录日志保存一年,1年后可以删除或者归档
登录日志表的分区类型及分区键
使用RANGE分区
以login_time为分区键
分区后的用户登录日志表
按年份分区存储,所以用YEAR函数进行了转化
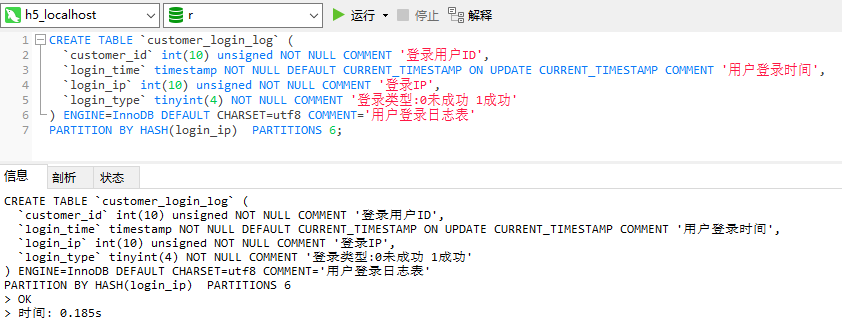
CREATE TABLE `customer_login_log` (
`customer_id` int(10) unsigned NOT NULL COMMENT ‘登录用户ID’,
`login_time` DATETIME NOT NULL COMMENT ‘用户登录时间’,
`login_ip` int(10) unsigned NOT NULL COMMENT ‘登录IP’,
`login_type` tinyint(4) NOT NULL COMMENT ‘登录类型:0未成功 1成功’
) ENGINE=InnoDB
PARTITION BY RANGE (YEAR(login_time))(
PARTITION p0 VALUES LESS THAN (2017),
PARTITION p1 VALUES LESS THAN (2018),
PARTITION p2 VALUES LESS THAN (2019)
)
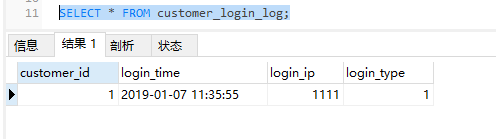
插入并查询数据

再插入2条18年的日志,会存入p2表中

我们可以通过下面语句
增加分区
ALTER TABLE customer_login_log ADD PARTITION (PARTITION p3 VALUES LESS THAN(2020))
增加分区,并插入数据
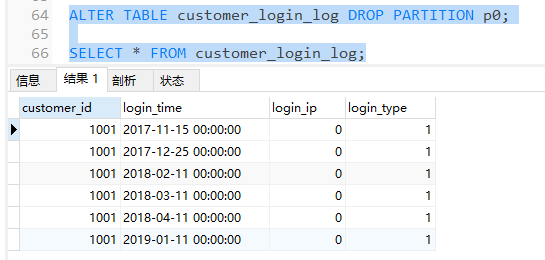
可以发现p0分区已被删除,且2016年的日志全部被清除了
归档分区历史数据
我们可能有另一种需求对数据进行归档
Mysql版本>=5.7,归档分区历史数据非常方便,提供了一个交换分区的方法
分区数据归档迁移条件:
MySQL>=5.7
结构相同
归档到的数据表一定要是非分区表
非临时表;不能有外键约束
归档引擎要是:archive
建表并交换分区
CREATE TABLE `arch_customer_login_log` (
`customer_id` INT unsigned NOT NULL COMMENT ‘登录用户ID’,
`login_time` DATETIME NOT NULL COMMENT ‘用户登录时间’,
`login_ip` INT unsigned NOT NULL COMMENT ‘登录IP’,
`login_type` TINYINT NOT NULL COMMENT ‘登录类型:0未成功 1成功’
) ENGINE=InnoDB ;
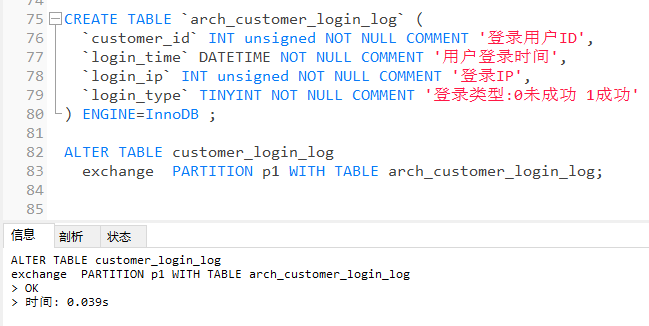
ALTER TABLE customer_login_log
exchange PARTITION p1 WITH TABLE arch_customer_login_log;
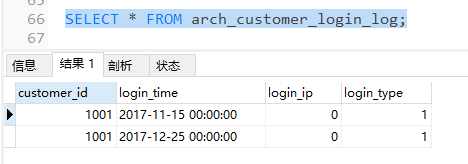
可以发现,原customer_login_log表中的2017年的数据(p1分区中的数据)已转移到了arch_customer_login_log表中,但是p1分区未删除,只是数据转移了,所以我们还需要执行DROP命令删除分区,以免有数据插入其中
将归档数据的存储引擎改为归档引擎
最后我们将归档数据的存储引擎改为归档引擎,命令为
ALTER TABLE customer_login_log ENGINE=ARCHIVE;
使用归档引擎的好处是:它比Innodb所占用的空间更少,但是归档引擎只能进行查询操作,不能进行写操作
4. 使用分区表的主要事项
结合业务场景选择分区键,避免跨分区查询
对分区表进行查询最好在WHERE从句中包含分区键
具有主键或唯一索引的表,主键或唯一索引必须是分区键的一部分(这也是为什么我们上面分区时去掉了主键登录日志id(login_id)的原因,不然就无法按照上面的按年份进行分区,所以分区表其实更适合在MyISAM引擎中)
关于MyISAM和Innodb的索引区别
1.关于自动增长
myisam引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
innodb引擎的自动增长咧必须是索引,如果是组合索引也必须是组合索引的第一列。
2.关于主键
myisam允许没有任何索引和主键的表存在,
myisam的索引都是保存行的地址。
innodb引擎如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见)
innodb的数据是主索引的一部分,附加索引保存的是主索引的值。
3.关于count()函数
myisam保存有表的总行数,如果select count(*) from table;会直接取出出该值
innodb没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre 条件后,myisam和innodb处理的方式都一样。
4.全文索引
myisam支持 FULLTEXT类型的全文索引
innodb不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。(sphinx 是一个开源软件,提供多种语言的API接口,可以优化mysql的各种查询)
5.delete from table
使用这条命令时,innodb不会从新建立表,而是一条一条的删除数据,在innodb上如果要清空保存有大量数据的表,最 好不要使用这个命令。(推荐使用truncate table,不过需要用户有drop此表的权限)
6.索引保存位置
myisam的索引以表名+.MYI文件分别保存。
innodb的索引和数据一起保存在表空间里。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对找一找教程网的支持。
文章知识点与官方知识档案匹配,可进一步学习相关知识MySQL入门技能树首页概览31359 人正在系统学习中 相关资源:spring boot整合mybatis利用Mysql实现主键UUID的方法
来源:吹狗螺的简柏承
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!