文章目录
- 写在最前
- 统计软件
-
- R&MATLAB
- SPSS
- SAS&STATA
- 表
- 数据科学软件的人气对比
-
- 摘要
- 介绍
- 招聘广告
- 学术文章
- 使用调查
- 图书
- 论坛活动
- 编程人气度量
- 销售和下载
- 比赛用途
- 能力增长
- 少了什么东西/li>
- 结论
- 致谢
- 参考书目
- 商标
- (2009.02)对比数据分析包:R Matlab SciPy Excel SAS SPASS Stata
写在最前
计量 数据科学 大数据 统计 软件
2018年AI及大数据处理发展速度实在太快了,我也对 大数据、机器学习、AI 、计量等内容做了些功课。也许翻译(谷歌翻译)的内容有些陈旧,但思路值得借鉴
这里面我要先提一句话大数据推动计量,计量需要大数据
文章范围真的不大好定义。先说为什么要写这个,有好事者提出:我们为什么用hadoop来分析数据,怎么不用spss或者stata,他们有什么区别。
回答:hadoop 分布式,开源(捂脸)
话说要做什么,必须先了解什么,了解->熟悉->掌握-会用。
了解:知道是什么。手机是什么能干什么
理解:不仅知道是什么,还要知其然,知其所以然,理解来龙去脉。为什么会有手机,怎么就能打电话呢。
会用:无需掌握原理,就像手机,会使用即可。
掌握:刨根问底、举一反三。不仅仅会用,还要掌握原理,可以熟练分析并应用解决问题。此处要引起重视。
哈哈哈哈,别笑!好吧,我们先了解
以下内容来源于几个链接地址的翻译整理(我仅做搬运工),非常精彩,感谢互联网
- The Popularity of Data Science Software
- Comparison of data analysis packages: R, Matlab, SciPy, Excel, SAS, SPSS, Stata
- STATISTICAL SOFTWARE
若涉及侵删,请邮件给我
值得一提的是 Robert A. Muenchen 在r4stats 上的 The Popularity of Data Science Software 真是大爱。
统计软件
几乎所有严肃的统计分析都在以下一个包中完成:R(S-PLUS),Matlab,SAS,SPSS和Stata。我对每个软件包都有专业知识,但这并不意味着每个软件包都适用于特定类型的分析。事实上,对于大多数高级领域,只有2-3个软件包是合适的,提供足够的功能或足够的工具来轻松实现此功能。例如,马尔可夫链蒙特卡罗的一个非常重要的区域仅适用于R,Matlab和SAS,除非您想依赖网络上随机用户编写的复杂宏。本页末尾的表格非常详细地比较了五个包。
R&MATLAB
R和Matlab是迄今为止最丰富的系统。它们包含令人印象深刻的插件库,每天都在增长。即使所需的特定模型不是标准功能的一部分,您也可以自己实现该模型,因为R和Matlab实际上是具有相对简单语法的编程语言。作为“语言”,它们允许您表达任何想法。问题是你是不是一个好作家。在现代应用统计工具方面,R库比Matlab更丰富。R也是免费的。另一方面,Matlab有更好的图形,你不会因为放入纸张或演示文稿而感到羞耻。
SPSS
另一方面是像SPSS这样的软件包。SPSS的功能非常狭窄,只允许您进行大约一半的主流统计。对于雄心勃勃的建模和估算程序来说,这是无用的,这些程序是内核平滑,模式识别或信号处理的一部分。尽管如此,SPSS在实践者中非常受欢迎,因为它几乎不需要任何培训。您只需点击几个按钮,SPSS就会为您完成所有计算。在那些需要标准的情况下,SPSS可能会完全实施。SPSS输出将非常详细,视觉上令人愉悦。它将包含与该方法相关的所有主要测试和诊断工具,并允许您编写实证分析的信息统计部分。简而言之,当方法存在时,它比R或Matlab中的类似功能运行得更快。所以我经常使用SPSS来满足客户的标准要求,比如线性回归,ANOVA或主成分分析。SPSS使您能够编程宏,但该功能非常不灵活。
SAS&STATA
在R,Matlab和SPSS之间的某个地方是SAS和Stata。SAS比Stata更广泛的分析。它由数十个程序组成,具有大量,大量的输出,通常覆盖十多页。SAS的想法不是那么听你的。它就像一个老祖父,你用一个简单的问题来接近他,但他告诉你他的生活故事。许多程序包含的内容比您需要知道的有关该细分的程序多三倍。所以必须花一些时间在相关输出中进行过滤。使用简单脚本调用SAS过程。可以通过单击菜单中的按钮或运行简单脚本来调用Stata过程。在菜单部分,Stata类似于SPSS。SAS和Stata都是编程语言,因此它们允许您围绕标准过程构建分析。Stata比SAS更灵活。尽管如此,就编程灵活性而言,Stata和SAS并不接近R或Matlab。与所有其他软件包相比,SAS的选择优势:大数据集,速度,漂亮的图形,格式化输出的灵活性,时间序列程序,计数过程。与所有其他软件包相比,Stata的选择优势:调查数据的操作(分层样本,聚类),稳健的估计和测试,纵向数据方法,多变量时间序列。
表
下表详细比较了五个包的标准功能。“标准”是指
如果在超过30%的典型项目中所需的编程超过10行代码,我使用标签“10+代码”
| TYPE OF STATISTICAL ANALYSIS | R | MATLAB | SAS | STATA | SPSS |
|---|---|---|---|---|---|
| Nonparametric Tests | Yes | Yes | Yes | Yes | Yes |
| T-test | Yes | Yes | Yes | Yes | Yes |
| ANOVA & MANOVA | Yes | Yes | Yes | Yes | Yes |
| ANCOVA & MANCOVA | Yes | Yes | Yes | Yes | Yes |
| Linear Regression | Yes | Yes | Yes | Yes | Yes |
| Generalized Least Squares | Yes | Yes | Yes | Yes | Yes |
| Ridge Regression | Yes | Yes | Yes | Limited | Limited |
| Lasso | Yes | Yes | Yes | Limited | |
| Generalized Linear Models | Yes | Yes | Yes | Yes | Yes |
| Logistic Regression | Yes | Yes | Yes | Yes | Yes |
| Mixed Effects Models | Yes | Yes | Yes | Yes | Yes |
| Nonlinear Regression | Yes | Yes | Yes | Limited | Limited |
| Discriminant Analysis | Yes | Yes | Yes | Yes | Yes |
| Nearest Neighbor | Yes | Yes | Yes | Yes | |
| Naive Bayes | Yes | Yes | Limited | ||
| Factor & Principal Components Analysis | Yes | Yes | Yes | Yes | Yes |
| Canonical Correlation Analysis | Yes | Yes | Yes | Yes | Yes |
| Copula Models | Yes | Yes | Limited | ||
| Path Analysis | Yes | Yes | Yes | Yes | Yes |
| Structural Equation Modeling (Latent Factors) | Yes | 10+ code | Yes | Yes | AMOS |
| Extreme Value Theory | Yes | Yes | |||
| Variance Stabilization | Yes | Yes | |||
| Bayesian Statistics | Yes | Yes | Limited | ||
| Monte Carlo, Classic Methods | Yes | Yes | Yes | Yes | Limited |
| Markov Chain Monte Carlo | 10+ code | 10+ code | 10+ code | ||
| EM Algorithm | 10+ code | 10+ code | 10+ code | ||
| Missing Data Imputation | Yes | Yes | Yes | Yes | Yes |
| Bootstrap & Jackknife | Yes | Yes | Yes | Yes | Yes |
| Outlier Diagnostics | Yes | Yes | Yes | Yes | Yes |
| Robust Estimation | Yes | Yes | Yes | Yes | |
| Cross-Validation | Yes | Yes | Yes | Yes | |
| Longitudinal (Panel) Data | Yes | Yes | Yes | Yes | Limited |
| Survival Analysis | Yes | Yes | Yes | Yes | Yes |
| Propensity Score Matching | Yes | Yes | Limited | Yes | |
| Stratified Samples (Survey Data) | Yes | Yes | Yes | Yes | Yes |
| Experimental Design | Yes | Yes | Limited | ||
| Quality Control | Yes | Yes | Yes | Yes | Yes |
| Reliability Theory | Yes | Yes | Yes | Yes | Yes |
| Univariate Time Series | Yes | Yes | Yes | Yes | Limited |
| Multivariate Time Series | Yes | Yes | Yes | Yes | |
| Stochastic Volatility Models, Discrete Case | Yes | Yes | Yes | Yes | Limited |
| Stochastic Volatility Models, Continuous Case | Yes | Yes | Limited | Limited | |
| Diffusions | 10+ code | 10+ code | |||
| Markov Chains | 10+ code | 10+ code | |||
| Hidden Markov Models | Yes | Yes | Yes | ||
| Counting Processes | Yes | Yes | Yes | ||
| Filtering | Yes | Yes | Limited | Limited | |
| Instrumental Variables | Yes | Yes | Yes | Yes | Yes |
| Simultaneous Equations | Yes | Yes | Yes | Yes | AMOS |
| Splines | Yes | Yes | Yes | Yes | |
| Nonparametric Smoothing Methods | Yes | Yes | Yes | Yes | |
| Spatial Statistics | Yes | 10+ code | Limited | Limited | |
| Cluster Analysis | Yes | Yes | Yes | Yes | Yes |
| Neural Networks | Yes | Yes | Yes | Limited | |
| Classification & Regression Trees | Yes | Yes | Yes | Limited | |
| Boosting | Yes | Yes | Limited | ||
| Random Forests | Yes | Yes | Limited | ||
| Support Vector Machines | Yes | Yes | Yes | ||
| Signal Processing | Yes | Yes | Limited | ||
| Wavelet Analysis | Yes | Yes | Yes | ||
| Bagging | Yes | Yes | Yes | Yes | |
| Meta-analysis | Yes | 10+ code | Limited | Yes | |
| ROC Curves | Yes | Yes | Yes | Yes | Yes |
| Deterministic Optimization | Yes | Yes | Yes | Limited | |
| Stochastic Optimization | Yes | Yes | Limited |
| 计分析的类型 | [R | MATLAB | SAS | BEEN | SPSS |
|---|---|---|---|---|---|
| 非参数测试 | 是 | 是 | 是 | 是 | 是 |
| T-测试 | 是 | 是 | 是 | 是 | 是 |
| ANOVA&MANOVA | 是 | 是 | 是 | 是 | 是 |
| ANCOVA&MANCOVA | 是 | 是 | 是 | 是 | 是 |
| 线性回归 | 是 | 是 | 是 | 是 | 是 |
| 广义最小二乘法 | 是 | 是 | 是 | 是 | 是 |
| 岭回归 | 是 | 是 | 是 | 有限 | 有限 |
| 套索 | 是 | 是 | 是 | 有限 | |
| 广义线性模型 | 是 | 是 | 是 | 是 | 是 |
| Logistic回归 | 是 | 是 | 是 | 是 | 是 |
| 混合效果模型 | 是 | 是 | 是 | 是 | 是 |
| 非线性回归 | 是 | 是 | 是 | 有限 | 有限 |
| 判别分析 | 是 | 是 | 是 | 是 | 是 |
| 最近的邻居 | 是 | 是 | 是 | 是 | |
| 朴素贝叶斯 | 是 | 是 | 有限 | ||
| 因子和主成分分析 | 是 | 是 | 是 | 是 | 是 |
| 典型相关分析 | 是 | 是 | 是 | 是 | 是 |
| Copula模型 | 是 | 是 | 有限 | ||
| 路径分析 | 是 | 是 | 是 | 是 | 是 |
| 结构方程模型(潜在因子) | 是 | 10+代码 | 是 | 是 | AMOS |
| 极值理论 | 是 | 是 | |||
| 方差稳定 | 是 | 是 | |||
| 贝叶斯统计 | 是 | 是 | 有限 | ||
| 蒙特卡洛,经典方法 | 是 | 是 | 是 | 是 | 有限 |
| 马尔可夫链蒙特卡洛 | 10+代码 | 10+代码 | 10+代码 | ||
| IN算法 | 10+代码 | 10+代码 | 10+代码 | ||
| 缺少数据插补 | 是 | 是 | 是 | 是 | 是 |
| Bootstrap&Jackknife | 是 | 是 | 是 | 是 | 是 |
| 异常值诊断 | 是 | 是 | 是 | 是 | 是 |
| 稳健估计 | 是 | 是 | 是 | 是 | |
| 交叉验证 | 是 | 是 | 是 | 是 | |
| 纵向(面板)数据 | 是 | 是 | 是 | 是 | 有限 |
| 生存分析 | 是 | 是 | 是 | 是 | 是 |
| 倾向得分匹配 | 是 | 是 | 有限 | 是 | |
| 分层样本(调查数据) | 是 | 是 | 是 | 是 | 是 |
| 实验设计 | 是 | 是 | 有限 | ||
| 质量控制 | 是 | 是 | 是 | 是 | 是 |
| 可靠性理论 | 是 | 是 | 是 | 是 | 是 |
| 单变量时间序列 | 是 | 是 | 是 | 是 | 有限 |
| 多变量时间序列 | 是 | 是 | 是 | 是 | |
| 随机波动率模型,离散情形 | 是 | 是 | 是 | 是 | 有限 |
| 随机波动率模型,连续案例 | 是 | 是 | 有限 | 有限 | |
| 广播 | 10+代码 | 10+代码 | |||
| 马可夫链 | 10+代码 | 10+代码 | |||
| 隐马尔可夫模型 | 是 | 是 | 是 | ||
| 计数过程 | 是 | 是 | 是 | ||
| 过滤 | 是 | 是 | 有限 | 有限 | |
| 乐器变量 | 是 | 是 | 是 | 是 | 是 |
| 联立方程 | 是 | 是 | 是 | 是 | AMOS |
| 样条曲线 | 是 | 是 | 是 | 是 | |
| 非参数平滑方法 | 是 | 是 | 是 | 是 | |
| 空间统计 | 是 | 10+代码 | 有限 | 有限 | |
| 聚类分析 | 是 | 是 | 是 | 是 | 是 |
| 神经网络 | 是 | 是 | 是 | 有限 | |
| 分类和回归树 | 是 | 是 | 是 | 有限 | |
| 推进 | 是 | 是 | 有限 | ||
| 随机森林 | 是 | 是 | 有限 | ||
| 支持向量机 | 是 | 是 | 是 | ||
| 信号处理 | 是 | 是 | 有限 | ||
| 小波分析 | 是 | 是 | 是 | ||
| 套袋 | 是 | 是 | 是 | 是 | |
| Meta分析 | 是 | 10+代码 | 有限 | 是 | |
| ROC曲线 | 是 | 是 | 是 | 是 | 是 |
| 确定性优化 | 是 | 是 | 是 | 有限 | |
| 随机优化 | 是 | 是 | 有限 |
数据科学软件的人气对比
Robert A. Muenchen
摘要
本文以前称为“数据分析软件的受欢迎度”,通过各种方式方法来衡量市面上流行的高级分析软件软件的。此类软件也被称为数据科学,统计分析,机器学习,人工智能,预测分析,业务分析的工具,也是商业智能的子集。涵盖的软件包括:
Actuate, Alpine, Alteryx, Angoss, Apache Flink, Apache Hive, Apache Mahout, Apache MXNet, Apache Pig, Apache Spark, BMDP, C, C++ or C#, Caffe, Cognos, DataRobot, Domino Data Labs, Enterprise Miner, FICO, FORTRAN, H2O, Hadoop, Info Centricy or Xeno, Java, JMP, Julia, KNIME, Lavastorm, MATLAB, Megaputer or PolyAnalyst, Microsoft, Minitab, NCSS, Oracle Data Miner, Prognoz, Python, R, RapidMiner, Salford SPM, SAP, SAS, Scala, Spotfire, SPSS, SPSS Modeler, SQL, Stata, Statgraphics, Statistica, Systat, Tableau, Tensorflow, Teradata, Vowpal Wabbit, WEKA/Pentaho, and XGboost.
更新:最新更新是学术文章部分6/19/2017。
我在Twitter上发布了这篇文章的更新:http://twitter.com/BobMuenchen
介绍
在选择数据分析(现在更常称为分析或数据科学)工具时,需要考虑许多因素:
它是否在您的计算机上本机运行br> 该软件是否提供您需要的所有方法果没有,如何扩展br> 它的可扩展性是否使用自己独特的语言,或使用某些常用外部语言(例如Python,R)br> 它是否完全支持您喜欢的样式(编程,菜单和对话框,或工作流程图)br> 它的可视化选项(例如静态与交互式)是否适合您的问题br> 它是否以您喜欢的形式提供输出(例如,复制粘贴到另外的文字处理与LaTeX集成)br> 它能处理非常大的数据集吗br> 您的同事是否使用它以便您轻松共享数据和程序br> 你能负担得起吗/p>
有许多方法可以衡量人气或市场份额,每种方法都有其优点和缺点。按数据质量的粗略顺序,这些包括:
招聘广告
学术文章
IT研究公司报告
使用调查
写书
博客
讨论论坛活动
编程人气对比
销售和下载
比赛用途
能力增长
让我们依次检查它们中的每一个
就职机会
招聘广告
衡量数据科学软件的受欢迎程度或市场份额的最佳方法之一是计算每种软件的招聘广告数量。招聘广告信息丰富,并以资金为后盾,因此它们可能是衡量每个软件现在流行程度的最佳指标。工作趋势图让我们对未来可能变得更受欢迎的东西有了一个很好的了解。
Indeed.com是美国最大的招聘网站。正如他们的联合创始人兼前首席执行官保罗福斯特所说,Indeed.com包括“来自1000多个独特来源的所有工作,包括主要的工作委员会 – Monster,Careerbuilder,Hotjobs,Craigslist – 以及数百家报纸,协会和公司网站。“Indeed.com还具有卓越的搜索功能,它包含一个跟踪长期趋势的工具。
使用Indeed.com搜索工作很容易,但是用来跨工作来统计应用的软件是非常棘手的。某些软件仅用于数据科学(例如SPSS,Apache Spark),而其他软件更多应用于数据科学的职位,比如大量试用与报告编写的工作(例如SAS,Tableau)。通用语言(例如C,Java)在数据科学工作中被大量使用,但绝大多数使用它们的工作与数据科学无关。为了平衡竞争环境,我开发了一个 专门针对数据科学家的工作重点搜索每个软件 的协议。该协议的详细信息在另一篇文章“ 如何搜索数据科学作业”中进行了描述。本节中的所有图表都是这样查询出来的。
我在2017年2月24日收集了本节中讨论的工作计数。有人可能会认为一天的样本可能不是很稳定,但是非常大的工作职位来源使得Indeed.com的工作集中的计数趋向一致的。我最后一次收集这些数据是在2014年2月20日,那些使用相同协议(通用语言)收集的数据产生了非常相似的结果。它们的增长率在7%到11%之间,相关性为r = .94,p = .002。
图1a显示SQL占据了近18,000个工作岗位,其次是13,000个岗位的Python和Java。Hadoop接下来只有10,000多个工作岗位,然后是R,C变种和SAS。(C,C ++和C#组合在一次搜索中,因为招聘广告通常会寻找其中任何一个)。这是该报告第一次显示R比SAS 有更多的工作需求,但请记住这些是特定于数据科学的工作。如果搜索用于报告编写的岗位,您将找到近乎两倍的SAS岗位。
接下来是Apache Spark,它太新了,无法包含在2014年的报告中。它在极短的时间内走了很长的路。有关Spark的状态的详细分析,请参阅Thomas Dinsmore撰写的Spark是分析的未来。
Tableau紧随其后,约有5,000个工作岗位。2014年报告排除了Tableau,因为其工作由报告撰写主导。包括撰写报告在内,Tableau专业知识的工作数量将翻两番,超过20,000。


图1b。不太受欢迎的软件的分析工作数量(250个工作岗位,2/2017)。
接下来是迷人的全新高性能语言Julia。我添加了FORTRAN只是为了好玩,并且惊讶地看到它在这些年后仍然悬挂在那里。Apache Flink也在这个分组中,它们都有大约125个工作岗位。
H2O紧随其后,只有100多个工作岗位。
我发现SAS Enterprise Miner,RapidMiner和KNIME出现了类似数量的工作(大约90个),这令人着迷。这三者共享一个类似的工作流程用户界面,使它们特别容易使用。这些公司宣传该软件不需要太多培训,因此如果现有员工更容易接受,公司可能不需要聘请专业知识人员。SPSS Modeler也使用这种类型的接口,但它的工作量大约是其他工作的一半,占50个工作。
这成就了Statistica,先卖给戴尔,然后卖给了Quest。它的36个工作岗位远远落后于其类似的竞争对手SPSS,后者拥有惊人的74倍工作优势。
开源MXNet深度学习框架,接下来将展示34个工作岗位。Tensorflow是一个类似的项目,具有12倍的工作优势,但这两个都足够年轻,我预计未来两者都会快速增长。
在最后一批几乎没有工作的工作中,我们看到了一些新人,如DataRobot和Domino Data Labs。其他人已经存在多年,让我们想知道在竞争激烈的情况下他们如何能够维持下去。
值得注意的是,图1a和1b中显示的值是单个时间点。更受欢迎的软件的工作数量每天都没有太大变化。因此,图1a中所示软件的相对排名在未来一年内不太可能发生太大变化。图1b中显示的不太受欢迎的包具有如此低的工作量,以至于他们的排名更有可能每月变化,尽管他们相对于主要包的位置应该保持更稳定。
每个软件都有一个总体趋势,显示多年来对工作的需求如何变化。您可以使用Indeed.com的“ 工作趋势”工具绘制这些趋势。但是,和以前一样,只关注分析工作需要仔细构建查询,并且在一次比较两个趋势时,它们都必须符合相同的查询限制。这些细节在这里描述。
我对涉及R的趋势特别感兴趣所以让我们看看它与SAS相比如何。在图1c中,我们看到SAS的数据科学工作数量从2012年到2017年2月28日仍然相对平稳,当时我制作了这个图。在同一时期,R的工作岗位稳步增长,最终在2016年初超过了SAS的工作岗位。正如博客文章(以及本报告的其他部分)所述,学术出版物中R的使用率超过了2015年的SAS。

图1d。R(蓝色和低级)和Python(橙色和上层)的工作趋势。
正如我们所看到的,Python在2013年的数据科学工作方面超过了R.当然,这些语言非常不同,快速扫描工作描述将表明R工作更侧重于使用现有的分析,而Python工作有更多的自定义编程角度。
学术文章
学术文章提供了有关数据科学工具的丰富信息来源。他们的创建需要大量的努力,远远超过回应工具使用情况调查所需的努力。软件包越流行,它就越有可能作为分析工具,甚至是研究对象出现在学术出版物中。
由于研究生在这些文章中进行了大部分分析,所使用的软件可以成为事物发展方向的主要指标。Google学术搜索提供了衡量此类活动的方法。然而,没有这种规模的搜索是完美的; 每个都将包括一些不相关的文章,并拒绝一些相关的文章。通过简明的工作要求(参见上一节)搜索比搜索学术文章更容易; 但是,只有具有高级分析能力的软件才能使用这种方法进行研究。我使用的搜索术语的详细信息非常复杂,可以转到配套文章“ 如何搜索数据科学文章”。由于Google会定期改进其搜索算法,因此我每年都会重新收集前几年的数据。
图2a显示了2016年最新一年中更受欢迎的软件包(至少有750篇文章)的文章数量。为了有足够的时间进行发布,插入在线数据库和编制索引,收集了数据在2017年6月8日。
SPSS是迄今为止最具统治力的一揽子计划,已有超过15年的历史。这可能是由于它在功率和易用性之间的平衡。R排在第二位,约有一半的文章。SAS排在第三位,仍然保持着领先于Stata,MATLAB和GraphPad Prism的巨大优势,这几乎是并列的。这是我跟踪Prism的第一年,这是一个强调图形但也包括统计分析功能的软件包。它在医学研究界特别受欢迎,因为它易于使用。但是,在这种普及程度上,它提供的分析方法远远少于其他软件。
请注意,通用语言:C,C ++,C#,FORTRAN,MATLAB,Java和Python仅在与数据科学术语结合使用时才包含在内,因此请将这些计数视为近似值,而不是其他语言。

图2b。不太流行的数据科学的学术文章数量(2016年少于750篇学术文章使用的数据)。
虽然图2a和2b对于研究现在的市场份额很有用,但它们并没有显示出事态的变化。为每个分析包提供长期增长趋势图是理想的,但每年收集这么多数据太费时间了。我所做的只是收集过去两年,即2015年和2016年的数据。这提供了研究逐年变化所需的数据。
图2c显示了那些年份的百分比变化,其中使用的“热”包显示为红色(右侧);使用率下降或“冷却”的那些显示为蓝色(左侧)。由于文章的数量往往达到数千或数万,我已经删除了2015年少于500篇文章的软件。从1篇文章到5篇的软件包可能会显示500%的增长,但仍然很少利益。

图2d。Google学术搜索每年发现的学术文章数量。仅显示前六个“经典”统计包。
如图2a所示,SPSS总体上具有明显的领先优势,但现在您可以看到它的主导地位在2009年达到顶峰并且其使用率急剧下降。SAS从未接近SPSS的主导地位,其使用率在2010年左右达到顶峰.IraphPAD Prism遵循类似的模式,尽管它在2013年左右达到顶峰。
请注意,使用SPSS,SAS或Prism的文章数量的下降并未通过此特定图表中显示的其他软件的增加来平衡。即使将图2a和2b中所示的所有其他软件相加,也不能解释整体下降的情况。但是,我只关注100多种数据科学工具中的46种。SQL和Microsoft Excel可能会占用一些空间,但是将Google Scholar的搜索重点放在那些专门用于数据分析的文章中是非常困难的。
由于SAS和SPSS在图2d中的垂直空间占据如此大的空间,我删除了这两条曲线,在2015年和2016年只留下了两个SAS使用点。结果如图2e所示。
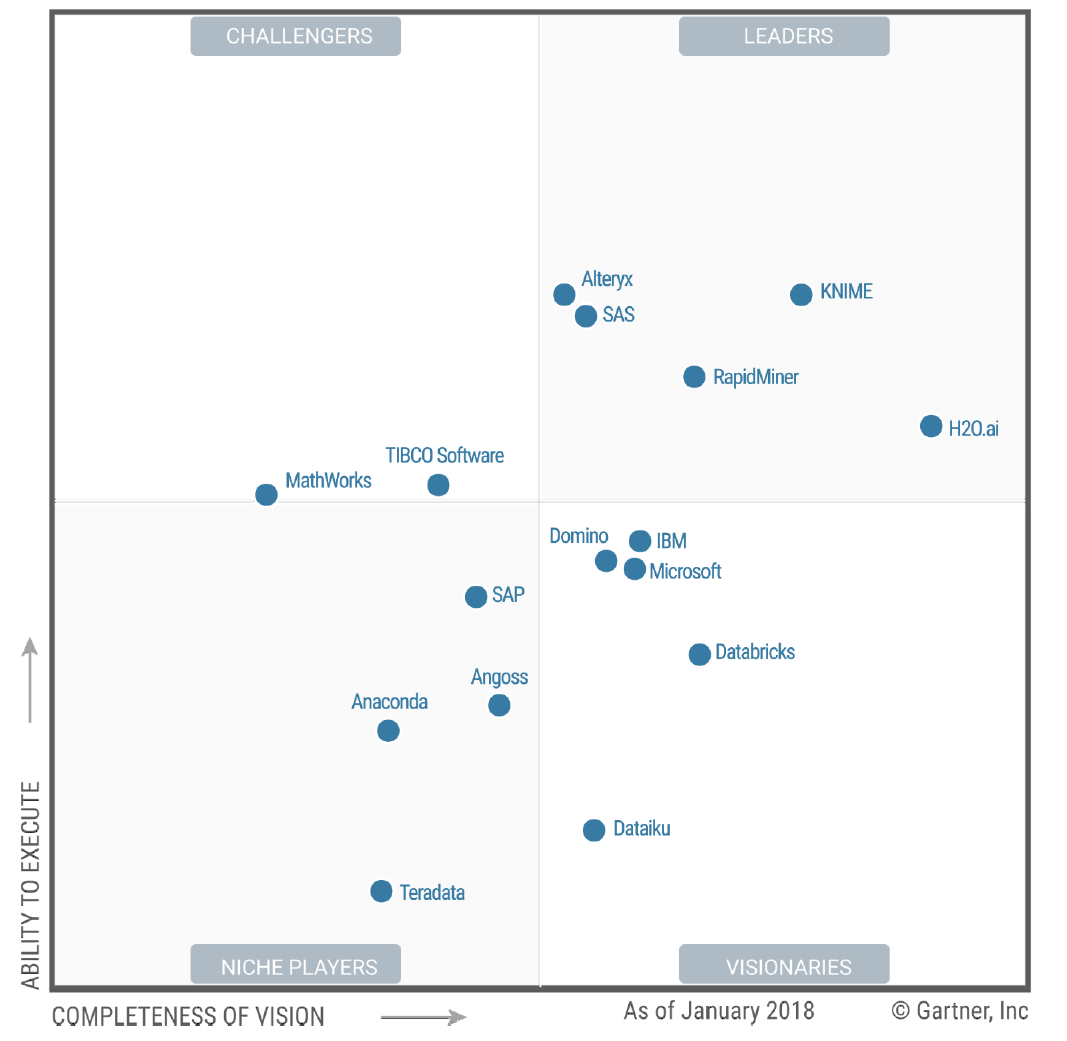
图3a。Gartner数据科学和机器学习平台的魔力象限

图3c。Forrester Wave预测分析和机器学习软件的图。
在他们的强劲表现者类别中,他们拥有H2O.ai,Microsoft,Statistica,Alpine Data,Dataiku,以及几乎没有Domino Data Labs。Gartner对Dataiku的评价相当高,但他们普遍同意其他人。唯一的例外是Gartner在2017年放弃了对Alpine Data的报道。最后,Salford Systems进入了竞争者部分。索尔福德最近被Minitab收购,该公司之前从未被Gartner或Forrester评为过,因为他们专注于统计数据包,而不像大多数其他统计数据包那样扩展到机器学习或人工智能工具(另一个值得注意的例外:Stata )。看看未来的报告如何涵盖它们将会很有趣。
与去年的Forrester报告相比,KNIME从几乎没有成为领先者的强势表现中崛起。RapidMiner和FICO从强势表演者群体的中间开始加入领导者行列。唯一的另一个主要举措是Statistica的横向调整,其战略评分下降,而当前发行的评分上升(去年Statistica属于戴尔,今年它是Quest Software的一部分。)
来源:南角影
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!