数据库的历史
自从有了人类就有了信息,声音、光线、触觉、嗅觉、味觉等等这些五官能感知的东西中都带有信息。运动员听到枪响就起跑,枪响表示起跑的信息;长城上燃起的狼烟是敌人来犯的信息;婴儿在不了解这个世界时,他们用嘴巴来感知这个世界,这些都是生活中的信息。在当今社会中我们经常说的信息化,就是收集有用的信息加以分析和判断用来指导我们的生活和生产,这些信息可能在报纸上、互联网上等等,当这些信息保存在互联网上时,它们就变成了一个个的数据,而这些变为数据的信息就需要管理起来,于是就有了专业管理数据的软件,就是各种信息管理系统,而在这些信息管理系统的底层往往使用是数据库。
在远古时代,人们用结绳记事时,绳结就是信息就是数据,它们的载体是绳子,绳子可以说是最简单的数据库了。后来人们有了纸和笔时,纸就是数据库了,有了计算机后,人们把数据储存到文件中,文件成了数据库,直到后来有了专业的软件来管理这些文件中的数据,这些软件就是数据库软件,而安装这些软件的计算机就成了数据库服务器。我们有时说的数据库可能是指保存数据的这些文件,也可能是指管理这些数据的软件,也可能是指服务器,具体要看语境。总之,数据是信息的载体,数据库是数据的仓库,数据库软件是管理数据仓库的软件,安装了数据库软件的计算机就是数据库服务器。这里有几个单词和它们对应,data,database,databaseSoft,Database Management System,databaseService
数据库有多种数据模型,不同的模型中数据的结构和操作数据的方法都不相同,不同的数据库软件会采用其中一种数据模型。目前用的比较多的数据模型有关系数据模型和非关系型数据模型,它们的代表是:Oracle、MySQL、SQLServer使用关系数据模型,H2、Redis、MongoDB等NoSQL数据模型,以键值对形式、文档形式或其它对象形式储存数据。
关系型数据库
1970年E.F.Codd’s发表了论文 <<relational model of data for large shared data banks>>大型共享型数据库的关系模型,为关系型数据库提供了基础理论,为关系型数据库的诞生创造了条件。
关系模型中主要有关系模式和关系两个概念,关系就是关系模式在某一时刻的状态或内容,关系模式是静态的稳定的,关系是动态的,随着时间变化而变化的,因为关系操作在不断的更新着数据库中的数据。
在关系型数据库出现前有网状数据库和层次数据库,用户在操作数据前要明确指定数据的位置和路径,需要明确数据的结构。关系型数据库中,用户操作数据时是非过程化的,不需要指定路径,由DBMS自己优化完成(Database Management System)
关系模型中无论是实体还是实体间的联系均由单一的结构类型——关系来表示。在实际的关系数据库中的关系也称表。一个关系数据库就是由若干个表组成。现在给关系模型下一个定义:关系模型是指用二维表的形式表示实体和实体间联系的数据模型。
几个概念
实体:现实中的具体事物或关系,如:学校、院系、学生、成绩信息、选课表信息。
表: 实体在数据库中的表现,由一条条记录组成。
行: 表格中的一条记录。
列: 组成行的一个属性。
主键:能唯一区分表中的某一行。
外键:其它表的主键在当前表中的列。
school表:学校实体对应的表
| 编号 | 名称 | 地址 |
|---|---|---|
| 1 | 北京大学 | 北京市海淀区颐和园路5号 |
| 2 | 清华大学 | 北京市海淀区双清路30号 |
编号是其中一个列
编号能唯一确定一行
student表:学生实体对应的表
| 编号 | 学号 | 姓名 | 年龄 | 班级 |
|---|---|---|---|---|
| 1 | 2001 | 赵一 | 18 | 202001 |
| 2 | 2002 | 钱二 | 18 | 202001 |
| 3 | 2003 | 孙三 | 18 | 202002 |
编号是表的主键,能唯一确定一条记录,学号列也可以,学号可以是表中的候选主键
course 课程表
| 编号 | 名称 |
|---|---|
| 1 | Java |
| 2 | C |
| 3 | Oracle |
score成绩表
| 学生编号 | 课程编号 | 成绩 |
|---|---|---|
| 1 | 1 | 100 |
| 1 | 2 | 90 |
| 1 | 3 | 88 |
| 2 | 1 | 90 |
| 2 | 2 | 90 |
| 2 | 3 | 95 |
成绩表中学生编号和课程编号共同作为主键(联合主键)
clazz 班级表
| 编号 | 名称 |
|---|---|
| 202001 | 软件一班 |
| 202002 | 软件二班 |
编号在clazz表中是主键,在student表中班级列是student表的外键
三范式
数据在数据库中会占用大量空间,为了节省空间,同时也为了让数据更安全更合理,在设计表时要用三范式来规范一下。
为了简单理解一下三范式,记住以下几点,这在考试中是非常有用的。
一范式:字段不可再拆分
二范式:表中要有主键
三范式:表中不能用别的表的非主键
以上的描述是简要描述,按照一些教材的描述是比较复杂的,下面来详细介绍一下各个范式。
一范式(1NF):字段不可拆分
这个比较好理解,比如下表中:
student
| 编号 | 姓名 | 联系方式 |
|---|---|---|
| 1 | 常熟阿庆嫂 | 2826109xx,17788990011,leadxxx |
上面的表不符合1NF,姓名列中的常熟阿庆嫂有两个信息,一个是地名常熟,一个是姓名阿庆嫂
联系方式列中,分别有QQ号,手机号,微信号,所以这个表可以设计成这样
student
| 编号 | 姓名 | 地址 | 电话 | 微信 | |
|---|---|---|---|---|---|
| 1 | 阿庆嫂 | 常熟 | 2826109xx | 17788990011 | leadxxx |
这样设计就符合一范式,因为每个列都不能再拆分了。
再来看一下第二范式:表中要有主键
表中要有主键,是为了让主键能唯一确定一条记录,如果表中的记录有重复
或者没有重复,但没有主键信息也不行,当然要符合二范式,首先要符合一范式
| 姓名 | 地址 | 性别 | 年龄 |
|---|---|---|---|
| 小红 | 下元 | 女 | 10 |
| 小红 | 下元 | 女 | 20 |
| 小明 | 小店 | 男 | 8 |
| 小明 | 小店 | 男 | 8 |
以上的记录中有两个问题:1.小红的两条记录虽然没有重复,但是也没有主键,
就算是设置主键也是“姓名+地址+性别+年龄”共同组成主键,这样才能保证没有
重复记录。2.小明的那两条记录重复了,但现实中可能是两个人,只是信息巧合了
。所以要对该表进行整改,给这个表加一个“编号”列作为主键。
| 编号 | 姓名 | 地址 | 性别 | 年龄 |
|---|---|---|---|---|
| 1 | 小红 | 下元 | 女 | 10 |
| 2 | 小红 | 下元 | 女 | 20 |
| 3 | 小明 | 小店 | 男 | 8 |
| 4 | 小明 | 小店 | 男 | 8 |
这样增加“编号”列,作为主键,就满足了第二范式。
再来看一下第三范式:表中不能有别的表的非主键列
这句话在一些资料中讲的是:
第三范式(Third Normal Form,3rd NF)就是指表中的所有数据元素不但要能唯一地被主关键字所标识,而且它们之间还必须相互独立,不存在其他的函数关系。也就是说,对于一个满足2nd NF 的数据结构来说,表中有可能存在某些数据元素依赖于其他非关键字数据元素的现象,必须消除。
这样的描述可能不太好理解,其实就是别的表中的字段只允许它们的主键出现在当前表中,其它字段不能出现,如下表:
| 编号 | 姓名 | 性别 | 班级编号 | 班级名称 |
|---|---|---|---|---|
| 1 | 赵一 | 女 | 202001 | 软件一班 |
| 2 | 钱二 | 男 | 202001 | 软件一班 |
这个表当然是满足了一、二范式,但是不满足三范式,存在两个问题:1.“班级名称”这一列没有必要出现,因为会造成数据冗余,浪费了空间,只要有“班级编号”就能确定是哪个班了。2.如果在“班级”表中修改了班级名称“软件一班”改为“软件工程一班”后,还要修改上面这个表中的“班级名称”的这一列,造成性能低下,如果要是这个表中有上亿条记录的话,修改也会花费一定的时间。但是,如果不修改这个表,会造成“202001”这个班的名称在系统中不统一,造成数据不一致,这对一个系统来说是不允许的。
出现上述原因是因为表中出现了“班级”表不是主键的“班级名称”这一列,把这一列去掉就可以了,另外,“班级编号”在班级表中是主键,在当前表中就应该是外键了。外键的好处是:如果依赖的表中没有相应的主键记录,则当前表就无法添加记录,这就是外键依赖,当然要删除依赖表中的记录时,如果记录有被依赖的情况,则要么报错不能删除,要么级联删除当前表中的记录,保证了数据的安全,避免了依赖不存在的问题。
班级表
| 编号(PK) | 名称 |
|---|---|
| 202001 | 软件一班 |
学生表
| 编号(PK) | 名称 | 班级编号(FK) |
|---|---|---|
| 1 | 赵一 | 202001 |
| 2 | 钱二 | 202002 |
上面的班级表中不存在记录“202002”这个班级,所以“2,钱二,202002”是无法保存的。如果“学生”表中的外键“班级编号”列设置了外键级联删除,则删除班级表中的“202001”记录时,会级联删除“学生”表中的所有“班级编号”是202001的记录。但是,如果外键列设置的不是级联删除,则删除班级表中的记录“202001”时,数据库会报错。
三范式也不只有三种范式,其实还有巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式),我们知道范式是为了解决数据冗余的问题,但是范式太高的话,又会影响数据查询的性能,所以,一般做到三范式就可以了。
DBA常用操作
管理员登录
sqlplus / as sysdba
这样登录是管理员登录,免密码,拥有最高权限,它采用的是操作系统的验证,所以只要能正常登录操作系统,就可以用这个命令登录Oracle数据库。但是,有时候我们登录操作系统的用户因为权限原因不能这样登录数据库,就要解决操作系统用户权限的问题。找到Oracle的安装目录,如:F:appDELLproduct11.2.0dbhome_1database这个目录下的一个文件oradba.exe,在文件上右键选择以管理员身份运行即可解决权限不足的问题。
数据库关闭和启动
shutdown immediate;立即关闭,自然关闭
startup; 启动数据
创建用户
create user user1 identified by user1;
user1是用户名,identified by user1是指定密码。
如果建错用户怎么办以删除
drop user user1;
如果user1下已经有用户新建的对象,这样删除会失败,要加一个参数
drop user user1 cascade;
删除用户级联删除其下的对象
权限设置
刚创建的用户没有任何权限,不能登录,不能操作数据库,权限可以是单独的权限,具体的权限,也可以角色,角色是若干权限的集合,Oracle有自带的权限,connect/resource/dba,如果需要定制权限集合,我们可以自定义角色,让角色拥有自己的权限。
grant connect to user1;
给user1指定connect的角色(可以登录)
grant resource to user1
resource可以创建数据库对象,但是没有登录权限,不能创建会话。
grant dba to user1;
dba权限是最高的
回收权限:
revoke dba from user1;
查看用户有哪些权限或角色:
select * from dba_role_privs where grantee=‘用户名’;
要用dba角色登录执行上面的SQL
导入导出
oracle11g数据库导入导出:
- 传统方式——exp(导出)和(imp)导入:
- 数据泵方式——expdp导出和(impdp)导入;
- 第三方工具——PL/sql Develpoer;
重点学1和3
一、什么是数据库导入导出br> oracle11g数据库的导入/导出,就是我们通常所说的oracle数据的还原/备份。
数据库导入:把.dmp 格式文件从本地导入到数据库服务器中(本地oracle测试数据库中);
数据库导出:把数据库服务器中的数据(本地oracle测试数据库中的数据),导出到本地生成.dmp格式文件。
.dmp 格式文件:就是oracle数据的文件格式(比如视频是.mp4 格式,音乐是.mp3 格式);
二、二者优缺点描述:(没有实测,从资料中得来)
1.exp/imp:
优点:代码书写简单易懂,从本地即可直接导入,不用在服务器中操作,降低难度,减少服务器上的操作也就 保证了服务器上数据文件的安全性。
缺点:这种导入导出的速度相对较慢,合适数据库数据较少的时候。如果文件超过几个G,大众性能的电 脑,至少需要4~5个小时左右。
2.expdp/impdp:
优点:导入导出速度相对较快,几个G的数据文件一般在1~2小时左右。
缺点:代码相对不易理解,要想实现导入导出的操作,必须在服务器上创建逻辑目录(不是真正的目录)。我们 都知道数据库服务器的重要性,所以在上面的操作必须慎重。所以这种方式一般由专业的程序人员来完 成(不一定是DBA(数据库管理员)来干,中小公司可能没有DBA)。
3.PL/sql Develpoer:
优点:封装了导入导出命令,无需每次都手动输入命令。方便快捷,提高效率。
缺点:长时间应用会对其产生依赖,降低对代码执行原理的理解。
三、特别强调:
目标数据库:数据即将导入的数据库(一般是项目上正式数据库);
源数据库:数据导出的数据库(一般是项目上的测试数据库);
1.目标数据库要与源数据库有着名称相同的表空间。
2.目标数据在进行导入时,用户名尽量相同(这样保证用户的权限级别相同)。
3.目标数据库每次在进行数据导入前,应做好数据备份,以防数据丢失。
4.使用数据泵时,一定要现在服务器端建立可用的逻辑目录,并检查是否可用。
5.弄清是导入导出到相同版本还是不同版本(oracle10g版本与oracle11g版本)。
6.目标数据导入前,弄清楚是数据覆盖(替换),还是仅插入新数据或替换部分数据表。
7.确定目标数据库磁盘空间是否足够容纳新数据,是否需要扩充表空间。
8.导入导出时注意字符集是否相同,一般Oracle数据库的字符集只有一个,并且固定,一般不改变。
9.导出格式介绍:
Dmp格式:.dmp是二进制文件,可跨平台,还能包含权限,效率好;
Sql格式:.sql格式的文件,可用文本编辑器查看,通用性比较好,效率不如第一种,
适合小数据量导入导出。尤其注意的是表中不能有大字段 (blob,clob,long),如果有,会报错;
Pde格式:.pde格式的文件,.pde为PL/SQL Developer自有的文件格式,只能用PL/SQL Developer工具
导入导出,不能用文本编辑器查看;
10.确定操作者的账号权限。
四、二者的导入导出方法:
1、传统方法:
通用命令:exp(imp) username/password@SERVICENAME:1521 file=“e:temp.dmp” full = y;
数据库导出举例:
exp user1/user1@127.0.0.1:1521 file=“e:temp.dmp” full = y;
exp:导出命令,导出时必写。
imp:导入命令,导入时必写,每次操作,二者只能选择一个执行。
username:导出数据的用户名,必写;
password:导出数据的密码,必写;
@:地址符号,必写;
SERVICENAME:Oracle的服务名,必写;
1521:端口号,1521是默认的可以不写,非默认要写;
file=“e:temp.dmp” : 文件存放路径地址,必写;
full=y :表示全库导出。可以不写,则默认为no,则只导出用户下的对象;
方法细分:
1.完全导入导出:
exp(imp) username/password@SERVICENAME:1521 file=“e:temp.dmp” full = y;
2.部分用户表table导入导出:
exp(imp) username/password@SERVICENAME:1521 file=“e:temp.dmp” tabels= (table1,table2,table3,…);
3.表空间tablespaces导入导出:
//一个数据库实例可以有N个表空间(tablespace),一个表空间下可以有N张表(table)。
exp(imp) username/password@SERVICENAME:1521 file=“e:temp.dmp” tablespaces= (tablespace1,tablespace2,tablespace3,…);
4.用户名username对象导入导出:
exp(imp) username/password@SERVICENAME:1521 file=“e:temp.dmp” owner(username1,username2,username3);
OracleJOB
恢复数据
SQL
SQL (Structured Query Language:结构化查询语言) 用于管理关系型数据库,可以定义数据库对象,操作表中数据等。
SQL 在1986年成为 ANSI(American National Standards Institute 美国国家标准化组织)的一项标准,在 1987 年成为国际标准化组织(ISO)标准。
SQL是数据库比较重要的知识,可以分为:
DDL
Data Definition Language
所有的对数据库对象的操作语句
create database , alter database , create table ,alter table drop table,create index等
表空间
表空间是存储数据的地方,存储数据库对象的地方,在磁盘上对应有数据文件。
Oracle中默认有一个系统表空间,和临时表空间。如果创建用户不指定用户的表空间则默认把用户创建在系统表空间。系统表空间类似于Windows的C盘(系统盘),如果把所有软件安装在C盘是不合理的,Oracle中把用户分配在系统表空间也是不合理的。最理想的是一个用户一个表空间,在删除用户时可以删除表空间,这样管理比较好。
临时表空间是数据库操作时临时使用,如排序去重复,统计等大数据时使用,小规模可以在内存中完成 。
保证用户有创建表空间的权限:grant create tablespace to user1;
create tablespace tabsp1 datafile ‘data1.dbf’ size 1m;
执行完这条SQL,在数据库目录下创建一个data1.dbf文件
F:appDELLproduct11.2.0dbhome_1databaseDATA1.DBF
如果表空间满了可以扩容,扩容表空间文件需要用户有相应的权限:
grant alter database to user1;(用sys用户登录分配权限)
alter database datafile ‘data1.dbf’ resize 2m; 可以观察data1.dbf已经变大了
以上是一种方法,还可以用下面的方法修改表空间:
grant alter tablespace to user1;先保证用户有相应权限
alter tablespace tabsp1 add datafile ‘data2.dbf’ size 1m;增加一个数据文件给表空间
以上是正常数据表空间,还可以创建临时表空间,正常数据存放正常数据表空间,临时表空间供数据库存放临时数据用。Oracle临时表空间主要用来做查询和存放一些缓冲区数据。临时表空间消耗的主要原因是需要对查询的中间结果进行排序。
create temporary tablespace tmpsp1 tempfile ‘tmp1.dbf’ size 2m;创建表空间语句
创建用户时指定表空间,如果没有指定表空间时,创建的用户使用的是系统表空间,不建议使用系统表空间,如果用户使用自己的表空间时,可以在删除用户时把表空间也删除,这样比较彻底。当然,可以多个用户共用一个表空间,这个另当别论。
create user user2 identified by user2 default tablespace tabsp1 temporary tablespace tmpsp1;
以上语句是创建user2用户指定密码和默认表空间临时表空间。
删除表空间:
表
建表前要先了解Oracle的数据类型,因为要为列指定合适的数据类型,数据类型有以下几种:
| 类型 | 说明 |
|---|---|
| number | 数字类型 |
| integer | 整数(在程序中用) |
| char | 定长字符型 |
| varchar | 变长字符型,最大4000 |
| date | 日期类型 |
| TIMESTAMP | 时间戳(可精确到毫秒) |
| blob | 二进制数据(Binary Large Object)保存音视频4G |
| clob | 字符型数据(Character Large Object)保存文档,支持定长和变长字符集 |
| bfile | 二进制文件(文件在数据库外的磁盘上) |
char和varchar:
关于varchar长度的说明,varchar和char的区别是char长度是固定的,内容不够列的宽度也会占用列的宽度,比如一个字段是char型,长度是20,username char(20),则无论username内容是多少,都会占用20个固定的宽度,就算username是一个字符也是如此,如果某些列的数据长度是比较固定某个长度的,则最好使用此类型。varchar的长度是变化的,如果实际数据内容不足列的宽度则只占用合适的空间来存放数据,会大大地节省数据库空间。但是,varchar更适合列比较大的,如果varchar(2)这样列比较小的就没有意义了,它反而还要花费额外的空间来记录该列的数据实际长度,数据库在处理varchar列时要进行额外的计算处理,并存储数据的实际长度,在效率上不如char性能高。
varchar最大4000。这个4000可能是4000字节也可能是4000字符,取决于参数NLS_LENGTH_SEMANTICS的设置,这个参数有两个选项,BYTE,CHAR,如果是BYTE则是4000字节,可以放4000个英文和数字,但汉字或其他字符就不一定了,肯定的是只会小于4000,如果是汉字占三个字节,则能放4000/3个字符。
alter session set NLS_LENGTH_SEMANTICS=‘CHAR’;可以修改这个参数 =‘CHAR’ 或 =‘BYTE’
number类型:
number可以指定精度,如果没有指定默认的是38位。number(5)是一个5位数据的整数,number(5,2)是一个总长为5位,小数位为2位,整数位是3位,如:123.23,123.2也可以,123.2345也可以,因为小数位会自动四舍五入为123.23,但是整数位不能随意写,如1234.1虽然整体长度是5位数字,但是除去小数位规定的2位,整数位只能是3位数,1234超出3位,所以是不符合规范的。number(5,-2)也是可以的,如果第2个参数是负数,则没有小数,并且整数位的后2位会忽略,数字的整体长度为第一个参数减去第二个参数5-(-2)=7,1234567是可以的。
| 列 | 结果 |
|---|---|
| number(1,1) | 错误:1,2 正确0.1,0.11,0.15 |
| number(3,2) | 错误:12,12.1 正确:1.12,1.15555 |
| number(3,-2) | 错误:123456 正确:12345(结果:12300),12(结果:0) |
定长和变长字符集,感兴趣的可以了解一下。
数据库的约束
数据库的约束主要是为了保证数据的有效性,从而保证了数据的安全性。约束有以下几点:
- 主键约束
- 唯一约束
- 默认约束
- 检查约束
- 外键约束
主键约束:保证数据的唯一性,并且主键列数据不能为空。
唯一约束:保证数据的唯一性,唯一约束的列可以为空。表中有些列不是主键,但也是每条记录唯一的,比如学生表中的学
号不重复,但是因为数据库设计时建议用非业务性列作主键,所以一般会用一个id作主键。
默认约束:保证数据的完整性,如果没有填入信息时,会使用默认信息填入,保证数据的完整性。
检查约束:保证数据的有效性,让值在有效范围内取值,如:性别[0,1],年龄[1-60]等。
外键约束:保证数据的完整性,互相依赖的数据不能缺失。比如学生依赖班级表,班级表数据删除后,学生记录就没有了班
级信息。外键的on delete no action这是默认的,删除父表记录时,子表有关联时会报错,set null 删除父表时会把子表相应外键列置空,cascade删除父表时级联删除子表记录。
建表:
可以在建表时指定主键或其他各种约束,也可以在建好表后,修改表时增加这些约束。
create table table_name(colname datatype[,…])
修改表:
alter table tablename …
如果t1表中的c3列是char型,长度是2
insert into t1(c3) values(‘1’);
c3列长度是2,插入的值是1个长度,但因为列类型是char型,所以实际长度变成了‘1 ’值中有空格。
修改列的宽度时,不能小于2。
alter table t1 modify c3 char(3);
删除表:
drop table tablename;
附加:truncate
1.truncate使用语法
truncate的作用是清空表或者说是截断表,只能作用于表。truncate的语法很简单,后面直接跟表名即可,例如: truncate table tbl_name 或者 truncate tbl_name 。
执行truncate语句需要拥有表的drop权限,从逻辑上讲,truncate table类似于delete删除所有行的语句或drop table然后再create table语句的组合。为了实现高性能,它绕过了删除数据的DML方法,因此,它不能回滚。尽管truncate table与delete相似,但它被分类为DDL语句而不是DML语句。
2.truncate与drop,delete的对比
上面说过truncate与delete,drop很相似,其实这三者还是与很大的不同的,下面简单对比下三者的异同。
truncate与drop是DDL语句,执行后无法回滚;delete是DML语句,可回滚。
truncate只能作用于表;delete,drop可作用于表、视图等。
truncate会清空表中的所有行,但表结构及其约束、索引等保持不变;drop会删除表的结构及其所依赖的约束、索引等。
truncate会重置表的自增值;delete不会。
truncate不会激活与表有关的删除触发器;delete可以。
truncate后会使表和索引所占用的空间会恢复到初始大小;delete操作不会减少表或索引所占用的空间,drop语句将表所占用的空间全释放掉。
每个oracle表包含一个指示器,叫High Water Mark,它存储在段头中,标志表曾存储的最大数据量。在数据装载到表以前,表为空,HWM指向表的开始。随着数据插入到表中,HWM跟着增长,但是当数据被删除时,HWK并不下降。在进行全表扫描时,Oracle将读取所有HWM之下的数据块,不管这些数据块中是否有数据。例如一个表中High Water Mark有1000个数据块,其中有500个数据块因为被删除而没有数据,但对表的全表扫描将读取1000个数据块,对数据库的查询性能有非常大的影响。
DML
Data Manipulation Language
对数据的操作,增删改
insert into table,update table,delete from table
insert into table_name [(c1[,…])] values(v1[,…])
update table_name set col1=v1[,…] [where col=v]
delete from table_name [where col=v]
这里有一个truncate的操作,此操作也是针对表记录的,是清空表中的所有记录,而不是delete所有,它们的区别是:delete删除记录后不会释放表所占的空间,在给表中增加记录时,有一个数据指针会依次变化增高位置,delete后这个指针并没有回落,以前数据占用的空间还在,数据也在,只是做了逻辑删除,我们看不到数据而已,但是通过数据恢复操作还可以恢复这些数据,有点类似Windows操作系统的回收站情形。但是truncate操作表后,会立即释放表空间,就像清空回收站的操作一样,所以数据是不可再恢复的。
DQL
对数据的查询, 这个是SQL的主要内容,有单表查询,多表查询,嵌套查询,排序 ,分页,去重,结果合并等内容。
select col1[,…] from table_name [ where col1=xx,…]
SQL查询语句可以很简单也可以很复杂
单表查询
scott是Oracle一个测试账号,默认是锁定,要解锁,解锁完了要修改密码(强制)
scott下面有几张表供我们DQL使用
alter user scott account unlock;解锁账号
scott是Oracle一个职员的名称,它家的猫叫老虎tiger
scott的密码默认是tiger,但是这个账号默认是锁定的,需要解锁。
- 简单查询
select * from t_user;
这是最简单的SQL语句,查询所有列时可以用 “*”来代替,但是,在规范上不建议使用*查询,这样会让数据库去数据仓库获取字段信息然后执行查询,在性能上会有所降低,不如下面的SQL效率高:
select id,name,password,age,sex from t_user;
SELECT * FROM USER_TABLES T 获取当前用户下的所有的表信息
SELECT * FROM USER_TAB_COLUMNS WHERE TABLE_NAME = ‘T_CLAZZ’;
所有当前 表的所有字段信息
-
别名
对一些字段比较长或是经过运算得出的查询结果可以用别名作为查询结果显示,如:
select sal,sal+100 from emp;
emp表是Oracle自带用户scott下的一张表,scott用户下的表和数据可以供我们学习DQL来使用,此处的这条SQL是查询emp(员工表)中的所有员工工资和加100元后的结果,第二列sal+100作为结果列的显示可以使用别名,别名是在列或表达后加as关键字或不加也可以
select sal,sal+100 as sal2,sal+100 sal3 from emp;
以上两种写法都可以。 -
条件过滤
如果只要查部分数据,可以使用where条件进行过滤
select empno,ename,sal from emp where sal>=3000
查询员工工资大于等于3000的员工的编号和姓名及工资信息 -
去重
查看emp表中部门共有几个
select deptno from emp;
得到的数据会有大量重复的,如果去重可以用distinct关键字
select distinct deptno from emp;
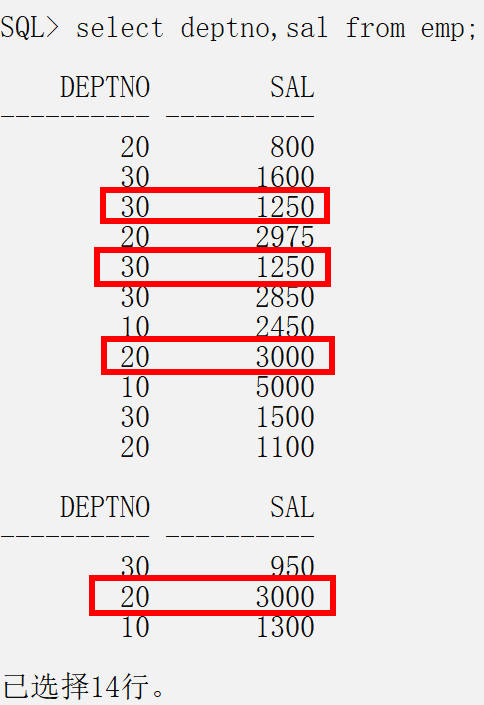

没有过滤之前有14条记录,其中标红色的是重复的,加上distinct后,变成了12条
来源:会说话的java
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!