点击上方“IT共享之家”,进行关注
回复“资料”可获赠Python学习福利
【一、项目背景】
相信大家都有一种头疼的体验,要下载电影特别费劲,对吧一部一部的下载,而且不能直观的知道最近电影更新的状态。
今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来。
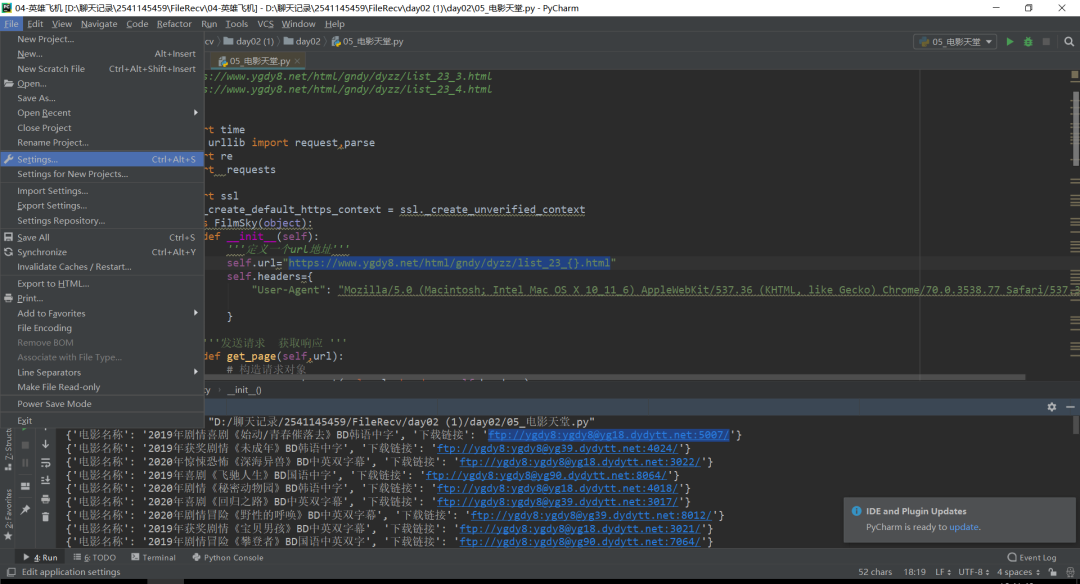

打开后会出现这个界面点击你的项目名字(project:(你的项目名字))project interpreter点击加号下载我们需要的库本项目需要(requests,requests,time,re模块),如下图所示。
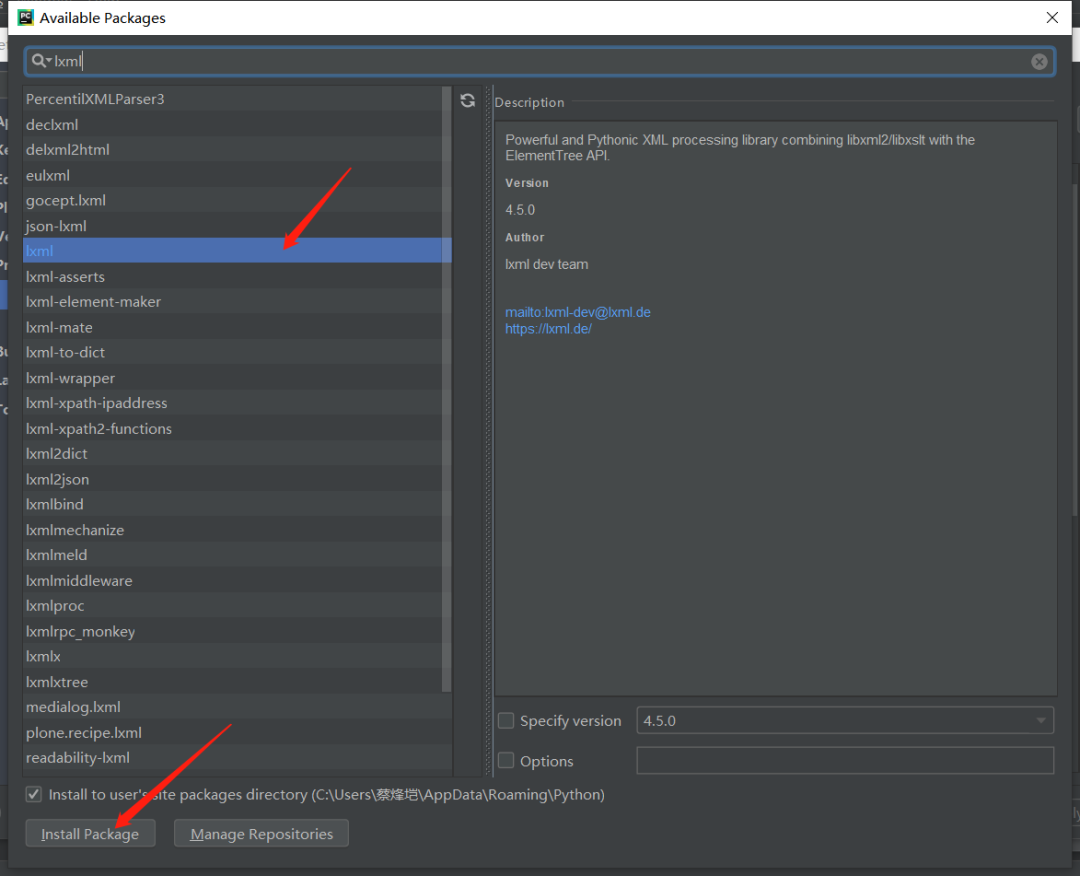
【三、项目实施】
我们需要(requests,requests,time,re模块 ),如下图所示。
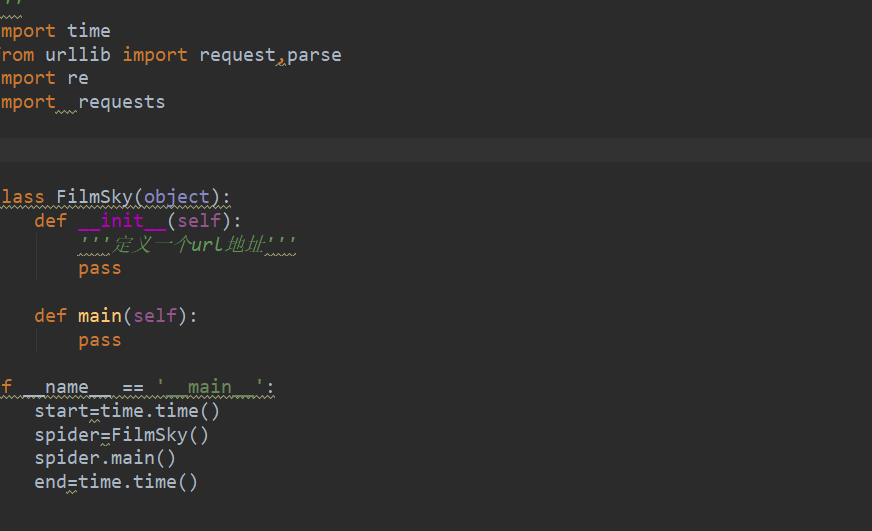
这个time是用于防止反爬,设置的时间延时。
首先我们来分析一下这个网址下一页得到特点。

在主方法main函数里边用for循环实现遍历网址。
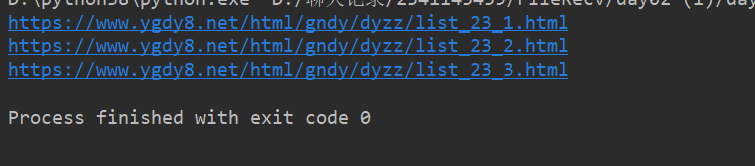
说明你已经成功一半了加油!!
现在我们需要对这些网址发生请求,为了更直观的看出来,我们用一个类写。
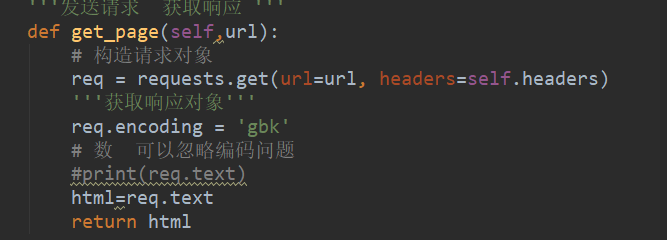
我们用requests发生请求 这个网站的编码是gbk (怎么看网站的编码。
打开一个网站右键检查在header的标签,以这个网站为例,可以看到charset=“gb312”。
这个gb2312就是编码 我们常见的编码方式有2种(utf_8, gbk)。
我们可以验证一下是不是真的请求到了。使用Print(html)看到这个结果(一个完整的html网页)说明请求成功。
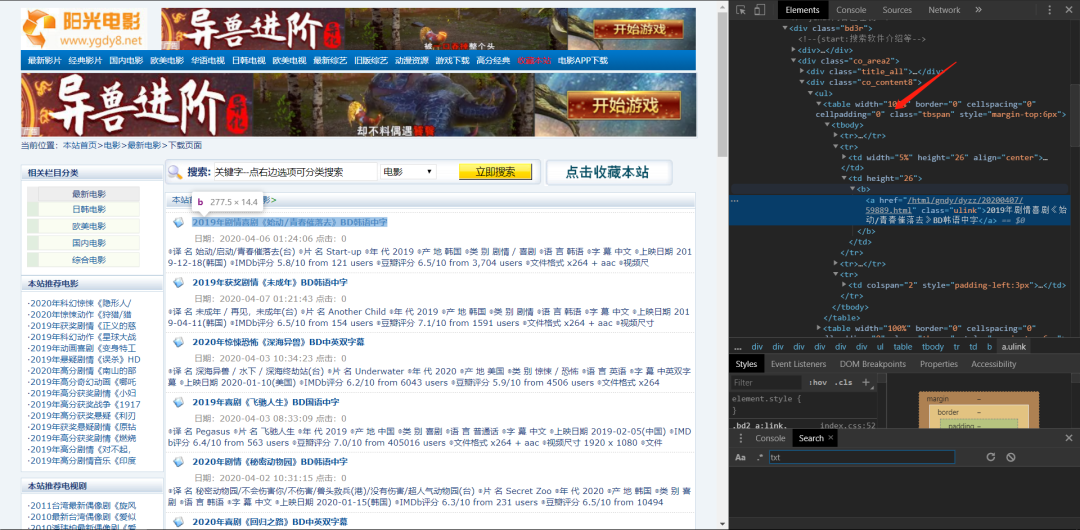
所以我们可以先找到table,一层一层的去找,可以参考一下下面的图。
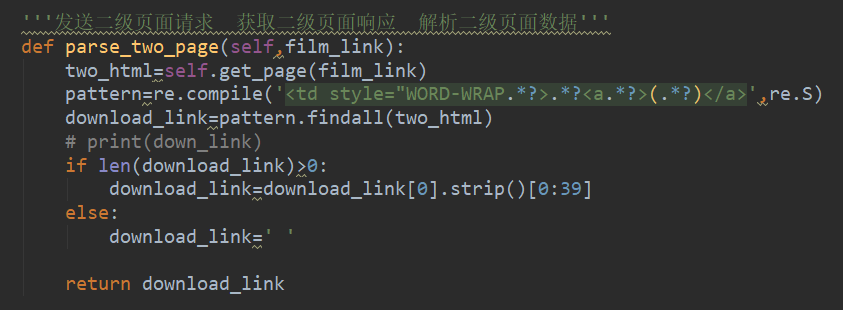
点开第二级页面如图右键点击下载链接,如下图所示:
我们用正则表达式解析 得到我们下载链接地址,如下图所示:

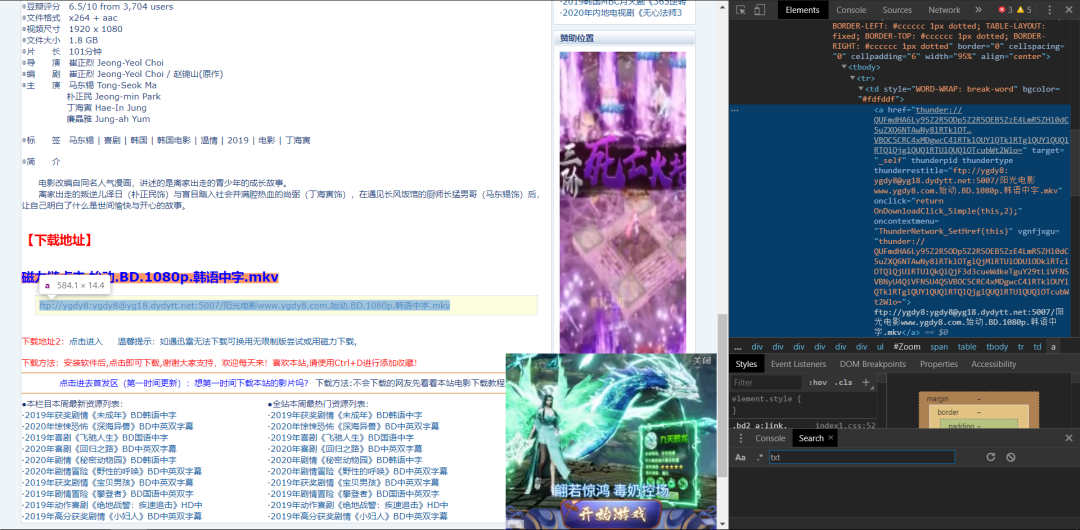
得到结果,如下图所示:
最后我们优化一下请求的代码有点重复 我们优化一下;
用一个值去保存说明请求头的内容以后请求我们只有调用这个方法进行请求就好,如下图所示:
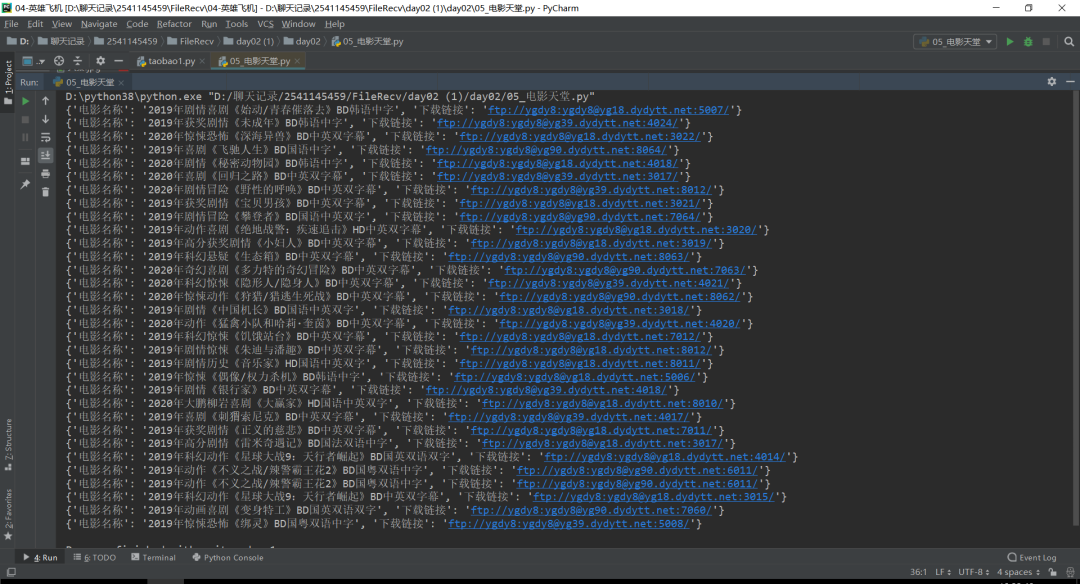
点击蓝色的链接就可以这个下载(要下载迅雷 迅雷下载更快哇)
这样是不是能够更直观的看出你要电影啦击即可下载噢!
【五、总结】
1.本文基于Python网络爬虫技术,提供了一种更直观的去看自己喜欢的电影并且方便下载的方式。
2. 不建议抓取太多,容易使得服务器负载。
3. 需要本文代码的话,后台回复“电影天堂”四个字即可获取。
看完本文有收获转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

——————- End ——————-
往期精彩文章推荐:
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树网络爬虫urllib208411 人正在系统学习中 相关资源:PHP寄生虫繁殖劫持程序V3.0_寄生虫程序-PHP代码类资源-CSDN文库
来源:weixin_39924329
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!