用户画像
有过一次网购经历后,下次登陆该网站,会弹出各种同类型替代商品或者互补商品的推荐;成为某品牌的注册会员,特殊的日子(会员日、生日)经常会收到品牌商发来的通知(祝福)短信或者邮件。这一切都是精准化营销的常见套路。
在互联网大数据时代,得用户者得天下。以庞大的用户数据为依托,构建出一整套完善的用户画像,借助其标签化、信息化、可视化的属性,是企业实现个性化推荐、精准营销强有力的前提基础。
可见,深入了解用户画像的含义,掌握用户画像的搭建方法,显得尤其重要。
用户画像是真实用户的虚拟模型
关于“用户画像是什么”的问题,最早给出明确定义的是交互设计之父Alan Cooper,他认为:Persona(用户画像)是真实用户的虚拟代表,是建立在一系列真实数据之上的目标用户模型。
敲黑板,划重点:真实、数据、虚拟。
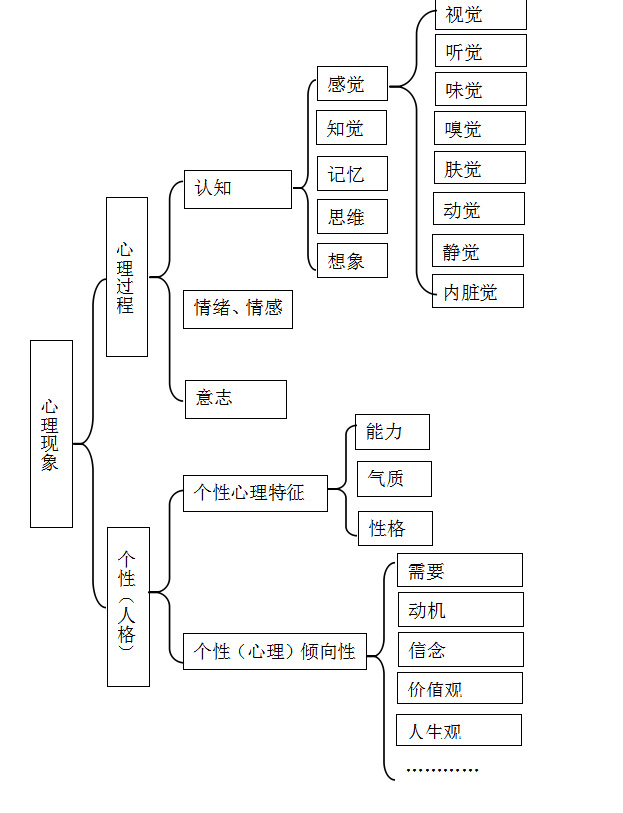

来源:“心理现象”百度百科
因为人口属性和心理现象都带有先天的性质,整体处于稳定状态,共同组成用户画像最表面以及最内里的信息素,由此形成稳定的2D用户画像。

3D用户画像
用户画像的价值
企业必须在开发和营销中解决好用户需求问题,明确回答“用户是谁——用户需要/喜欢什么——哪些渠道可以接触到用户——哪些是企业的种子用户”。
更了解你,是为了更好的服务你!可以说,正是企业对用户认知的渴求促生了用户画像。
用户画像是真实用户的缩影,能够为企业带来不少好处。
指导产品研发以及优化用户体验
在过去较为传统的生产模式中,企业始终奉行着“生产什么就卖什么给用户”的原则。这种闭门造车的产品开发模式,常常会产生“做出来的东西用户完全不买账”的情况。
如今,“用户需要什么企业就生产什么”成为主流,众多企业把用户真实的需求摆在了最重要的位置。
在用户需求为导向的产品研发中,企业通过获取到的大量目标用户数据,进行分析、处理、组合,初步搭建用户画像,做出用户喜好、功能需求统计,从而设计制造更加符合核心需要的新产品,为用户提供更加良好的体验和服务。
实现精准化营销
精准化营销具有极强的针对性,是企业和用户之间点对点的交互。它不但可以让营销变得更加高效,也能为企业节约成本。
以做活动为例:商家在做活动时,放弃自有的用户资源转而选择外部渠道,换而言之,就是舍弃自家精准的种子用户而选择了对其品牌一无所知的活动对象,结果以超出预算好几倍的成本获取到新用户。
这就是不精准所带来的资源浪费。
包括我前面所提到的,网购后的商品推荐以及品牌商定时定点的节日营销,都是精准营销的成功示范。
要做到精准营销,数据是最不可缺的存在。以数据为基础,建立用户画像,利用标签,让系统进行智能分组,获得不同类型的目标用户群,针对每一个群体策划并推送针对性的营销。
可以做相关的分类统计
简单来说,借助用户画像的信息标签,可以计算出诸如“喜欢某类东西的人有多少”、“处在25到30岁年龄段的女性用户占多少”等等。
便于做相关的数据挖掘
在用户画像数据的基础上,通过关联规则计算,可以由A可以联想到B。
沃尔玛“啤酒和尿布”的故事就是用户画像关联规则分析的典型例子。
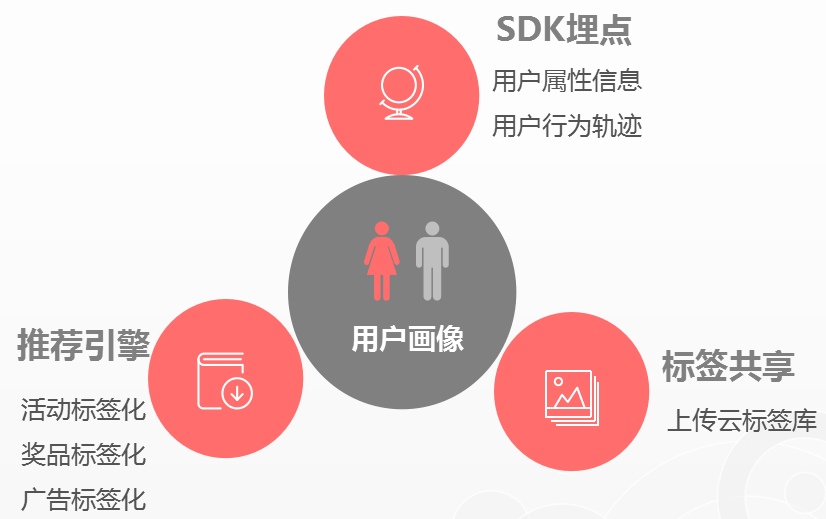
所谓“事件”,就是指用户作用于产品、网站页面的一系列行为,由数据收集方(产品经理、运营人员)加以描述,使之成为一个个特定的字段标签。
我们以“网站购物”为例,为了抓取用户的人口属性和行为轨迹,做SDK埋点之前,先预设用户购物时的可能行为,包括:访问首页、注册登录、搜索商品、浏览商品、价格对比、加入购物车、收藏商品、提交订单、支付订单、使用优惠券、查看订单详情、取消订单、商品评价等。
把这些行为用程序语言进行描述,嵌入网页或者商品页的相应位置,形成触点,让用户在点击时直接产生网络行为数据(登陆次数、访问时长、激活率、外部触点、社交数据)以及服务内行为数据(浏览路径、页面停留时间、访问深度、唯一页面浏览次数等等)。
数据反馈到服务器,被存放于后台或者客户端,就是我们所要获取到的用户基础数据。
然而,在大多数时候,利用埋点获取的基础数据范围较广,用户信息不够精确,无法做更加细化的分类的情况。比如说,只知道用户是个男性,而不知道他是哪个年龄段的男性。
在这种情况下,为了得到更加详细的,具有区分度的数据,我们可以利用A/B test。
A/B test就是指把两个或者多个不同的产品/活动/奖品等推送给同一个/批人,然后根据用户作出的选择,获取到进一步的信息数据。
为了知道男性用户是哪个年龄层的,借助A/B test,我们利用抽奖活动,在奖品页面进行SDK埋点后,分别选了适合2030岁和3040岁两种不同年龄段使用的礼品,最后用户选择了前者,于是我们能够得出:这是一位年龄在20~30岁的男性用户。
以上就是数据的获取方法。有了相关的用户数据,我们下一步就是做数据分析处理——数据建模。
用户画像成型阶段——数据建模
1、定性与定量相结合的研究方法
定性化研究方法就是确定事物的性质,是描述性的;定量化研究方法就是确定对象数量特征、数量关系和数量变化,是可量化的。
一般来说,定性的方法,在用户画像中,表现为对产品、行为、用户个体的性质和特征作出概括,形成对应的产品标签、行为标签、用户标签。
定量的方法,则是在定性的基础上,给每一个标签打上特定的权重,最后通过数学公式计算得出总的标签权重,从而形成完整的用户模型。
所以说,用户画像的数据建模是定性与定量的结合。
2、数据建模——给标签加上权重
给用户的行为标签赋予权重。
用户的行为,我们可以用4w表示: WHO(谁);WHEN(什么时候);WHERE(在哪里);WHAT(做了什么),具体分析如下:
WHO(谁):定义用户,明确我们的研究对象。主要是用于做用户分类,划分用户群体。网络上的用户识别,包括但不仅限于用户注册的ID、昵称、手机号、邮箱、身份证、微信微博号等等。
WHEN(时间):这里的时间包含了时间跨度和时间长度两个方面。“时间跨度”是以天为单位计算的时长,指某行为发生到现在间隔了多长时间;“时间长度”则为了标识用户在某一页面的停留时间长短。
越早发生的行为标签权重越小,越近期权重越大,这就是所谓的“时间衰减因子”。
WHERE(在哪里):就是指用户发生行为的接触点,里面包含有内容+网址。内容是指用户作用于的对象标签,比如小米手机;网址则指用户行为发生的具体地点,比如小米官方网站。权重是加在网址标签上的,比如买小米手机,在小米官网买权重计为1,,在京东买计为0.8,在淘宝买计为0.7。
WHAT(做了什么):就是指的用户发生了怎样的行为,根据行为的深入程度添加权重。比如,用户购买了权重计为1,用户收藏了计为0.85,用户仅仅是浏览了计为0.7。
当上面的单个标签权重确定下来后,就可以利用标签权重公式计算总的用户标签权重:
标签权重=时间衰减因子×行为权重×网址权重
举个栗子:A用户今天在小米官网购买了小米手机;B用户七天前在京东浏览了小米手机。
通过埋点我们可以拿到以下四大想要的的目标数据:
1、行为数据:时间、地点、人物、交互、交互的内容;
2、质量数据:浏览器加载情况、错误异常等;
3、环境数据:浏览器相关的元数据以及地理、运营商等;
4、运营数据:PV、UV、转化率、留存率(很直观的数据);
有关用户画像的介绍到此就告一段落了,鉴于自身能力有限,很多地方表达的不到位或者没有提及,有啥意见或者建议欢迎留言!
 来源:人人都是产品经理([直通车](http://www.woshipm.com/operate/377676.html))
来源:人人都是产品经理([直通车](http://www.woshipm.com/operate/377676.html))
来源:IT界的小小小学生
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!