1:Flink重新编译
由于实际生产环境当中,我们一般都是使用基于CDH的大数据软件组件,因此我们Flink也会选择基于CDH的软件组件,但是由于CDH版本的软件并没有对应的Flink这个软件安装包,所以我们可以对开源的Flink进行重新编译,然后用于适配我们对应的CDH版本的hadoop
1.1: 准备工作
- 安装maven3版本及以上:省略
- 安装jdk1.8:省略
1.2:下载flink源码包
2:flink架构模型
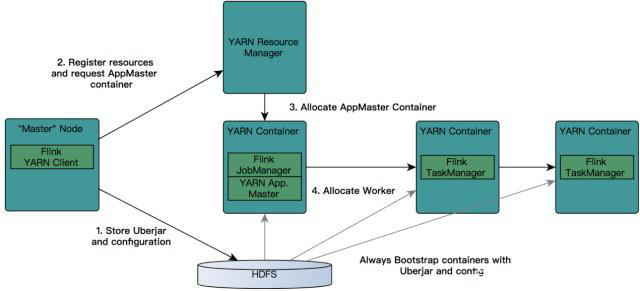

- Flink ON YARN工作流程如下所示:
- 首先提交job给YARN,就需要有一个Flink YARN Client。
- 第一步:Client将Flink 应用jar包和配置文件上传到HDFS。
- 第二步:Client向ResourceManager注册resources和请求APPMaster Container。
- 第三步:REsourceManager就会给某一个Worker节点分配一个Container来启动APPMaster,JobManager会在APPMaster中启动。
- 第四步:APPMaster为Flink的TaskManagers分配容器并启动TaskManager,TaskManager内部会划分很多个Slot,它会自动从HDFS下载jar文件和修改后的配置,然后运行相应的task。TaskManager也会与APPMaster中的JobManager进行交互,维持心跳等
Flink的支持以上这三种部署模式,一般在学习研究环节,资源不充足的情况下,采用Local模式就行,生产环境中Flink ON YARN比较常见
来源:陈同学:
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!