一、概述
Flume(收集数据的框架)是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件。
Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
Flume支持定制各类数据发送方,用于收集各类型数据;同时,Flume支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对flume的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume可以适用于大部分的日常数据采集场景。
当前Flume有两个版本。Flume 0.9X版本的统称Flume OG(original generation),Flume1.X版本的统称**(next generation)**。由于Flume NG经过核心组件、核心配置以及代码架构重构,与Flume OG有很大不同,使用时请注意区分。改动的另一原因是将Flume纳入 apache 旗下,Cloudera Flume 改名为 Apache Flume。
二、运行机制
Flume系统中核心的角色是agent,
Agent:,flume集群中,每个节点都是一个agent,包含了flume单节点:接受、封装、承载、传输event到目的地的过程。这个过程中包含三部分(source、channel、sink)。
每一个agent相当于一个数据传递员,内部有三个组件:
Source:采集的数据源,用于跟数据源对接,以获取数据;
Sink:下沉点即数据最终保存的地方,采集数据的传送目的,用于往下一级agent传递数据或者往 最终存储系统传递数据;
Channel:agent内部的数据传输通道,用于从source将数据传递到sink; 基于缓存完成数据的传递,基于本地磁盘完成数据的传递
在整个数据的传输的过程中,流动的是event,channel中传递的一条条数据,它是Flume内部数据传输的最基本单元。event将传输的数据进行封装。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的event包括:event headers、event body、,event信息,其中event信息就是flume收集到的日记记录。
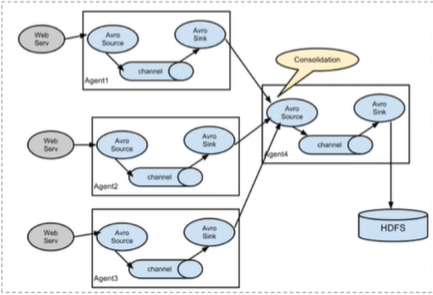
三、简单架构
单个agent通过source,sink,channel 完成的配置,采集数据,

五、Flume安装部署
上传安装包apache-flume-1.9.0-bin.tar.gz 到hadoop01节点目录上 /opt/softwares/
安装包下载地址
链接:https://pan.baidu.com/s/1ixBc0yMIAMhIPXulAUCI8g
提取码:pa1u
然后解压
进入解压后目录,更改目录名
然后进入flume的conf目录,修改文件名
修改conf下的flume-env.sh,取消注释 export JAVA_HOME=/usr/lib/jvm/java-8-oracle
配置自己的JAVA_HOME
可通过执行 查看
六 、flume初体验
进入conf目录下,
配置如下内容:
启动服务
在/opt/servers/flume-1.9.0/目录下执行
注:
-c conf 指定flume自身的配置文件所在目录
-f conf/http_logger.properties 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
flume启动后占用当前窗口,复制一个新的窗口在任意目录下执行以下
文章知识点与官方知识档案匹配,可进一步学习相关知识Java技能树首页概览91725 人正在系统学习中
来源:千呼万唤始出来,犹抱琵琶半遮面
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!