热词的识别与提取算法
标签(空格分隔):SPARK机器学习
欢迎关注本小小草的微信号,并求带飞~
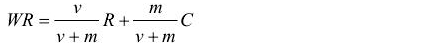

WR是每个词的加权得分,WR越大表示热度越大
R是该词汇的平均得分(这里设定都为1)
v是总词频
m是排名前n的词汇的最低词频(n是自定义的阀值)
热词排名法二:牛顿冷却定律
将热词排名想象成一个即自然冷却的过程。可以利用物理学定律,建立“温度”与“时间”之间的函数关系,构建一个“指数式衰减”的过程。
牛顿冷却定律:物体的冷却速度,与其当前温度与室温之间的温差成正比。
若仅仅使用今天与昨天的搜索量对比,时间差为1,最终的冷却系数可以通过如下公式计算:
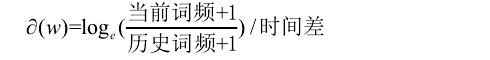
若冷却系数越低则说明热度就越大
3.实验设计
3.1 数据获取
数据来源:搜狗搜索引擎网页查询一个月的日志。数据大小1.02G,每天搜索日志大约为50M。
数据格式:访问时间 用户ID 查询词 改URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
字段之间用t分割,此处只关心查询词,将其过滤出来。
3.2 热词的评价标准
(1)统计词语一周内的词频,词频在当天未峰值,并大于某一阀值
(2)该峰值与起始值差值大于某一阀值
(3)热度值大于某一阀值
写成公式,可如下表示:

(1)提查询词,作者用了正则表达式来提取查询词,但起始字段是按t分割的话,直接用split(“t”)(2)取出索引为3的字段就可以了。
(2)对查询词进行中文分词
(3)利用贝叶斯平均或者牛顿冷却定律计算词语的热度,并对热度倒叙排序
(4)对每天的热词进行相关搜索,核实该热词是否真实存在
(5)利用热词评价指标,计算准确率
4.实验过程
4.1 贝叶斯平均实验
今天的词频比昨天的词频增长地越多,那么说明这个词今天越热,但是如何表示这个增长呢先肯定会想到减法,让今天的词频减去昨天的词频,差越大表示热度越大,但是以下两个词就戳穿了这个逻辑的BUG:
好男儿从0到441,搜索量猛增,男同志虽然也增长了那么多,但他本来基数就大,所以好男儿更应该被选为热词。故光看增长量是有误区的
文献中作者又提到采用除法的形式,今天的词频除以昨天的词频,倍数越大则热度越大,但是同理,如果除数的基数很小,那么它的倍数就会很大,这样的逻辑也有失偏颇。
最后作者采用了归一法
今天词频/(昨天词频+今天词频)
如下图例子:
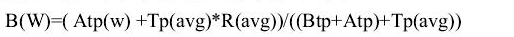
比如计算“俞思远”这个词的热度,套用以上公式
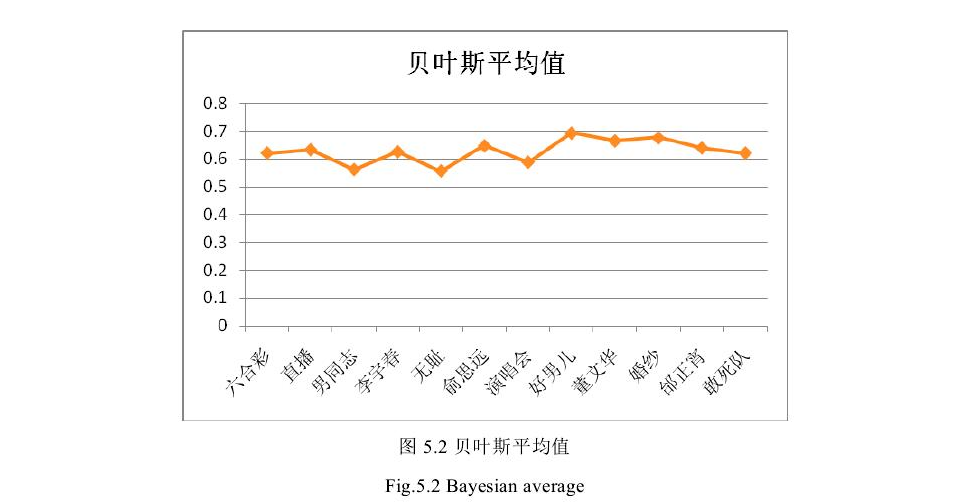
4.2 牛顿冷却定律实验
利用以上提到的牛顿冷却定律的公式对以上词语进行计算,可以得到每个词的冷却系数。冷却系数越低则说明热度越大,如下表:
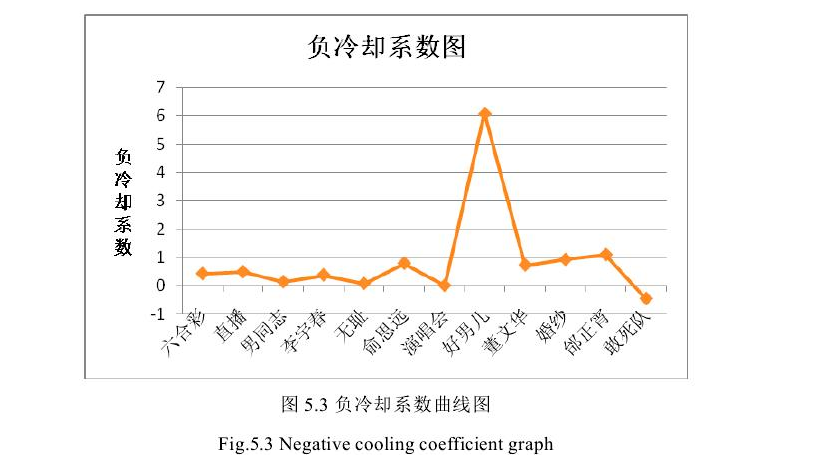
牛顿冷却定律相比于贝叶斯平均法的有点在于其热度的变化比较清晰。但是,对于(当前词频)/(历史词频)的比值较大的词估计过高,贝叶斯平均法则没有这个问题
4.3 热词评价值的改进
作者将以上两种方法进行了结合。分别通过两个方法计算出两个热度,然后对两个值各自设置一个权值,得到综合的H(w)热度值。公式如下:
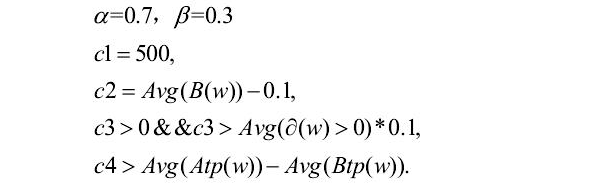
(关于阀值的制定,我觉得不能完全参照作者的,在具体项目中应当自己测试出最符合本项目的阀值)
改进热词评价后,以下是计算出的新热度值

文章知识点与官方知识档案匹配,可进一步学习相关知识算法技能树首页概览33962 人正在系统学习中
来源:王小小小草
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!