1.MapReduce简介
Hadoop MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。
MapReduce的思想就是“分而治之”。
(1)Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:
一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
(2)Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
2.优缺点
1.优点:
1)MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
2.缺点:
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
3.计算框架与流程
在hadoop中,每个MapReduce任务都被初始化成为一个Job,每一个Job都可以分成两个阶段:Map阶段以及Reduce阶段。Map阶段会接受一个<key,value>的输入,产生一个<key,value>的中间输出,hadoop会把这些key相同的value集合到一起传给reduce函数,reduce会接受一个<key,(list of values)>的输入,处理后输出一个<key,value>。
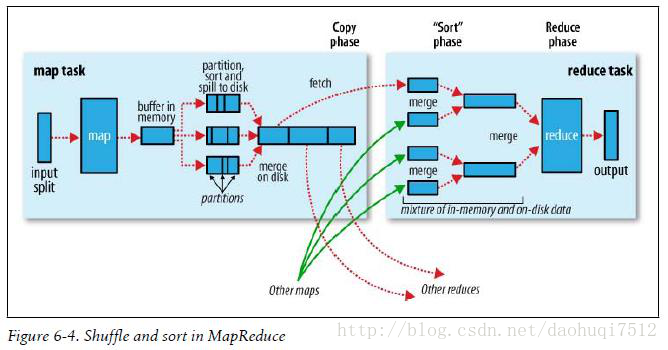

Map的输出结果是由collector处理的,所以Map端的shuffle过程包含在collect函数对Map的输出结果处理过程中。
每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(这就是spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。写磁盘前,要partition,sort。如果有combiner,combine sort后数据再写磁盘。等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
Reduce端,shuffle可以分成三个阶段:复制Map输出,合并排序和Reduce处理。
Reducer通过Http方式得到输出文件的分区。TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。排序阶段合并map输出。然后走Reduce阶段。
例子
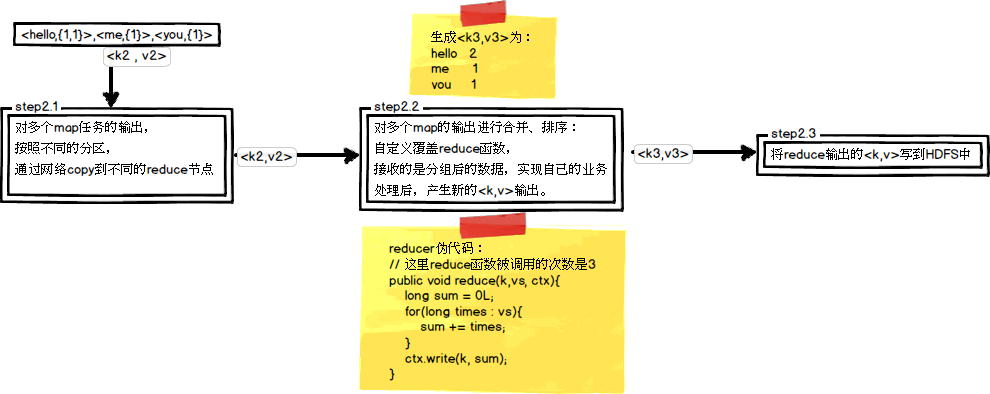
这里以WordCount单词计数为例,介绍map和reduce两个阶段需要进行哪些处理。单词计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数,如图所示:

(2)reduce过程
来源:qq_37676008
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!