Table of Contents
1.传统linux网络协议栈流程和性能分析
协议栈的主要问题
针对单个数据包级别的资源分配和释放
流量的串行访问
从驱动到用户态的数据拷贝
内核到用户空间的上下文切换
跨内存访问
2. 提高捕获效率的技术
预分配和重用内存资源
数据包采用并行直接通道传递.
内存映射.
数据包的批处理.
亲和性与预取.
3. 典型收包引擎
3.1 libpcap
3.2 libpcap-mmap
3.3 PF_RING
3.4 PACKET_MMAP
PACKET_MMAP的实现原理
PACKET_MMAP源码分析
3.5 DPDK
UIO+mmap 实现零拷贝(zero copy)
UIO+PMD 减少中断和CPU上下文切换
HugePages 减少TLB miss
其它优化
3.6 XDP(eXpress Data Path)
PS:使用XDP(eXpress Data Path)防御DDoS攻击
新的分层方法
绕过更低层的门
XDP
关于DDoS防御
怎么做/p>
4. 无锁队列技术
CAS原子指令操作
内存屏障
5. 基于pfring/dpdk的应用
参考
相关阅读
1.传统linux网络协议栈流程和性能分析
Linux网络协议栈是处理网络数据包的典型系统,它包含了从物理层直到应用层的全过程。


- 数据包到达网卡设备。
- 网卡设备依据配置进行DMA操作。(第1次拷贝:网卡寄存器->内核为网卡分配的缓冲区ring buffer)
- 网卡发送中断,唤醒处理器。
- 驱动软件从ring buffer中读取,填充内核skbuff结构(第2次拷贝:内核网卡缓冲区ring buffer->内核专用数据结构skbuff)
- 数据报文达到内核协议栈,进行高层处理。
- socket系统调用将数据从内核搬移到用户态。(第3次拷贝:内核空间->用户空间)
研究者们发现,Linux内核协议栈在数据包的收发过程中,内存拷贝操作的时间开销占了整个处理过程时间开销的65%,此外层间传递的系统调用时间也占据了8%~10%。
协议栈的主要问题
针对单个数据包级别的资源分配和释放
每当一个数据包到达网卡,系统就会分配一个分组描述符用于存储数据包的信息和头部,直到分组传送到用户态空间,其描述符才被释放。此外,sk_buff庞大的数据结构中的大部分信息对于大多数网络任务而言都是无用的.
流量的串行访问
现代网卡包括多个硬件的接收端扩展(receiver-side scaling, RSS)队列可以将分组按照五元组散列函数分配到不同的接收队列。使用这种技术,分组的捕获过程可以被并行化,因为每个RSS队列可以映射到一个特定的CPU核,并且可以对应相应的NAPI线程。这样整个捕获过程就可以做到并行化。
但是问题出现在之上的层次,Linux中的协议栈在网络层和传输层需要分析合并的所有数据包
- ①所有流量在一个单一模块中被处理,产生性能瓶颈;
- ②用户进程不能够从一个单一的RSS队列接收消息.
这就造成了上层应用无法利用现代硬件的并行化处理能力,这种在用户态分配流量先后序列的过程降低了系统的性能,丢失了驱动层面所获得的加速.
此外,从不同队列合并的流量可能会产生额外的乱序分组
从驱动到用户态的数据拷贝
从网卡收到数据包到应用取走数据的过程中,存在至少2次数据包的复制
内核到用户空间的上下文切换
从应用程序的视角来看,它需要执行系统调用来接收每个分组.每个系统调用包含一次从用户态到内核态的上下文切换,随之而来的是大量的CPU时间消耗.在每个数据包上执行系统调用时产生的上下文切换可能消耗近1 000个CPU周期.
跨内存访问
例如,当接收一个64 B分组时,cache未命中造成了额外13.8%的CPU周期的消耗.另外,在一个基于NUMA的系统中,内存访问的时间取决于访问的存储节点.因此,cache未命中在跨内存块访问环境下会产生更大的内存访问延迟,从而导致性能下降.
2. 提高捕获效率的技术
目前高性能报文捕获引擎中常用的提高捕获效率的技术,这些技术能够克服之前架构的性能限制.
预分配和重用内存资源
这种技术包括:
- 开始分组接收之前,预先分配好将要到达的数据包所需的内存空间用来存储数据和元数据(分组描述符)。尤其体现在,在加载网卡驱动程序时就分配好 N 个描述符队列(每个硬件队列和设备一个).
- 同样,当一个数据包被传送到用户空间,其对应的描述符也不会被释放,而是重新用于存储新到达的分组.得益于这一策略,在每个数据包分配/释放所产生的性能瓶颈得到了消除.此外,也可以通过简化sk_buff的数据结构来减少内存开销.
数据包采用并行直接通道传递.
为了解决序列化的访问流量,需要建立从RSS队列到应用之间的直接并行数据通道.这种技术通过特定的RSS队列、特定的CPU核和应用三者的绑定来实现性能的提升.
这种技术也存在一些缺点:
- ①数据包可能会乱序地到达用户态,从而影响某些应用的性能;
- ②RSS使用Hash函数在每个接收队列间分配流量.当不同核的数据包间没有相互关联时,它们可以被独立地分析,但如果同一条
流的往返数据包被分配到不同的CPU核上时,就会造成低效的跨核访问.
内存映射.
使用这种方法,应用程序的内存区域可以映射到内核态的内存区域,应用能够在没有中间副本的情况下读写这片内存区域.
用这种方式我们可以使应用直接访问网卡的DMA内存区域,这种技术被称为零拷贝.但零拷贝也存在潜在的安全问题,向应用暴露出网卡环形队列和寄存器会影响系统的安全性和稳定性 .
数据包的批处理.
为了避免对每个数据包的重复操作的开销,可以使用对数据包的批量处理.
这个策略将数据包划分为组,按组分配缓冲区,将它们一起复制到内核/用户内存.运用这种技术减少了系统调用以及随之而来的上下文切换的次数;同时也减少了拷贝的次数,从而减少了平摊到处理和复制每个数据包的开销.
但由于分组必须等到一个批次已满或定时器期满才会递交给上层,批处理技术的主要问题是延迟抖动以及接收报文时间戳误差的增加.
亲和性与预取.
由于程序运行的局部性原理,为进程分配的内存必须与正在执行它的处理器操作的内存块一致,这种技术被称为内存的亲和性.
CPU亲和性是一种技术,它允许进程或线程在指定的处理器核心上运行.
在内核与驱动层面,软件和硬件中断可以用同样的方法指定具体的CPU核或处理器来处理,称为中断亲和力.每当一个线程希望访问所接收的数据,如果先前这些数据已被分配到相同CPU核的中断处理程序接收,则它们在本地cache能够更容易被访问到.
3. 典型收包引擎
3.1 libpcap
参考:libpcap实现机制及接口函数
libpcap的包捕获机制是在数据链路层增加一个旁路处理,不干扰系统自身的网路协议栈的处理,对发送和接收的数据包通过Linux内核做过滤和缓冲处理,最后直接传递给上层应用程序。
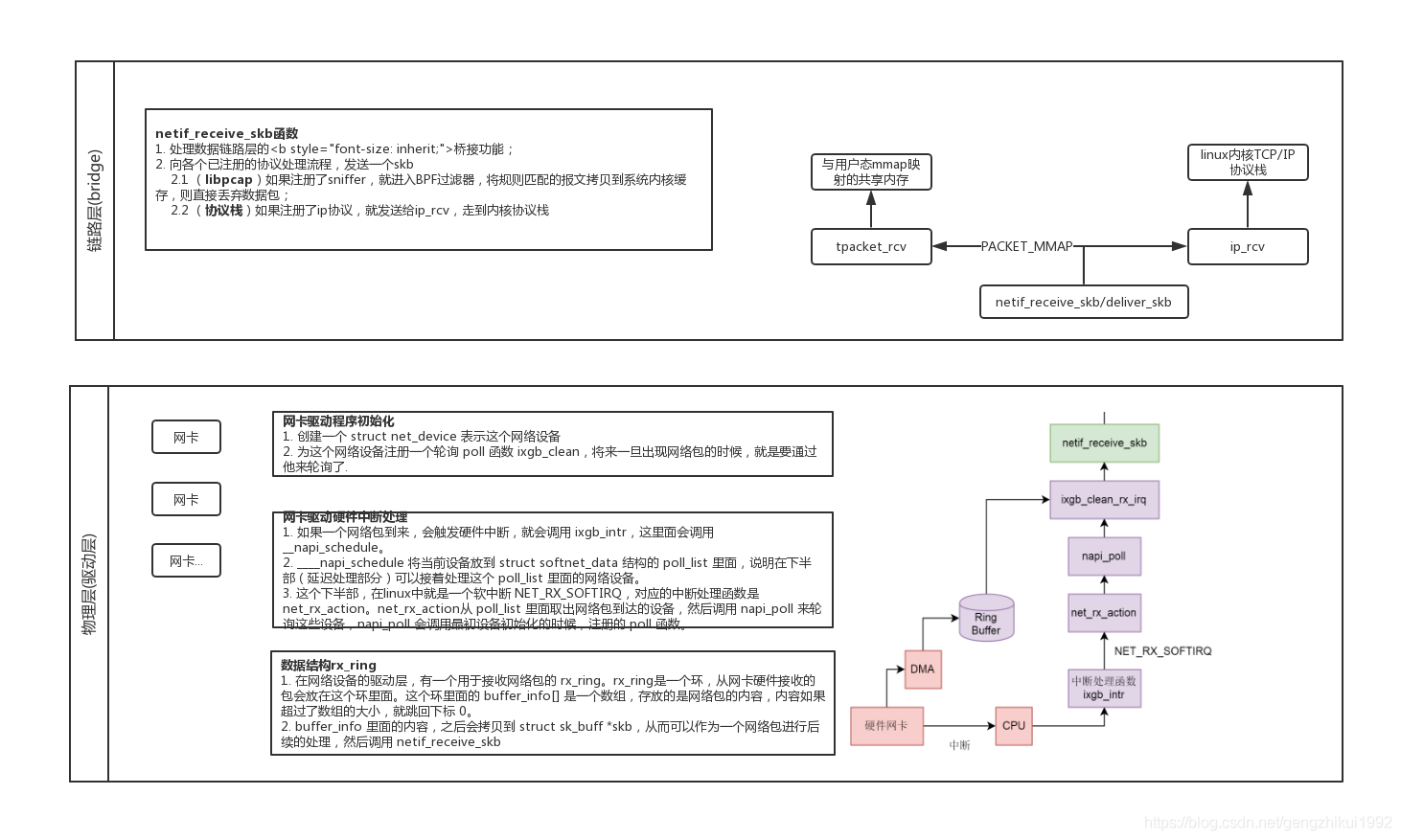
- 数据包到达网卡设备。
- 网卡设备依据配置进行DMA操作。(第1次拷贝:网卡寄存器->内核为网卡分配的缓冲区ring buffer)
- 网卡发送中断,唤醒处理器。
- 驱动软件从ring buffer中读取,填充内核skbuff结构(第2次拷贝:内核网卡缓冲区ring buffer->内核专用数据结构skbuff)
- 接着调用netif_receive_skb函数:
如果有抓包程序,由网络分接口进入BPF过滤器,将规则匹配的报文拷贝到系统内核缓存 (第3次拷贝)。BPF为每一个要求服务的抓包程序关联一个filter和两个buffer。BPF分配buffer 且通常情况下它的额度是4KB the store buffer 被使用来接收来自适配器的数据; the hold buffer被使用来拷贝包到应用程序。 - 处理数据链路层的桥接功能;根据skb->protocol字段确定上层协议并提交给网络层处理,进入网络协议栈,进行高层处理。libpcap绕过了Linux内核收包流程中协议栈部分的处理,使得用户空间API可以直接调用套接字PF_PACKET从链路层驱动程序中获得数据报文的拷贝,将其从内核缓冲区拷贝至用户空间缓冲区(第4次拷贝)
3.2 libpcap-mmap
libpcap-mmap是对旧的libpcap实现的改进,新版本的libpcap基本都采用packet_mmap机制(见3.4 PACKET_MMAP小节)。PACKET_MMAP通过mmap,减少一次内存拷贝(第4次拷贝没有了),减少了频繁的系统调用,大大提高了报文捕获的效率。
3.3 PF_RING
参考:PF_RING学习笔记
我们看到之前libpcap有4次内存拷贝。
libpcap_mmap有3次内存拷贝。
PF_RING提出的核心解决方案便是减少报文在传输过程中的拷贝次数。

我们可以看到,相对与libpcap_mmap来说,pfring允许用户空间内存直接和rx_buffer做mmap。这又减少了一次拷贝(libpcap_mmap的第2次拷贝:rx_buffer->skb)
PF-RING ZC实现了DNA(Direct NIC Access 直接网卡访问)技术,将用户内存空间映射到驱动的内存空间,使用户的应用可以直接访问网卡的寄存器和数据。
通过这样的方式,避免了在内核对数据包缓存,减少了一次拷贝(libpcap的第1次拷贝,DMA到内核缓冲区的拷贝)。这就是完全的零拷贝。

其缺点是,只有一个应用可以在某个时间打开DMA ring(请注意,现在的网卡可以具有多个RX / TX队列,从而就可以在每个队列上同时一个应用程序),换而言之,用户态的多个应用需要彼此沟通才能分发数据包。
https://cloud.tencent.com/developer/article/1521276
PF_RING针对libpcap的改进方法:将网卡接收到的数据包存储在一个环状缓存中,这个环状缓存有两个接口,一个供网卡向其中写数据,另一个为应用层程序提供读取数据包的接口,从而减少了内存的拷贝次数,若将收到的数据包分发给多个环形缓冲区则可以实现多线程应用程序的读取。
每创建一个PF_RING套接字便分配一个环形缓冲区,当套接字结束时释放缓冲区,不同套接字拥有不同缓冲区,将PF_RING套接字绑定到某网卡上,当数据包到达网卡时,将其放入环形缓冲区,若缓冲区已满,则丢弃该数据包。当有新的数据包到达时,直接覆盖掉已经被用户空间读取过的数据包空间。
网卡接收到新的数据包后,直接写入环形缓冲区,以便应用程序直接读,若应用程序需要向外发送数据包,也可以直接将数据包写入环形缓冲区,以便网卡驱动程序将该数据包发送到相应接口上。
PF_RING的工作流程:
普通的网络接收函数中,网卡驱动到内核传递数据的核心是netif_rx()函数,若使用了设备轮询(NAPI)机制(中断机制+轮询机制,以中断方式通知系统,将设备注册到轮询队列后关闭中断,轮询队列中注册的网络设备从而读取数据包,采用NAPI机制可以减少中断触发的时间),则传递数据的核心是netif_receive_skb()函数。PF_RING定义了一个处理函数skb_ring_handler(),插入前两个核心函数的起始位置,每当有数据包需要传递时,先经过skb_ring_handler()的处理。

(1) 一般的数据包捕获(libpcap):

(2)非零拷贝的pf_ring(pf_ring noZC):

(3)零拷贝的pf_ring(pf_ring ZC):

PF_RING有三种工作模式:
- Transparent_mode=0:用户通过mmap获取已经拷贝到内核的数据包,相当于libpcap-mmap技术;
- Transparent_mode=1:将数据包放入环形缓冲区;
- Transparent_mode=2:数据包只由PF_RING模块处理,不经过内核,直接mmap到用户态
后两种模式需要使用PF_RING特殊定制的网卡驱动:pf_ring.ko
PF_RING部分内容分享自微信公众号 – nginx遇上redis(GGame_over_the_world)
原文出处及转载信息见文内详细说明,如有侵权,请联系 yunjia_community@tencent.com 删除。
原始发表时间:2019-08-29
3.4 PACKET_MMAP
https://blog.csdn.net/dandelionj/article/details/16980571
PACKET_MMAP实现的代码都在net/packet/af_packet.c中,其中一些宏、结构等定义在include/linux/if_packet.h中。
PACKET_MMAP的实现原理
PACKET_MMAP在内核空间中分配一块内核缓冲区,然后用户空间程序调用mmap映射到用户空间。将接收到的skb拷贝到那块内核缓冲区中,这样用户空间的程序就可以直接读到捕获的数据包了。
如果没有开启PACKET_MMAP,只是依靠AF_PACKET非常的低效。它有缓冲区的限制,并且每捕获一个报文就需要一个系统调用,如果为了获得packet的时间戳就需要两个系统调用了(获得时间戳还需要一个系统调用,libpcap就是这样做的)。
PACKET_MMAP非常高效,它提供一个映射到用户空间的大小可配置的环形缓冲区。这种方式,读取报文只需要等待报文就可以了,大部分情况下不需要系统调用(其实poll也是一次系统调用)。通过内核空间和用户空间共享的缓冲区还可以起到减少数据拷贝的作用。
当然为了提高捕获的性能,不仅仅只是PACKET_MMAP。如果你在捕获一个高速网络中的数据,你应该检查NIC是否支持一些中断负载缓和机制或者是NAPI,确定开启这些措施。
PACKET_MMAP减少了系统调用,不用recvmsg就可以读取到捕获的报文,相比原始套接字+recvfrom的方式,减少了一次拷贝和一次系统调用。
PACKET_MMAP的使用:
从系统调用的角度来看待如何使用PACKET_MMAP,可以从 libpcap底层实现变化的分析中strace的分析中看出来:
接下来的这些内容,翻译自Document/networking/packet_mmap.txt,但是根据需要有所删减
1. socket的创建和销毁如下,与不使用PACKET_MMAP是一样的:
如果mode设置为SOCK_RAW,链路层信息也会被捕获;如果mode设置为SOCK_DGRAM,那么对应接口的链路层信息捕获就不会被支持,内核会提供一个虚假的头部。
销毁socket和释放相关的资源,可以直接调用一个简单的close()系统调用就可以了。
2. PACKET_MMAP的设置
用户空间设置PACKET_MMAP只需要下面的系统调用就可以了:
上面系统调用中最重要的就是req参数,其定义如下:
这个结构被定义在include/linux/if_packet.h中,在捕获进程中建立一个不可交换(unswappable)内存的环形缓冲区。通过被映射的内存,捕获进程就可以无需系统调用就可以访问到捕获的报文和报文相关的元信息,像时间戳等。
捕获frame被划分为多个block,每个block是一块物理上连续的内存区域,有tp_block_size/tp_frame_size个frame。block的总数是tp_block_nr。其实tp_frame_nr是多余的,因为我们可以计算出来:
实际上,packet_set_ring检查下面的条件是否正确:
下面我们可以一个例子:
得到的缓冲区结构应该如下:
每个frame必须放在一个block中,每个block保存整数个frame,也就是说一个frame不能跨越两个block。
3. 映射和使用环形缓冲区
在用户空间映射缓冲区可以直接使用方便的mmap()函数。虽然那些buffer在内核中是由多个block组成的,但是映射后它们在用户空间中是连续的。
如果tp_frame_size能够整除tp_block_size,那么每个frame都将会是tp_frame_size长度;如果不是,那么tp_block_size/tp_frame_size个frame之间就会有空隙,那是因为一个frame不会跨越两个block。
在每一个frame的开始有一个status域(可以查看struct tpacket_hdr),这些status定义在include/linux/if_packet.h中:
这里我们只关心前两个,TP_STATUS_KERNEL和TP_STATUS_USER。如果status为TP_STATUS_KERNEL,表示这个frame可以被kernel使用,实际上就是可以将存放捕获的数据存放在这个frame中;如果status为TP_STATUS_USER,表示这个frame可以被用户空间使用,实际上就是这个frame中存放的是捕获的数据,应该读出来。
内核将所有的frame的status初始化为TP_STATUS_KERNEL,当内核接受到一个报文的时候,就选一个frame,把报文放进去,然后更新它的状态为TP_STATUS_USER(这里假设不出现其他问题,也就是忽略其他的状态)。用户程序读取报文,一旦报文被读取,用户必须将frame对应的status设置为0,也就是设置为TP_STATUS_KERNEL,这样内核就可以再次使用这个frame了。
用户可以通过poll或者是其他机制来检测环形缓冲区中的新报文:
先检查状态值,然后再对frame进行轮循,这样就可以避免竞争条件了(如果status已经是TP_STATUS_USER了,也就是说在调用poll前已经有了一个报文到达。这个时候再调用poll,并且之后不再有新报文到达的话,那么之前的那个报文就无法读取了,这就是所谓的竞争条件)。
在libpcap-1.0.0中是这么设计的:
pcap-linux.c中的pcap_read_linux_mmap:
PACKET_MMAP源码分析
这里就不再像上一篇文章中那样大段大段的粘贴代码了,只是分析一下流程就可以了,需要的同学可以对照着follow一下代码;-)
数据包进入网卡后,创建了skb,之后会进入软中断处理,调用netif_receive_skb,并调用dev_add_pack注册的一些func。很明显可以看到af_packet.c中的tpacket_rcv和packet_rcv就是我们找的目标。
tpacket_rcv是PACKET_MMAP的实现,packet_rcv是普通AF_PACKET的实现。
tpacket_rcv:
- 1. 进行些必要的检查
- 2. 运行run_filter,通过BPF过滤中我们设定条件的报文,得到需要捕获的长度snaplen
- 3. 在ring buffer中查找TP_STATUS_KERNEL的frame
- 4. 计算macoff、netoff等信息
- 5. 如果snaplen+macoff>frame_size,并且skb为共享的,那么就拷贝skb <一般不会拷贝>
- 6. 将数据从skb拷贝到kernel Buffer中 <拷贝>
- 7. 设置拷贝到frame中报文的头部信息,包括时间戳、长度、状态等信息
- 8. flush_dcache_page()把某页在data cache中的内容同步回内存。
x86应该不用这个,这个多为RISC架构用的
- 9. 调用sk_data_ready,通知睡眠进程,调用poll
- 10. 应用层在调用poll返回后,就会调用pcap_get_ring_frame获得一个frame进行处理。这里面没有拷贝也没有系统调用。
开销分析:1次拷贝+1个系统调用(poll)
packet_rcv:
- 1. 进行些必要的检查
- 2. 运行run_filter,通过BPF过滤中我们设定条件的报文,得到需要捕获的长度snaplen
- 3. 如果skb为共享的,那么就拷贝skb <一般都会拷贝>
- 4. 设置拷贝到frame中报文的头部信息,包括时间戳、长度、状态等信息
- 5. 将skb追加到socket的sk_receive_queue中
- 6. 调用sk_data_ready,通知睡眠进程有数据到达
- 7. 应用层睡眠在recvfrom上,当数据到达,socket可读的时候,调用packet_recvmsg,其中将数据拷贝到用户空间。 <拷贝>
skb_recv_datagram()从sk_receive_queue中获得skb
skb_copy_datagram_iovec()将数据拷贝到用户空间
开销分析:2次拷贝+1个系统调用(recvfrom)
注:其实在packet处理之前还有一次拷贝过程,在NIC Driver中,创建一个skb,然后NIC把数据DMA到skb的data中。
在另外一些ZeroCopy实现中(例如 ntz),如果不希望NIC数据进入协议栈的话,就可以不用考虑skb_shared的问题了,直接将数据从NIC Driver中DMA到制定的一块内存,然后使用mmap到用户空间。这样就只有一次DMA过程,当然DMA也是一种拷贝;-)
关于数据包如何从NIC Driver到packet_rcv/tpacket_rcv,数据包经过中断、软中断等处理,进入netif_receive_skb中对skb进行分发,就会调用dev_add_pack注册的packet_type->func。
3.5 DPDK
参考:DPDK解析—–DPDK,PF_RING对比
pf-ring zc和dpdk均可以实现数据包的零拷贝,两者均旁路了内核,但是实现原理略有不同。pf-ring zc通过zc驱动(也在应用层)接管数据包,dpdk基于UIO实现。
UIO+mmap 实现零拷贝(zero copy)
UIO(Userspace I/O)是运行在用户空间的I/O技术。Linux系统中一般的驱动设备都是运行在内核空间,而在用户空间用应用程序调用即可,而UIO则是将驱动的很少一部分运行在内核空间,而在用户空间实现驱动的绝大多数功能。
采用Linux提供UIO机制,可以旁路Kernel,将所有报文处理的工作在用户空间完成。

UIO+PMD 减少中断和CPU上下文切换
DPDK的UIO驱动屏蔽了硬件发出中断,然后在用户态采用主动轮询的方式,这种模式被称为PMD(Poll Mode Driver)。
与DPDK相比,pf-ring(no zc)使用的是NAPI polling和应用层polling,而pf-ring zc与DPDK类似,仅使用应用层polling。
HugePages 减少TLB miss
在操作系统引入MMU(Memory Management Unit)后,CPU读取内存的数据需要两次访问内存。第一次要查询页表将逻辑地址转换为物理地址,然后访问该物理地址读取数据或指令。
为了减少页数过多,页表过大而导致的查询时间过长的问题,便引入了TLB(Translation Lookaside Buffer),可翻译为地址转换缓冲器。TLB是一个内存管理单元,一般存储在寄存器中,里面存储了当前最可能被访问到的一小部分页表项。
引入TLB后,CPU会首先去TLB中寻址,由于TLB存放在寄存器中,且其只包含一小部分页表项,因此查询速度非常快。若TLB中寻址成功(TLB hit),则无需再去RAM中查询页表;若TLB中寻址失败(TLB miss),则需要去RAM中查询页表,查询到后,会将该页更新至TLB中。
而DPDK采用HugePages ,在x86-64下支持2MB、1GB的页大小,大大降低了总页个数和页表的大小,从而大大降低TLB miss的几率,提升CPU寻址性能。
其它优化
SNA(Shared-nothing Architecture),软件架构去中心化,尽量避免全局共享,带来全局竞争,失去横向扩展的能力。NUMA体系下不跨Node远程使用内存。
SIMD(Single Instruction Multiple Data),从最早的mmx/sse到最新的avx2,SIMD的能力一直在增强。DPDK采用批量同时处理多个包,再用向量编程,一个周期内对所有包进行处理。比如,memcpy就使用SIMD来提高速度。
cpu affinity
3.6 XDP(eXpress Data Path)
参考:DPDK and XDP
xdp代表eXpress数据路径,使用ebpf 做包过滤,相对于dpdk将数据包直接送到用户态,用用户态当做快速数据处理平面,xdp是在驱动层创建了一个数据快速平面。
在数据被网卡硬件dma到内存,分配skb之前,对数据包进行处理。

请注意,XDP并没有对数据包做Kernel bypass,它只是提前做了一点预检而已。
相对于DPDK,XDP具有以下优点:
- 无需第三方代码库和许可
- 同时支持轮询式和中断式网络
- 无需分配大页
- 无需专用的CPU
- 无需定义新
来源:confirmwz
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!