文章目录
-
- 一、线程池的自我介绍
- 二、线程增减的时机
- 三、线程存活时间和工作队列
-
- 1、线程存活时间
- 2、工作队列
- 四、自动创建线程池的风险与常见线程池的用法展示
-
- 1、FixedThreadPool
- 2、SingleThreadExecutor
- 3、CachedThreadPool
- 4、ScheduledThreadPool
- 5、对比各大线程池的特点
- 五、如何正确关闭线程池
- 六、暂停和恢复线程池
- 七、线程池实现复用的原因
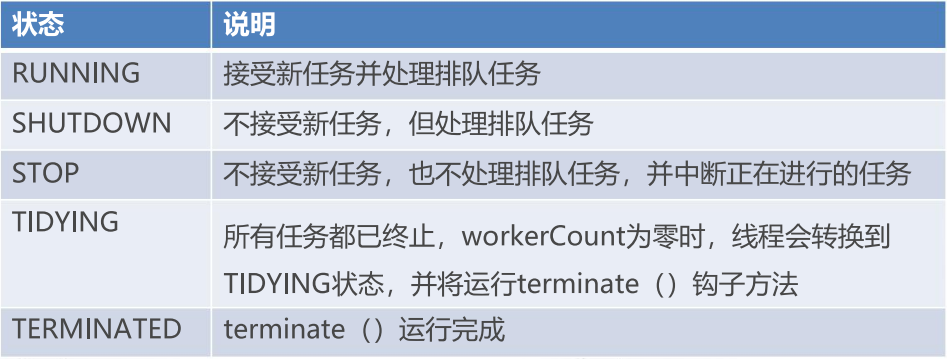
- 八、线程池状态、使用注意点和总结
- 九、关于ReentrantLock和Conditon
一、线程池的自我介绍
什么是”线程”/strong>
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
什么”池”/strong>
软件中的池,可以理解为计划经济
线程池:
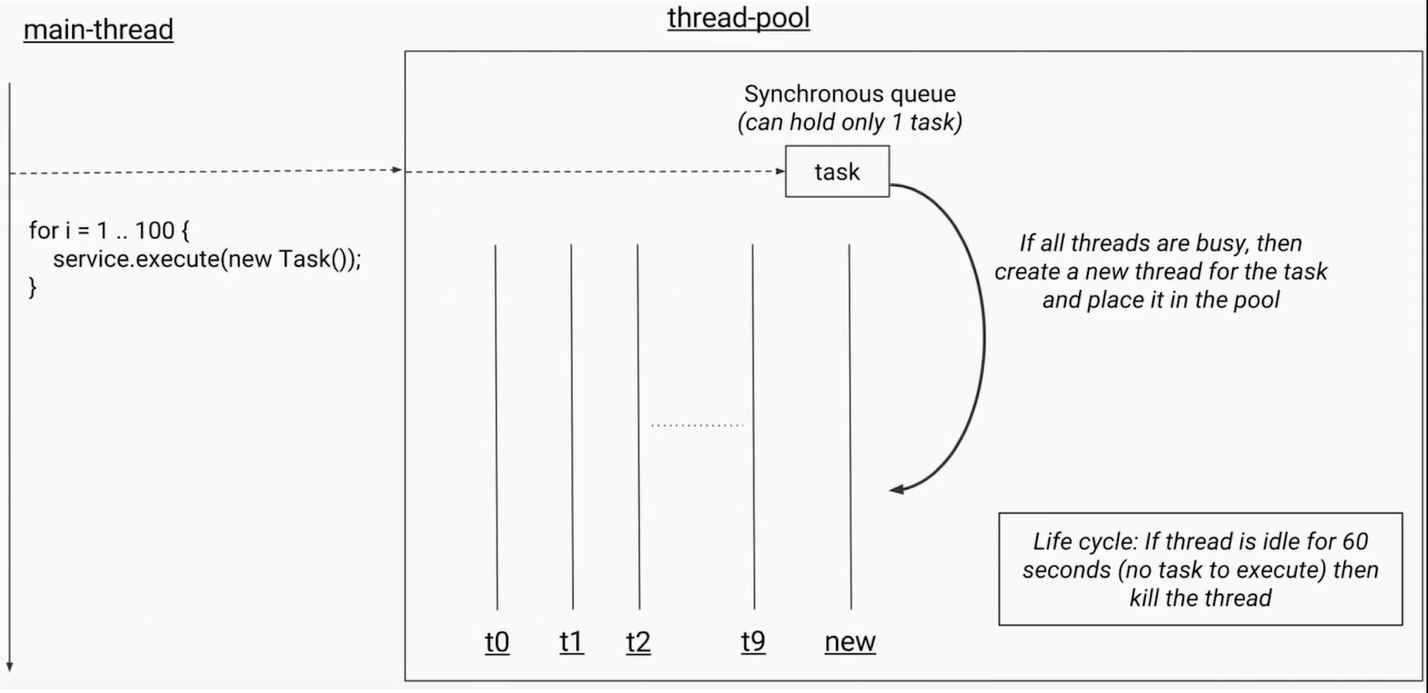
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。如果某个线程在托管代码中空闲(如正在等待某个事件),则线程池将插入另一个辅助线程来使所有处理器保持繁忙。如果所有线程池线程都始终保持繁忙,但队列中包含挂起的工作,则线程池将在一段时间后创建另一个辅助线程但线程的数目永远不会超过最大值。超过最大值的线程可以排队,但他们要等到其他线程完成后才启动。
如果不使用线程池,每个任务都新开一个线程处理
一个线程:
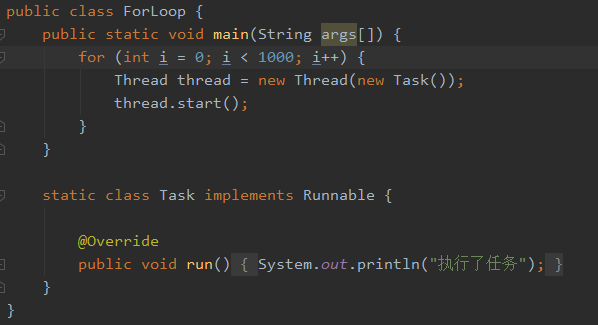

这样开销太大,我们希望有固定数量的线程,来执行这1000个线程,这样就避免了反复创建并销毁线程所带来的开销问题
为什么要使用线程池/strong>
问题一:反复创建线程开销大br> 问题二:过多的线程会占用太多内存br> 解决以上两个问题的思路
用少量的线程——避免内存占用过多
让这部分线程都保持工作,且可以反复执行任务——避免生命周期的损耗
线程池的好处:
加快响应速度
合理利用CPU和内存
统一管理
线程池适合应用的场合:
服务器接收到大量请求时,使用线程池技术是非常合适的,它可以大大减少线程的创建和销毁次数,提高服务器的工作效率
实际上,在开发中,如果需要创建5个以上的线程,那么就可以使用线程池来管理
二、线程增减的时机
线程池构造方法的参数:
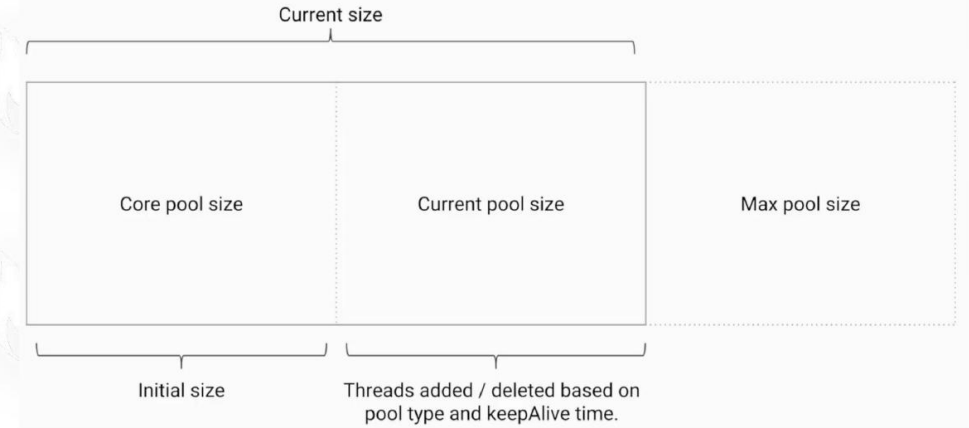
添加线程规则:
1.如果线程数小于corePoolSize,即使其他工作线程处于空闲状态,也会创建一个新线程来运行新任务。
2.如果线程数等于(或大于) corePoolSize但少于maximumPoolSize,则将任务放入队列。
3.如果队列已满,并且线程数小于maxPoolSize,则创建一个新线程来运行任务。
4.如果队列已满,并且线程数大于或等于maxPoolSize,则拒绝该任务。
示意图:
2、工作队列
有3种最常见的队列类型:
1)、直接交接:SynchronousQueue
SynchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
拥有公平(FIFO)和非公平(LIFO)策略,非公平侧罗会导致一些数据永远无法被消费的情况br> 使用SynchronousQueue阻塞队列一般要求maximumPoolSizes为无界,避免线程拒绝执行操作。
2)、无界队列:LinkedBlockingQueue
指的是没有设置固定大小的队列。这些队列的特点是可以直接入列,直到溢出。当然现实几乎不会有到这么大的容量(超过 Integer.MAX_VALUE),所以从使用者的体验上,就相当于 “无界”。比如没有设定固定大小的 LinkedBlockingQueue。
常见的无界队列为:
I、ConcurrentLinkedQueue 无锁队列,底层使用CAS操作,通常具有较高吞吐量,但是具有读性能的不确定性,弱一致性——不存在如ArrayList等集合类的并发修改异常,通俗的说就是遍历时修改不会抛异常
II、PriorityBlockingQueue 具有优先级的阻塞队列
III、DelayedQueue 延时队列,使用场景
缓存:清掉缓存中超时的缓存数据
任务超时处理
补充:内部实现其实是采用带时间的优先队列,可重入锁,优化阻塞通知的线程元素leader
IV、LinkedTransferQueue 简单的说也是进行线程间数据交换的利器,在SynchronousQueue 中就有所体现,并且并发大神 Doug Lea 对其进行了极致的优化,使用15个对象填充,加上本身4字节,总共64字节就可以避免缓存行中的伪共享问题,其实现细节较为复杂,可以说一下大致过程:
比如消费者线程从一个队列中取元素,发现队列为空,他就生成一个空元素放入队列 , 所谓空元素就是数据项字段为空。然后消费者线程在这个字段上旅转等待。这叫保留。直到一个生产者线程意欲向队例中放入一个元素,这里他发现最前面的元素的数据项字段为 NULL,他就直接把自已数据填充到这个元素中,即完成了元素的传送。大体是这个意思,这种方式优美了完成了线程之间的高效协作。
3)、有界的队列: ArrayBlockingQueue
就是有固定大小的队列。比如设定了固定大小的 LinkedBlockingQueue,又或者大小为 0,只是在生产者和消费者中做中转用的 SynchronousQueue。
常见的有界队列为:
I、ArrayBlockingQueue 基于数组实现的阻塞队列
II、LinkedBlockingQueue 其实也是有界队列,但是不设置大小时就是无界的。
ArrayBlockingQueue 与 LinkedBlockingQueue 对比:ArrayBlockingQueue 实现简单,表现稳定,添加和删除使用同一个锁,通常性能不如后者;LinkedBlockingQueue 添加和删除两把锁是分开的,所以竞争会小一些
III、SynchronousQueue 比较奇葩,内部容量为零,适用于元素数量少的场景,尤其特别适合做交换数据用,内部使用 队列来实现公平性的调度,使用栈来实现非公平的调度,在Java6时替换了原来的锁逻辑,使用CAS代替了。
四、自动创建线程池的风险与常见线程池的用法展示
手动创建更好,因为这样可以更加明确线程池的运行规则,避免资源耗尽的风险
自动创建线程池(即直接调用JDK封装好的构造方法)可能带来哪些问题/p>
1、FixedThreadPool
线程池应该手动创建还是自动创建/strong>
newFixedThreadPool先看看具体实验操作:

看结果会发现始终是1、2、3、4不会超过4,所以我们来看看源码
可以看其源码:
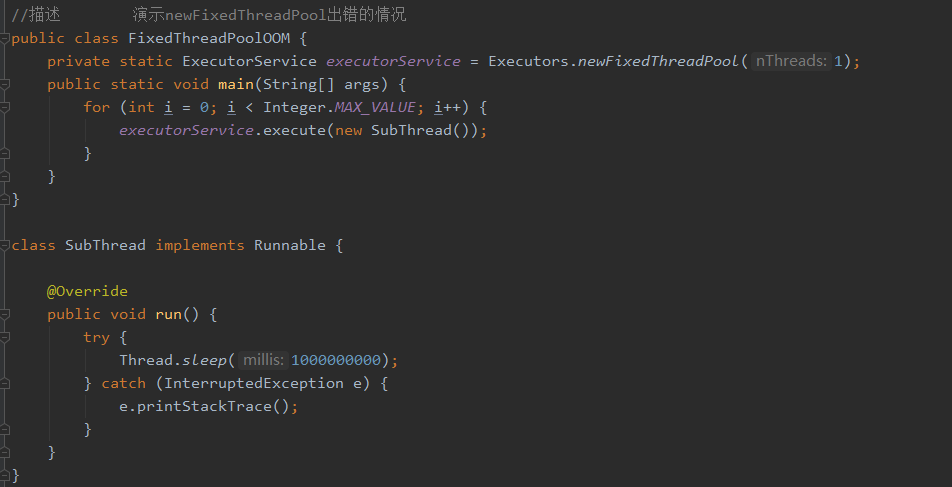
因为我们需要快速的看出溢出的效果,所以需要去更改一下内存的大小:

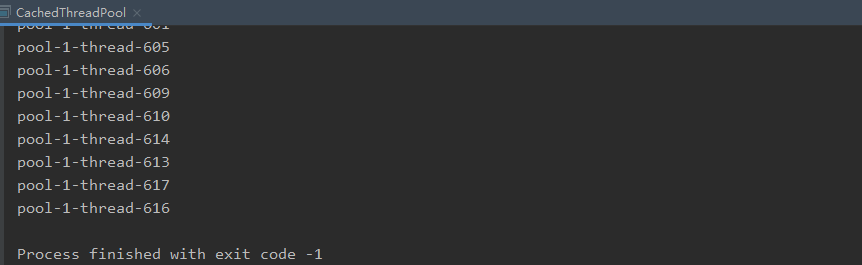
2、SingleThreadExecutor
newSingleThreadExecutor

看看源码:
代码演示:
源码:

每隔三秒打印一次:

原因和newCachedThreadPool一样
正确的创建线程池的方法:
根据不同的业务场景,设置线程池参数
比如:内存有多大,给线程取什么名字等等
线程池里的线程数量设定为多少比较合适/strong>
CPU密集型(加密、计算hash等):最佳线程数为CPU核心数的1-2倍左右。
耗时IO型(读写数据库、文件、网络读写等)︰最佳线程数一般会大于CPU核心数很多倍
参考Brain Goetz推荐的计算方法:
线程数=CPU核心数*(1+平均等待时间/平均工作时间)
5、对比各大线程池的特点
FixedThreadPool:

他会把任务交付给线程,线程不够用呢就会新建线程,线程过多就会回收线程
ScheduledThreadPool:
支持定时及周期性任务执行的线程池
SingleThreadExecutor:
单线程的线程池:只会用唯一的工作线程来执行任务
原理和FixedThreadPool是一样的,但是此时的线程数量被设置为了1
以上4中线程池的构造方法的参数
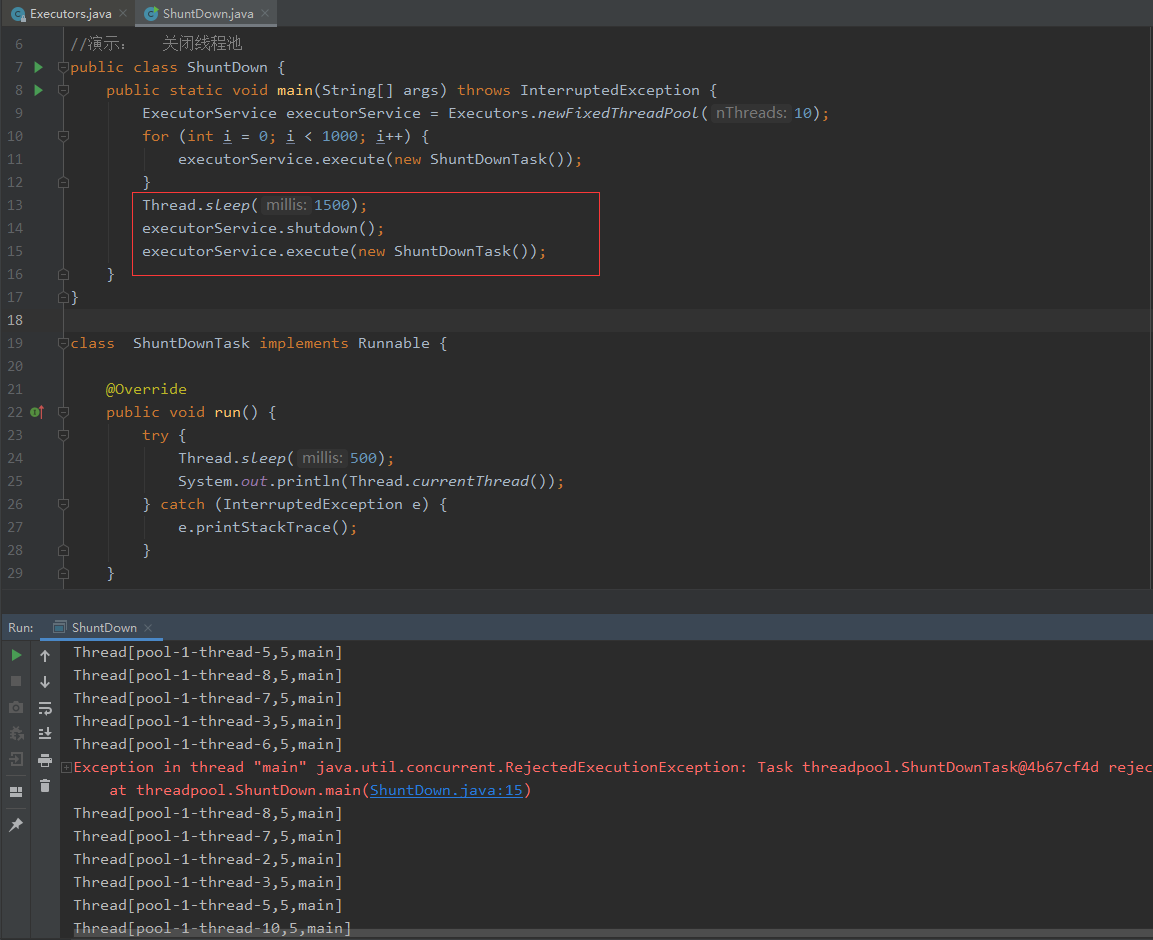
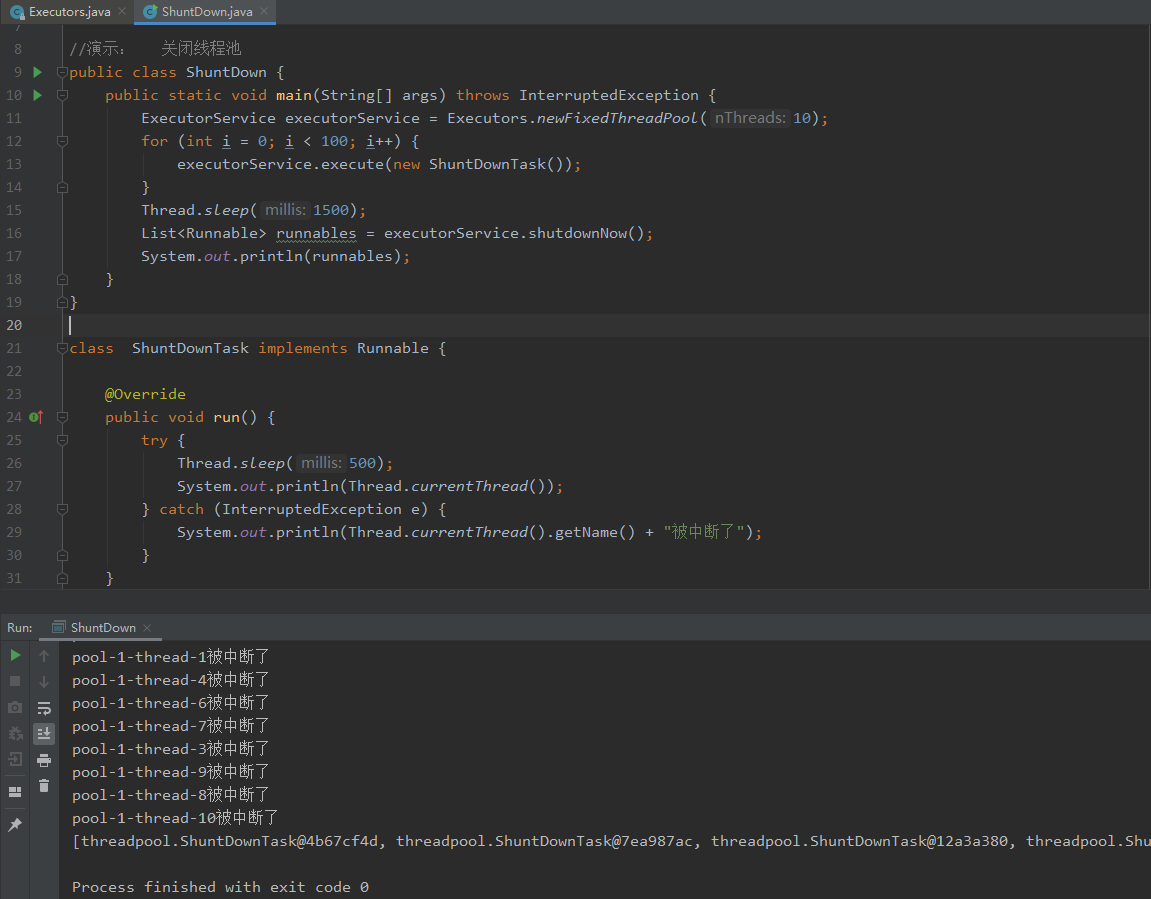
可以看出在1.5秒后启动了关闭线程池,但在停之前的线程中运行着的任务和队列中等待运行的任务都还会继续运行,所以shutdown是一个很绅士的关闭线程池。
2、isShutdown
可以返回一个布尔值来告诉我们这个线程池是否停止了,这个停止不是完全停止而是表示这个线程池是否进入一个停止的状态。
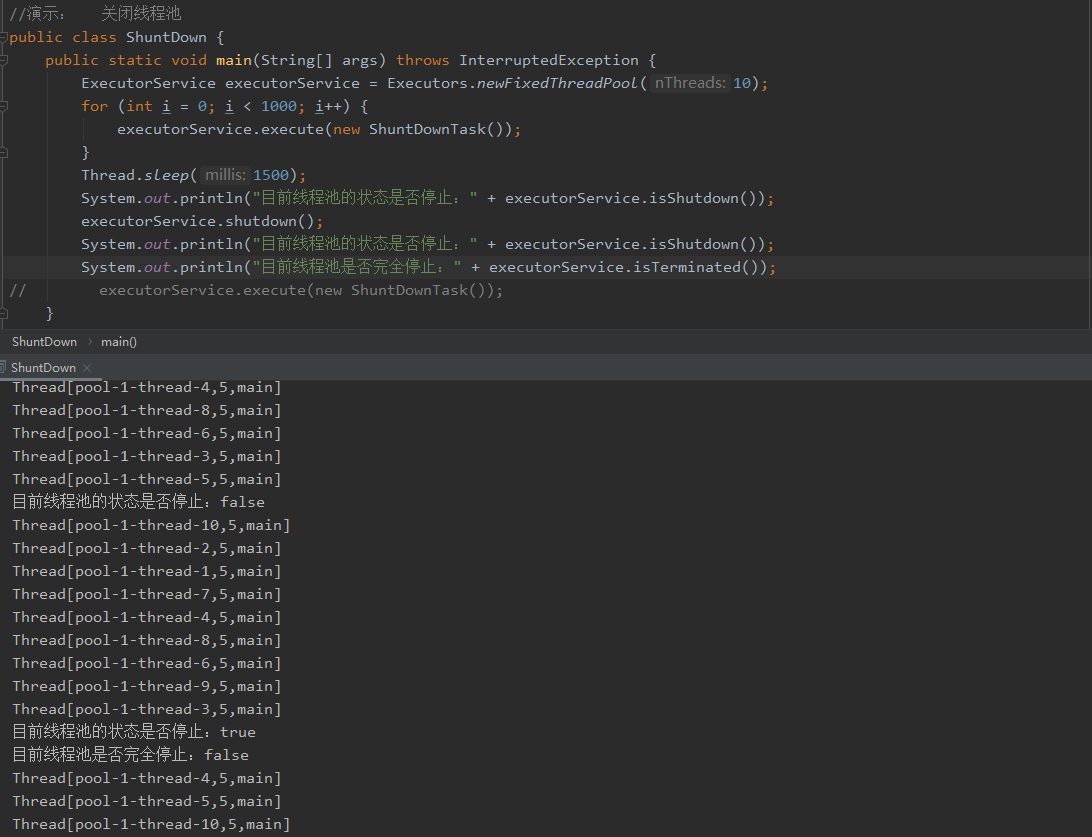
4、awaitTermination
等待一段时间,执行完毕就返回一个布尔值true,反之false(主要作用是用于检查)。
六、暂停和恢复线程池
任务太多,怎么拒绝/strong>
拒绝时机
1.当Executor关闭时,提交新任务会被拒绝。
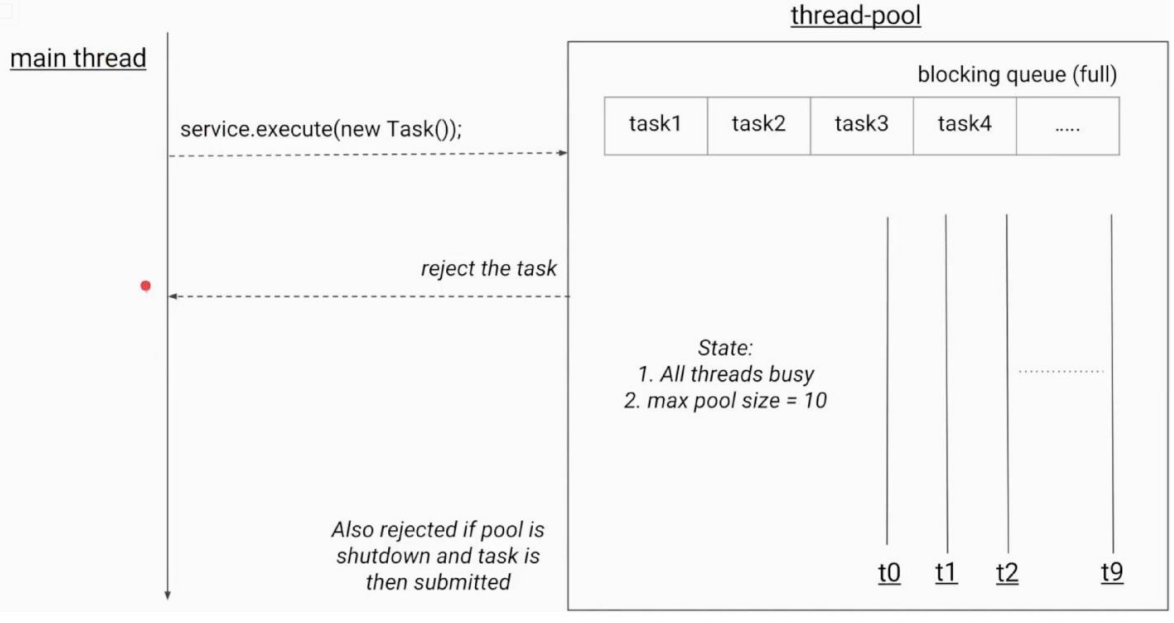
4种拒绝策略
AbortPolicy
像刚才那样直接抛出异常
DiscardPolicy
默默的把任务丢弃,不会通知
DiscardOldestPolicy
丢弃最老的任务,也就是存在时间最久的
CallerRunsPolicy
提交者自己运行,主线程运行,避免了业务损失
钩子方法:
钩子函数,通俗地将也就是父类定义的一些空实现的方法,子类通过实现这些方法,在程序运行的声明周期中的某个阶段来回调这些方法,实现我们自定义的功能。
每个任务执行前后
日志、统计
代码演示:

七、线程池实现复用的原因
实现原理、源码分析
线程池组成部分
——线程池管理器:用于创建并管理线程池
——工作线程:线程池中线程
——任务队列:用于存放没有处理的任务,提供一种缓冲机制
——任务接口( Task):每个任务必须实现的接口,以供工作线程调度任务的执行
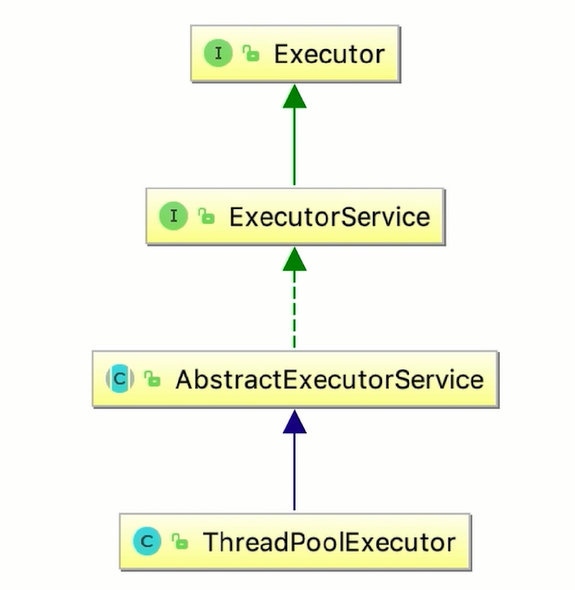
查看源码:
Executor:
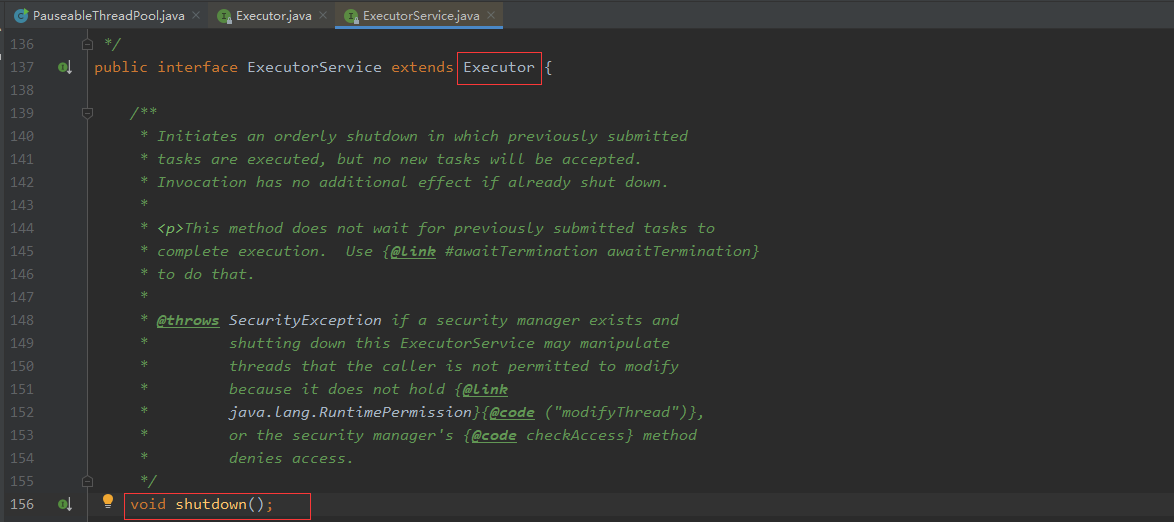
Executors(主要是一个工具类):
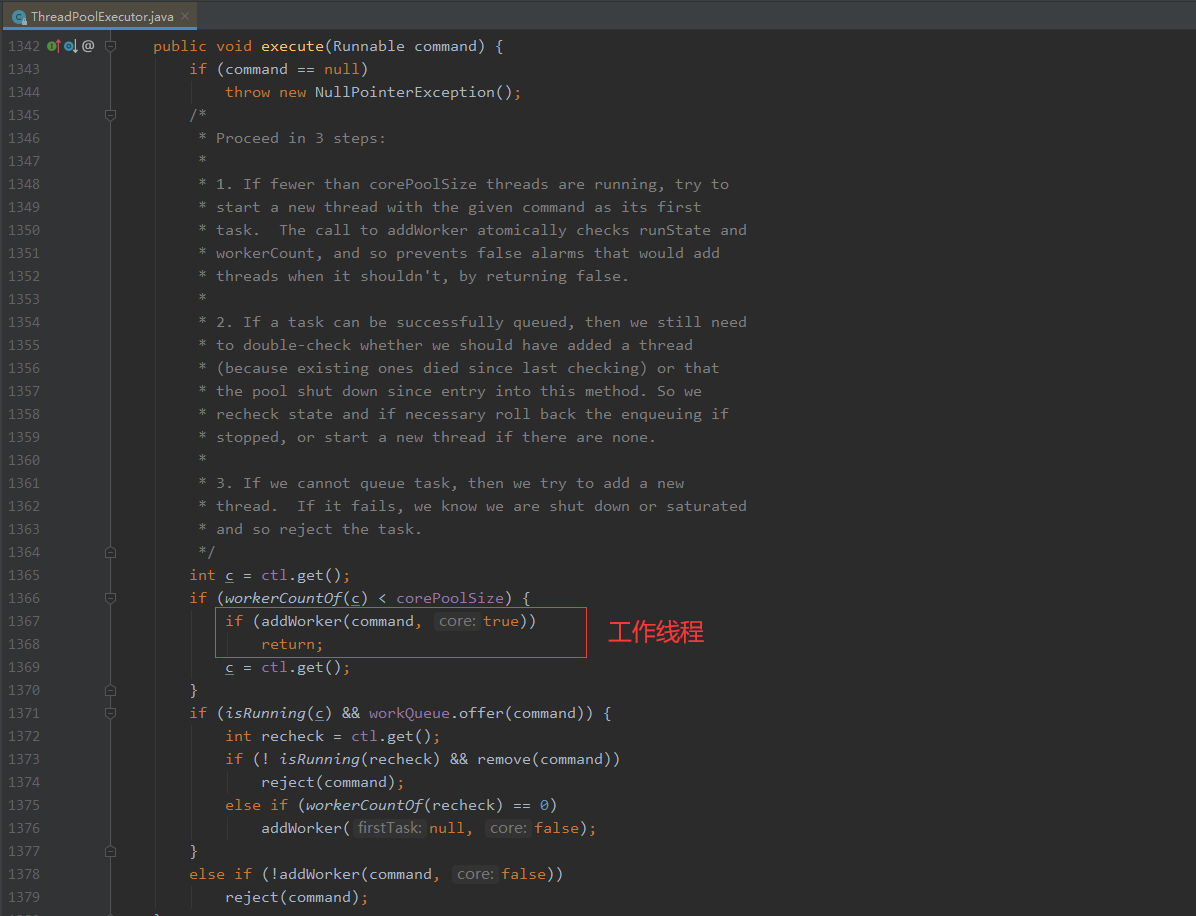
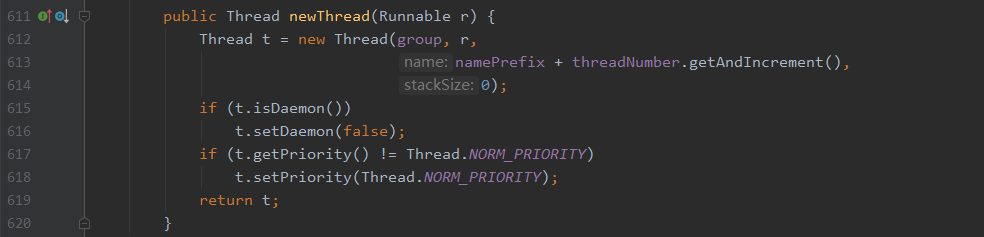
假如当我们的线程小于corePoolSize就加一个线程addWorker,可以看看addWorker,
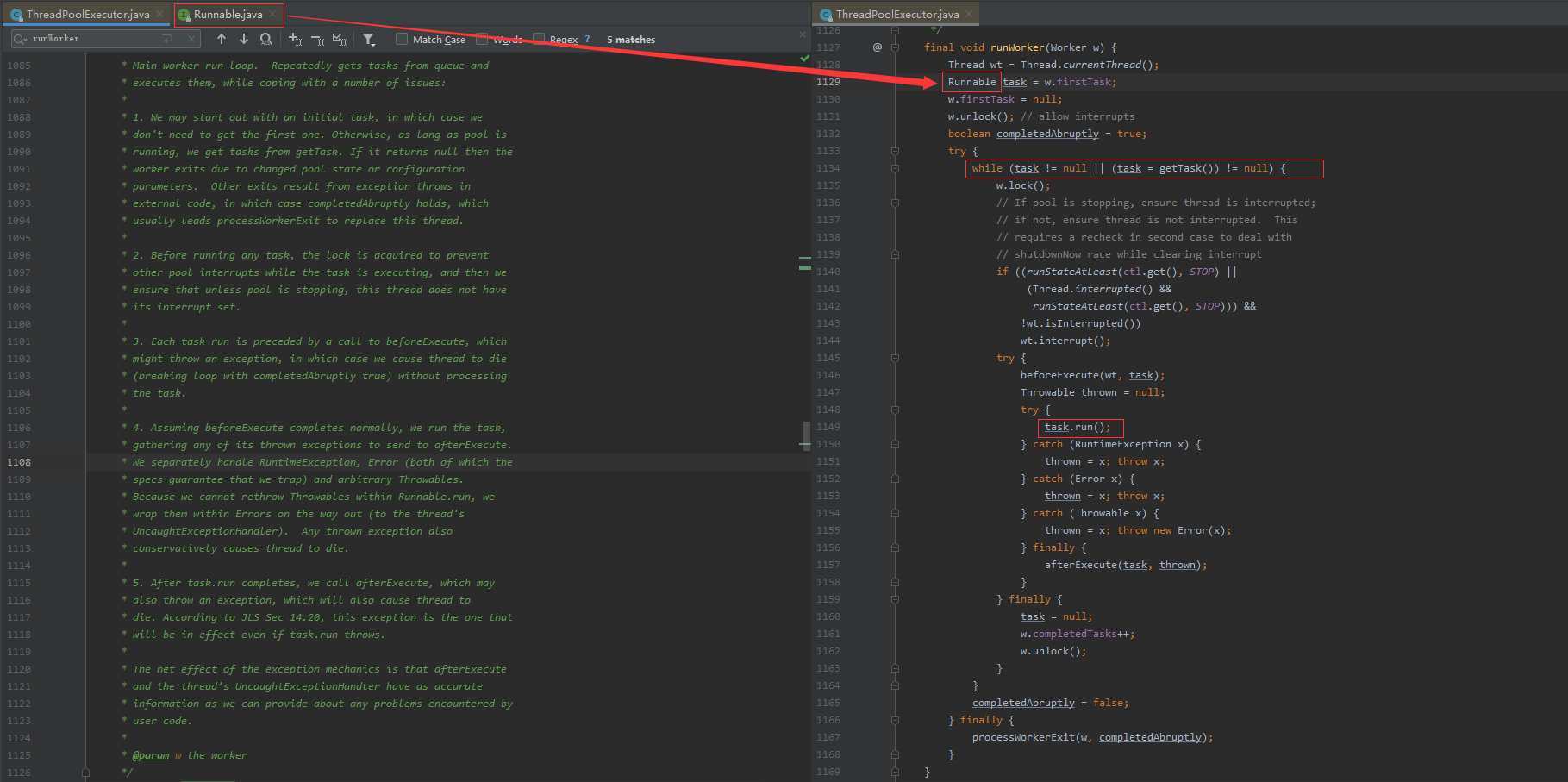
这个方法便把我们怎么实现线程复用的内容描述出来了
这个方法大概提炼一下的意思是: 首先拿到一个Runable的task任务,而while循环就是只要这个任务不为空或者是我拿到的这个任务不为空我便执行这个方法,而while里面关键的就是task.run(),而task的类是Runable,而Runable的run方法是:
也可以查看源码:
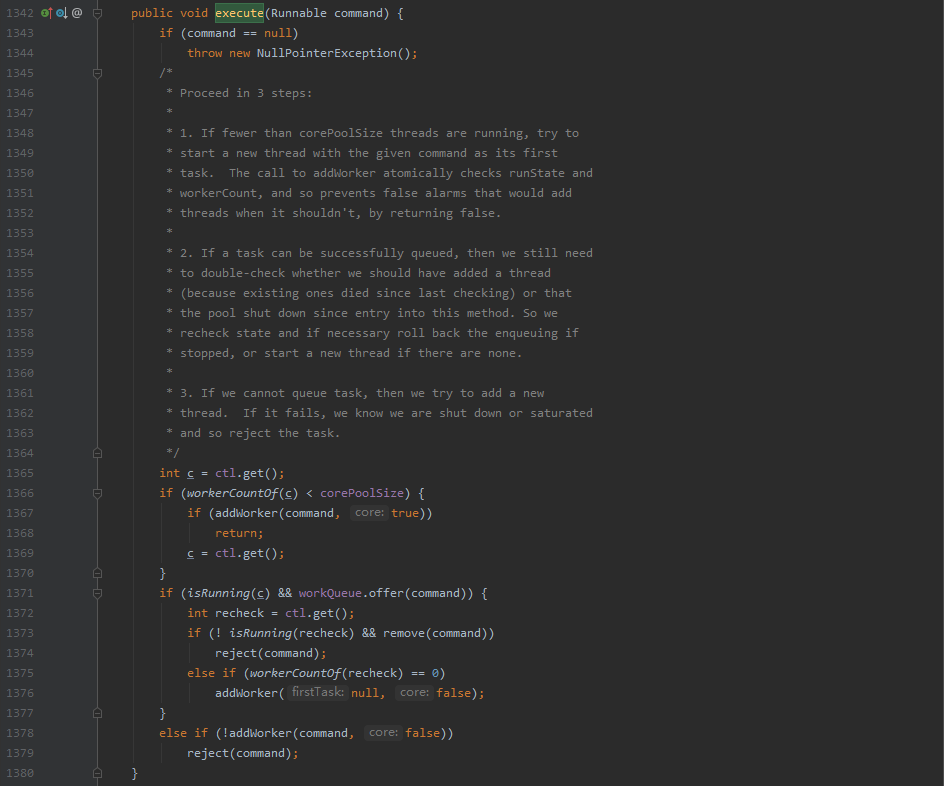
这段源码大概解析是:这个方法主要分为三步,首先先接收到command命令不为空然后继续执行,取ctl(记录了线程状态和线程数),假如现在的线程数(workerCountOf小于核心数(corePoolSize)的话,就创建一个线程,而addWorker方法有两个参数command(即将执行的任务)、true(增加的线程数是否小于core及小于核心的数量),假如传的是false则是是否小于最大的数量;假如大于等于核心数量跳过了这个if,则在下一个if则是先检查线程池是不是正在运行的状态(isRunning,如果是的话就传到我们的工作队列中,而在此期间呢有可能线程已经终止了,所以要在做一次检查判断这个线程是否还在运行,如果不运行则会把任务删掉并拒绝(reject(command)),而workerCountOf表示现在执行的线程有多少判断是否为零,为什么会判断等于0呢为我们的线程有可能会抛异常导致这个线程停止了,这个线程有可能会减少的,如果减少的时候为0的话,还是需要进行创建一个线程的来执行;最后如果说能运行到最后一个else if则会判断是否可以增加最大数量的一个线程,如果还能加就继续加,不能则拒绝,大概就这个样子ヾ(
使用线程池的注意点:
避免任务堆积
避免线程数过度增加
排查线程泄漏
和ThreadLocal配合九、关于ReentrantLock和Conditon
ReentrantLock是Java中一种常见的“锁”,锁是什么/strong>
并发编程的时候,比如说有一个业务是读写操作,那多个线程执行这个业务就会造成已经写入的数据又写一遍,就会造成数据错乱。
所以需要引入锁,进行数据同步,强制使得该业务执行的时候只有一个线程在执行,从而保证不会插入多条重复数据。
一些共享资源也是需要加锁,从而保证数据的一致性。
使用Condition实现线程等待和唤醒,通常在开发并发程序的时候,会碰到需要停止正在执行业务A,来执行另一个业务B,当业务B执行完成后业务A继续执行。ReentrantLock通过Condtion等待/唤醒这样的机制。
对线程池的学习就到这里,倘若我解释有误,望评论区指正,Thanks/strong>
来源:一个爱运动的程序员
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!