作者 | 江贺
整理 | Hana
作者简介:
江贺,大连理工大学软件学院教授,博士生导师,研究领域:智能软件工程(软件大数据处理、编译系统测试、工业软件测试)
个人主页:http://faculty.dlut.edu.cn/jianghe/zh_CN/index.htm
本次技术分享来自 SIG-编程语言测试技术沙龙,本文内容为提取讲演视频后的文章,视频也已经发布在 B 站,欢迎大家点开学习。
小程序,


哔哩哔哩,,编译器优化故障的测试与定位小程序
# Introduction #
今天想分享的主题是 编译器故障的检测和定位。
当前编译器的发展现状如下图示,大家可以看出编译器的发展趋势正在由通用型转向领域特定型。
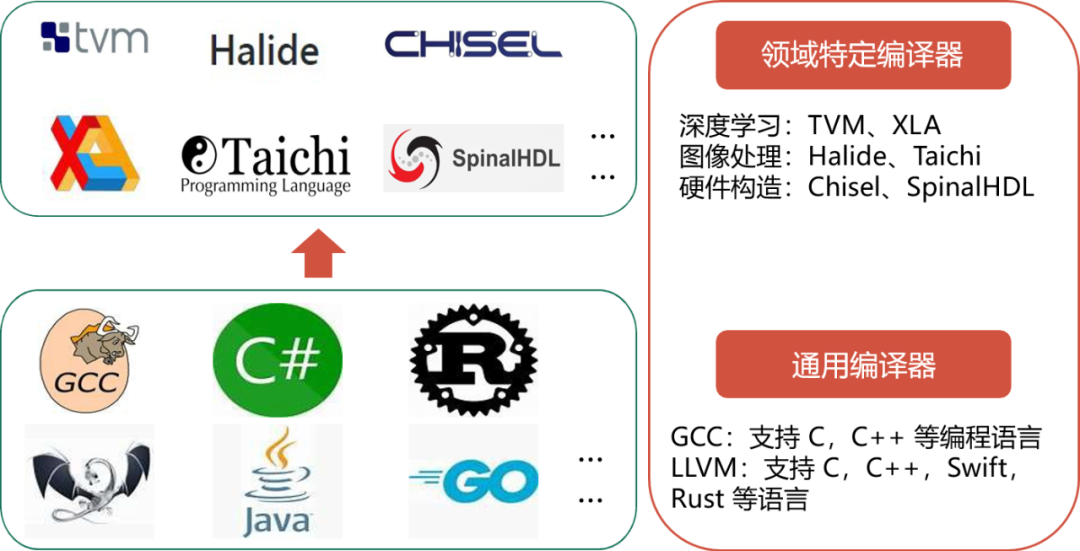
编译环境发展现状
但是我们分析发现,这些编译器实际上依旧占据着主流的应用市场:

主流编译器流行度 —— 以 C/C++ 编译器为例
国内也涌现出很多的编译器:

国产编译器
神威睿智编译器 基于申威指令系统开发 [1] 了基于 GCC 和 Open64 的产品编译器,以及针对国产主机的二进制翻译系统(PowerPC/X86);
龙芯中科 也有基于自有架构后端定制了优化的编译器,包括基于 GCC 和 Open64 的产品编译器,以及 DigitalBridge 进程级二进制翻译系统(X86);
寒武纪 [2] 针对 AI 构建了自己的编译工具链,包括 CNCC(寒武纪 BANG C 语言编译器,基于 Clang 和 LLVM 开发)和 CNAS(寒武纪 MLISA 语言编译器);
华为也推出了自研的方舟编译器 [3]。

编译器的质量会大大影响其使用和流行程度,因此在做编译器的过程中,编译器的质量是一个非常重要的要求。
确保编译器的质量有两种方式:第一种方式就是做 可信验证,这种方式的好处在于它理论上是可以完全保证编译器质量的(如 CompCert [4]),但是无法规模化应用;更常用的办法是 对编译器做测试,虽然无法保证完备性,但它可以大规模化。
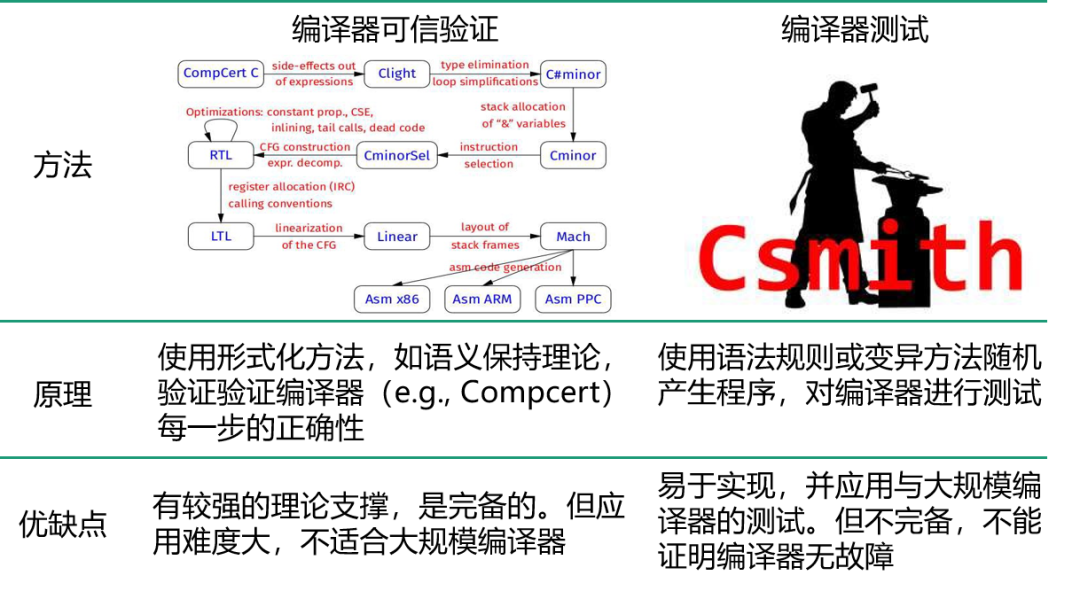
编译器可信验证 vs. 编译器测试
# 编译器测试
编译器测试一般会有三个阶段,
-
测试用例生成 如何生成测试用例来触发编译器故障
-
Test Oracle 问题 即测试准则问题 [5]。当输入测试用例后,编译器产生的输出与我们的预期输出是否一样
-
测试用例约减 当我们发现了一个编译器的故障后,广州房评通常来讲测试用例可能会很长,但是要提交给社区时,必须做一些相关的约减,将测试用例减到方便开发者阅读和定位的范围内(比如 20 行左右)。
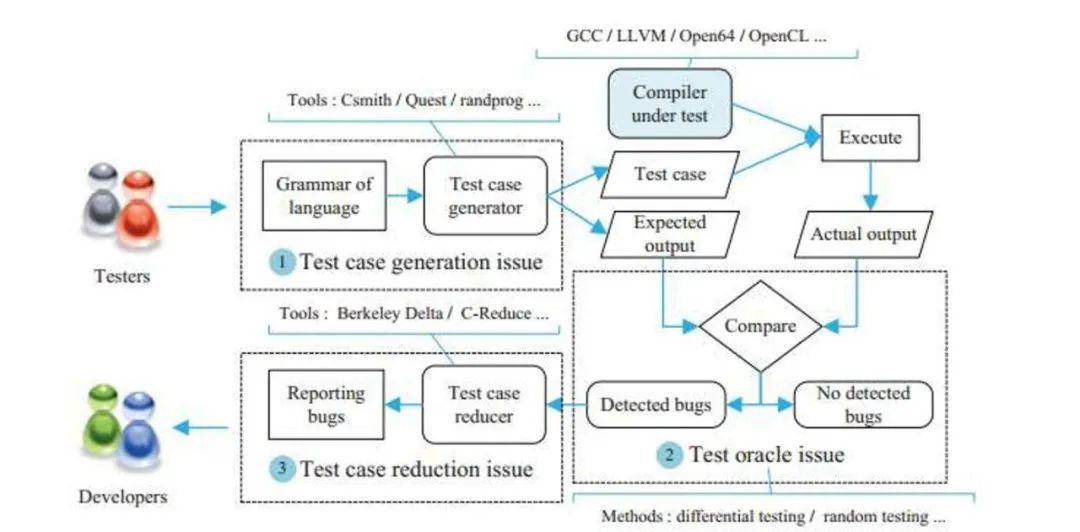
编译器测试的一般流程
## 编译器测试的主要方法
这里简单介绍一下三种主流编译器测试技术:
Random Differential Testing (RDT) 即随机差异测试。简单说,就是用同个编程语言的不同的编译器(比如 GCC 和 LLVM)来进行比较,若编译器的行为不一致,则表示至少其中一个编译器是存在故障的。
Different Optimization Levels (DOL) 即优化级别测试。是 RDT 的一个变种,具体方法是对比同一个编译器的不同优化等级,若行为不一致,则表示至少有一种编译器优化存在故障。
Equivalent Modulo Inputs (EMI) [6] 即等价取模测试,由 UC Davis 的苏振东教授团队提出。EMI 的方法与 RDT 等不同,是对程序进行变换,然后观察被测编译器,是否会跑出不同的结果。
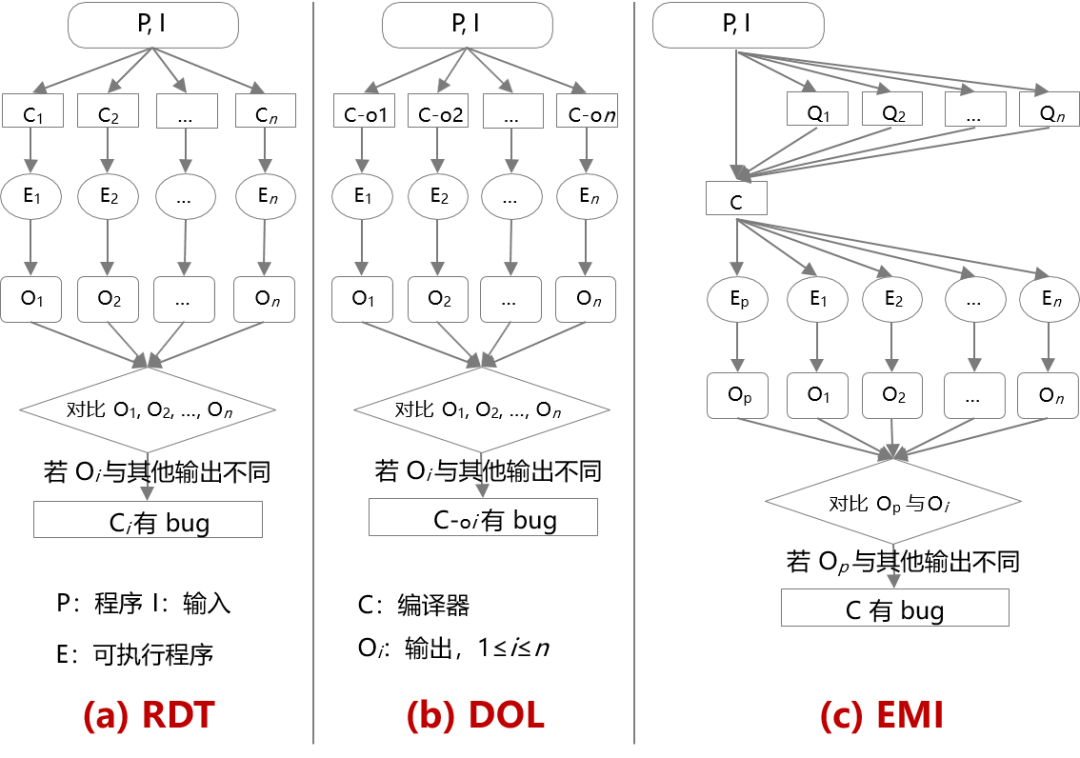
编译器测试的主要方法
# 编译器架构
编译器可以分为前端、中间层及后端。业界对编译器中间这一层的分析和测试比较多,针对前端和后端的分析测试在学术界相对不是特别多。工业界也是如此,由于后端架构的多样,中间代码到指令集的翻译需要适配不同的架构,这个过程需要很严肃的测试是否有故障;另外,像 LLVM 编译器的中间优化大概有 150 多个,丰告网GCC 大概有 250 个,中间优化对传统编译器来说是相当重要的一部分,同时也是出现故障可能性很大的一部分。
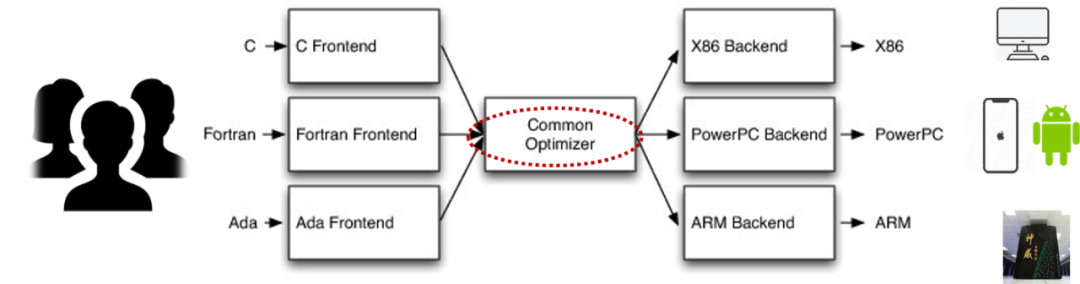
典型的编译器架构
正确地使用编译器优化对程序的性能(如执行速度、代码大小、功耗等)会有显著影响。
编译器优化对工业界的应用十分有意义,当你选择比较好的优化,包括优化的序列时,对程序最后的输出会有很大影响。比如通过编译器优化,甚至可以改进给定程序编译后的大小,程序执行速度,功耗等。对于嵌入式行业来说,代码的大小分分钟会影响到增减一个芯片的问题,所以优化带来的这些收益对于工业界是十分关键的。
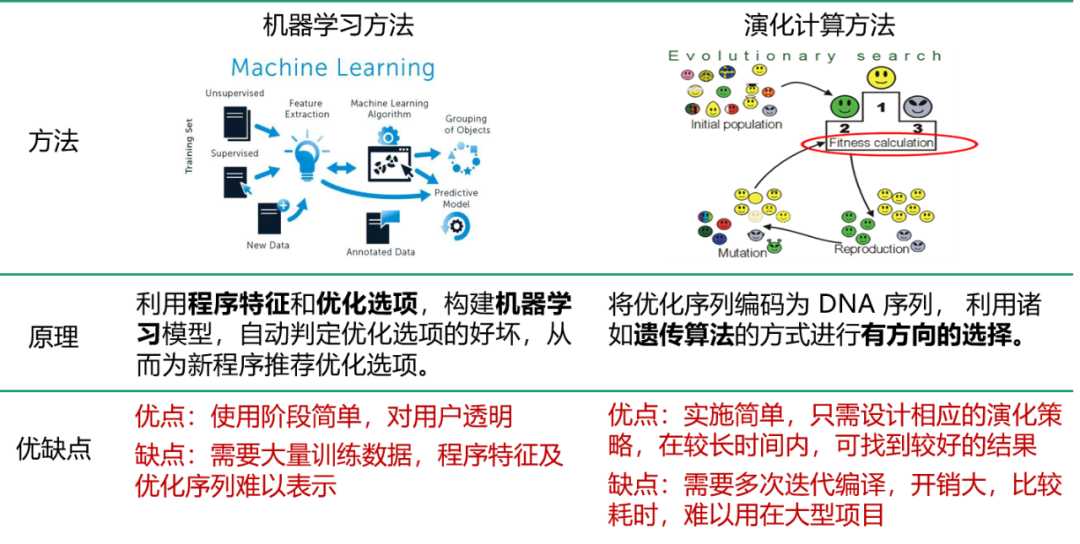
编译优化选择(Phase Ordering Problem)
有关编译优化的选择,业界当前有两类主要的方法(如上图示):
-
第一种是 机器学习方法,即找出一些示例程序,结合不同的编译器优化序列,从而构建出训练样本,输入给算法进行学习;
-
另外一种是 演化计算方法,不需要有训练集,给定一个程序,将对其进行的优化序列编码为一个解,然后对优化序列进行交叉编译来迭代。
讲完前面一些背景之后,接下来简单介绍一下我们团队做的几个方面的工作。
# 编译器警告缺陷检测 – DIPROM #
编译器警告缺陷,即由警告缺失、错误、冗余等而导致的编译器警告缺陷。给一个程序,这个程序有可能最后能够成功地进行编译,但代码里面也可能会存在一些警告信息,说明程序里存在的一些风险。
要做编译器警告测试,有两个挑战:
如何构造警告敏感的程序结构/strong>首先,我们希望可以构造出一些有潜在错误的测试用例,能够尽可能触发编译器的警告。这是编译器警告测试的关键问题。

如何构造多样化的警告敏感程序/strong>第二,构造的时候我们还需要考虑程序如何能够触发多样化的警告,从而又快又好地发现编译器警告有关的故障。这个环节可以加速编译器警告缺陷的检测。

编译器警告缺陷检测的几种方法有:
-
Epiphron [7],由加拿大滑铁卢大学孙诚年老师 2016 年发表的编译器警告检测工作。
-
HiCOND [8] 作为一个编译器缺陷检测通用框架,也可以应用在警告缺陷检测。
-
DIPROM [9] 是我们团队今年刚发表在 IEEE 的工作。
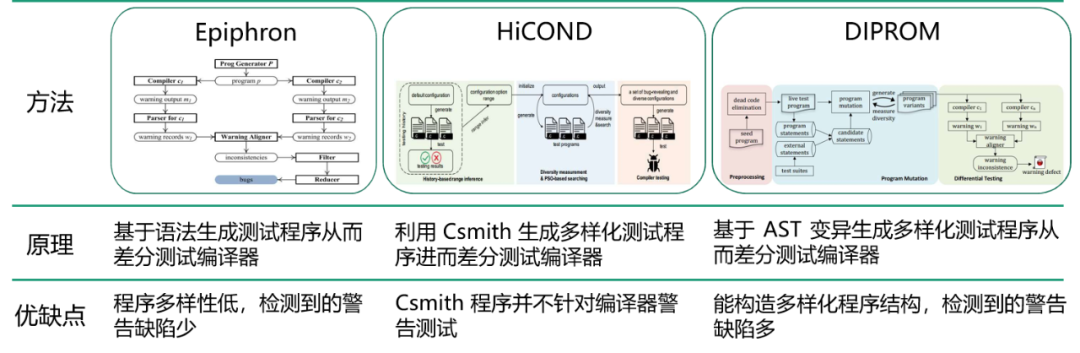
编译器警告缺陷检测的几种方法
# DIPROM 介绍
DIPROM,全称是 DIversity-guided PROgram Mutation,其基本想法是通过对抽象语法树进行变异,构造具有不同警告敏感结构的测试用例。如下图所示,DIPROM 主要分为三个步骤:
给定一个种子程序,
1. 预处理由于死代码通常对编译器警告相关的测试帮助比较小,因此在预处理阶段 DIPROM 会消除掉种子程序中的所有死代码(这时的程序即活测试程序)。
2. 程序变异在活测试程序的 AST 结构上,DIPROM 会进行下面两类操作,从而对程序进行变异(当然这两个操作需要保证程序的语法等还是可正常进行编译的),在变异过程中进行多样性引导。
-
Pruning Operation 即在 AST 上做一些剪枝的操作
-
Inserting Operation 从其他的代码里面挪一些程序结构插到种子程序里

DIPROM 框架
在程序变异过程中,变异因子(Inserting/Pruning)的选择会对检测效果有影响。因此我们引入了一个算法(MCMC (Markov Chain Monte Carlo) Sampling Method)来对不同的变异策略的执行频率和构造的测试用例的多样性等做抉择:
-
每个变异因子被选择之后计算它的分数,并根据分数排序,生成变异因子的排序列表:
-
假设前一次变异因子是 ,当前选择的变异因子是 ,判断 是否用于当前变异的依据是:如果 在排序列表中的位置比 靠前(即 ),则接受当前变异因子;否则, 仍有 的概率被接受用于当前的变异。
3. 差分测试变异之后,将测试用例输入到不同编译器中进行差分测试,对比警告信息的一致性。
# 实验评估
我们将 DIPROM 与已有方法进行了对比分析。
## RQ1: DIPROM 相对于已有的算法是否能检测出更多的编译器警告缺陷/p>
对比 Epiphron, HiCOND 和 Hermes 来分析 DIPROM 在检测警告缺陷的有效性。实验结果表明,DIPROM 优于对比算法:分别提高 HiCOND,Epiphron 和 Hermes 算法 76.74%,34.30% 和 18.93%。

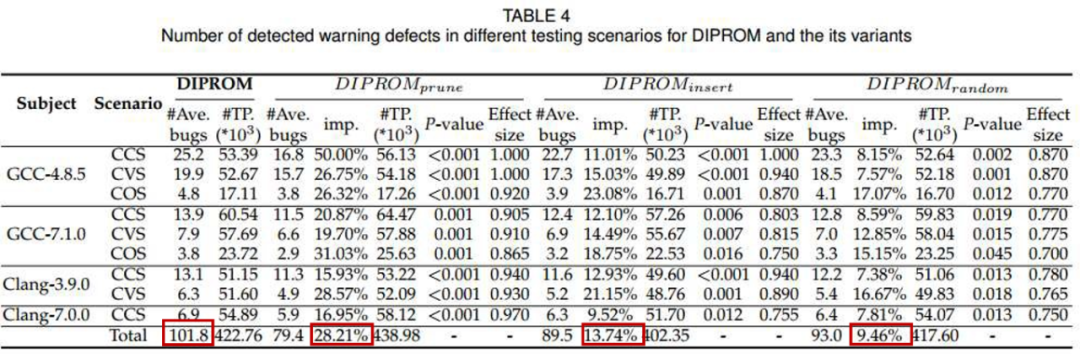
## RQ2: DIPROM 中的变异操作和多样性引导算法是否有助于找到编译器警告缺陷/p>
我们设计了三个变体来分别分析 删除操作、插入操作、以及 多样性引导 对 DIPROM 在检测警告缺陷的有效性。实验结果表明,DIPROM 优于变体算法:分别提高 DIPROMprune,DIPROMinsert 和 DIPROMrandom 算法 28.21%,13.74% 和 9.46%。
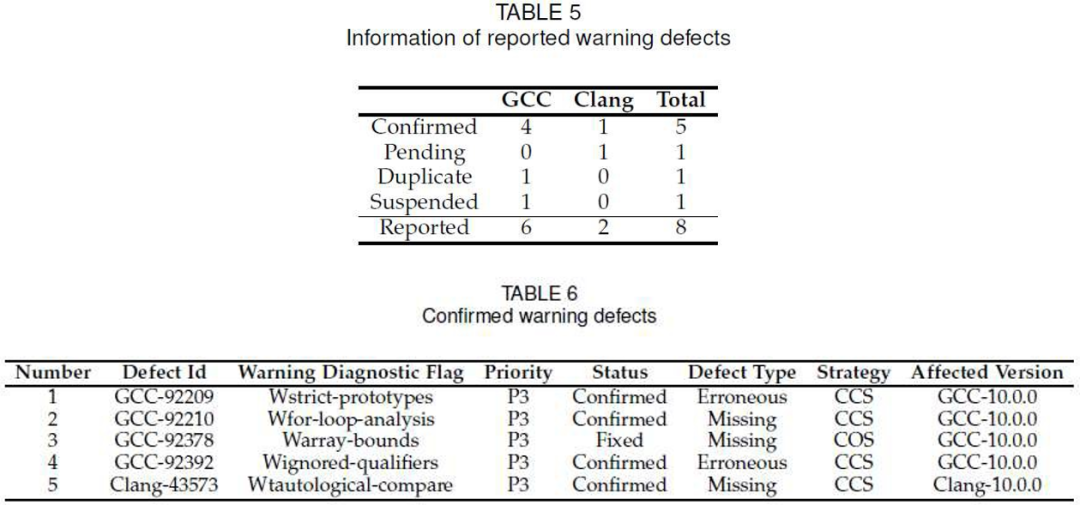
## RQ3: DIPROM 能否在最新版本的编译器上检测到警告缺陷/p>
我们将 DIPROM 应用到最新版本的 GCC 和 Clang 来检测警告缺陷,DIPROM 检测出 8 个新版本编译器的警告缺陷,其中 5 个已被开发者确认。
# 编译器优化故障分析 #
接下来,我简单介绍一下我们团队有关编译器优化故障的分析工作。
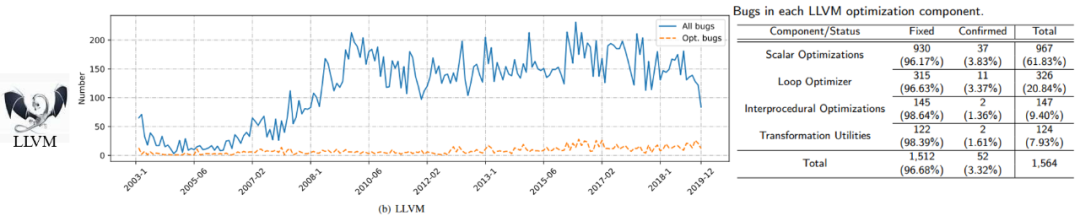
我们想了解编译器优化有关的故障分布是什么样,因此我们针对故障仓库做了一个分析 [10],这篇分析报告发表在 JSS 上。我们发现:
-
GCC 的故障分布 “相对稳定”,实际上有 65% 左右的故障是与其中一个特定的组件 tree-optimization 有关。

-
LLVM 的故障分布 “呈上升趋势”,60% 以上的故障是在做标量优化(Scalar Optimization)的组件里。
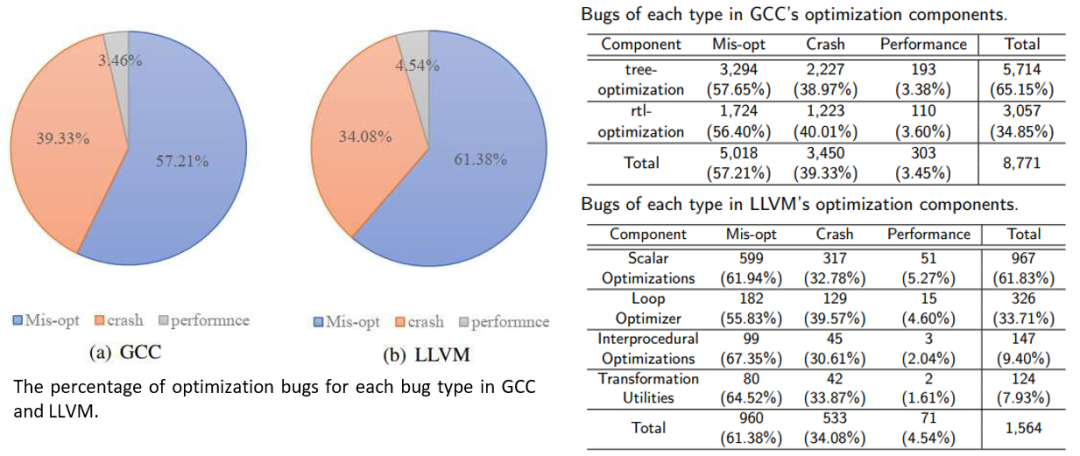
另外,不同编译器里出现故障的概率分布也是不一样的。主要的故障类型有下面三种:
-
其中 Mis-optimization 类型的优化故障在 GCC 和 LLVM 占比最大,分别达到了 57.21% 和 61.38%。Mis-optimization 就是指程序优化后,执行的结果变了。这类问题是比较严重的,在航天领域曾经出现过一些因 Mis-opt 而导致的事故,因此我国航天领域对这类故障十分重视。
-
第二类主要的故障(占 35%~40% 左右)是 Crash,就是指编译器崩掉了。这个也是比较严重的问题,对于编译器开发者来讲,虽然伤害不大,但是侮辱性很强 ??
-
还有一些 Performance 类的故障,即编译器可能在遇到某些特定程序的时候,执行时间特别长,内存瞬间增加很快,这些情况属于 Performance 类型的故障。
# 编译器优化序列故障检测 – CTOS #
接下来,介绍一下编译器优化序列检测相关的工作。
如前面所讲,大家在使用 LLVM 或者 GCC 时,优化序列的选择会影响到最后的编译效果,甚至优化选项的次序不一样,对编译后程序的执行速度,规模等都会有影响。编译器优化序列次序的问题业界已经有很多研究工作,这类问题有个单独的名字即 phase ordering( 小编:推荐大家阅读江贺老师团队于 2019 年发表的《编译优化序列选择研究进展》 [11] 论文 )。有一些研究者发现,编译器会在给定某些特定程序和特定优化序列时崩溃,但这种情况下如何找到故障当时还没有太多研究工作。因此,我们团队针对这种情况做了专门的研究。
大家可以看下面的例子,当我们使用特定优化序列时,会触发一个断言的编译器故障。
LLVM Bug 41294: https://bugs.llvm.org/show_bug.cgid=41294

那么要解决这个问题,我们实际上面临着两个挑战:
-
代表性优化序列获取:GCC 有 150+ 个优化选项,LLVM 有 200+ 个优化选项,优化选项的组合具有多样性,会存在空间爆炸的问题
-
代表性测试程序选择:测试程序的数量几乎是无限的,我们也需要保证有效测试程序的多样性

编译器优化序列故障的两个挑战
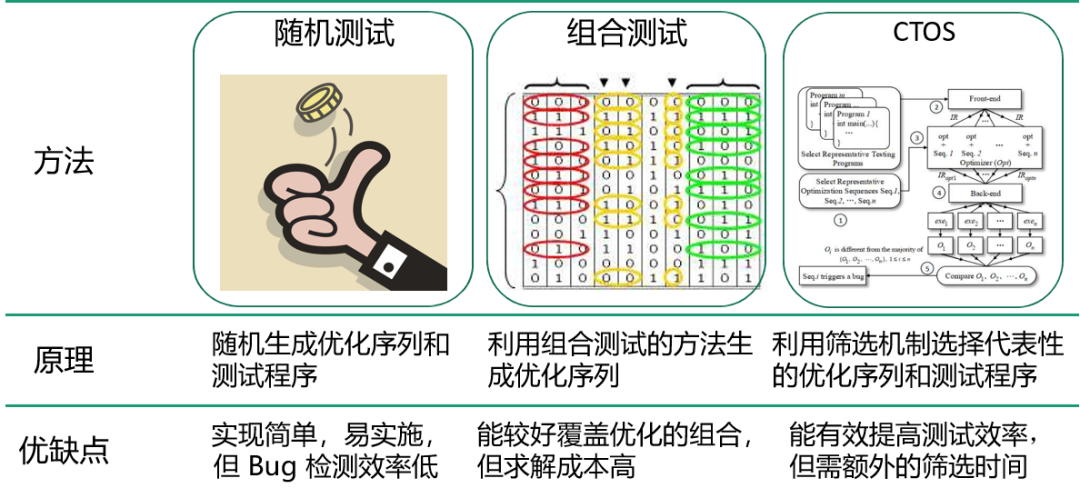
针对这个场景,我们可以有下面几种方式来测试:
-
随机测试 即随机产生优化序列和测试程序
-
组合测试 即优化选项做成可配置的,配合测试用例进行测试
-
CTOS [12] 我们团队单独实现了一个方法,即 CTOS,对优化序列和程序都进行筛选,从而提高测试效率
编译器优化序列故障的三种方法
# CTOS 框架介绍
CTOS [12],即 Compiler Testing for Optimization Sequences of LLVM。这个框架的目的主要有两点,一是我们希望比较快地产生尽可能多的测试程序和组合序列,另外我们还希望可以保证程序和组合的多样性,即测试程序之间差别越大越好,序列之间差别越大越好。CTOS 整体的框架如下:
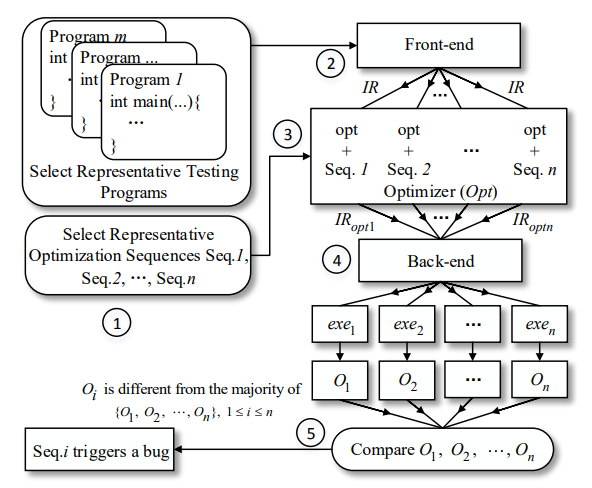
CTOS 框架
CTOS 由以下五个步骤组成:
-
选择代表性优化序列和测试程序
-
获取给定测试程序未优化的中间代码(IR)
-
利用优化序列优化中间代码,生成可执行程序
-
执行程序,对比各程序的输出结果
-
根据结果差异性,判定优化序列是否触发编译器故障
CTOS 的关键思路是,对测试程序和优化序列进行向量化表示,从而有效地度量测试程序或优化序列之间的差异,进而选择出代表性的测试程序和优化序列。
## 优化序列的向量化
CTOS 使用了文本处理的 Doc2Vec [13] 的思路,将优化和单词做映射,从而完成优化序列的向量化。

将优化序列视为自然语言,利用高效的自然语言表示方法对优化序列进行表示
## 测试程序的向量化
对测试程序的处理也是类似,通过向量化的方法来度量其差异性。但与优化序列的向量化不同的是,CTOS 将程序视为函数在特定调用关系下的一个整体,即:

因此,在 CTOS 中,我们把测试程序的向量表示分为两部分,即 一个函数的表示和 整个程序的表示。
阶段 1:获取各函数的向量表示。根据给定测试程序的 LLVM IR,获取其相应的向量表示:
-
生成 区域图(region graph,一种特殊的控制流图,其使得每个基本块有且仅属于一个区域)

-
获得区域图中每条边的向量表示
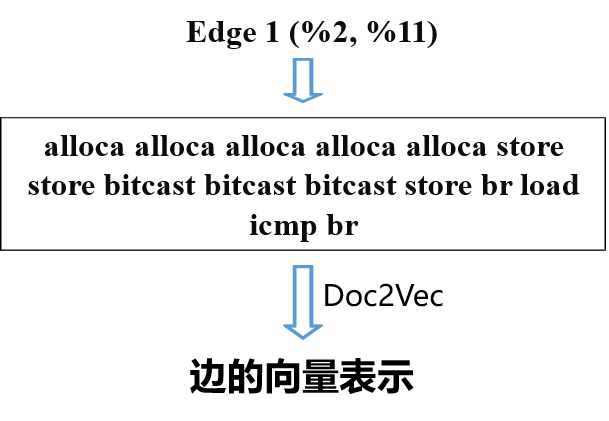
-
基于 深度区域优先(deep region-first) 的策略聚合每条边的向量表示。深度区域优先策略可归纳为两个约束:
-
约束 1: 对于给定节点,若其入边向量可被传递到出边,则其所有入边应该已被处理过。
-
约束 2: 对于两个属于不同区域的节点,选择区域较深的节点作为候选节点。
-
阶段 2:对整个程序进行向量表示根据函数间的调用关系,聚合程序中各函数的向量表示。 基本思想是将函数的向量表示,从被调用函数传递到调用函数,从而形成整个程序的向量表示:
-
删除调用图中的递归调用
-
自底向上,逐步将被调用函数的向量表示聚合到调用函数
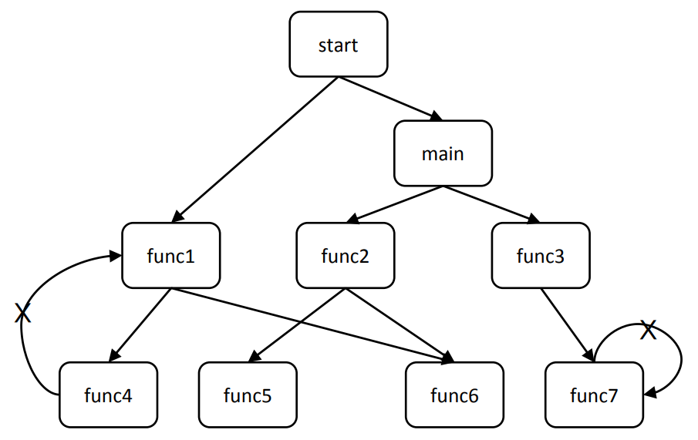
调用关系图示例
## 选择策略
在完成优化序列和测试程序的向量化后,CTOS 提出一个选择策略,以帮助我们选择更具代表性和多样性的优化序列和测试程序。算法的基本思想是 使用一种基于中心的策略,逐步选择优化序列或测试程序,使得被选优化序列或测试程序之间的距离之和最大化。
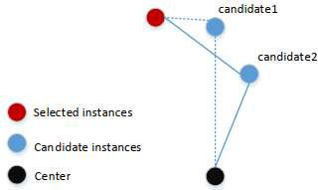
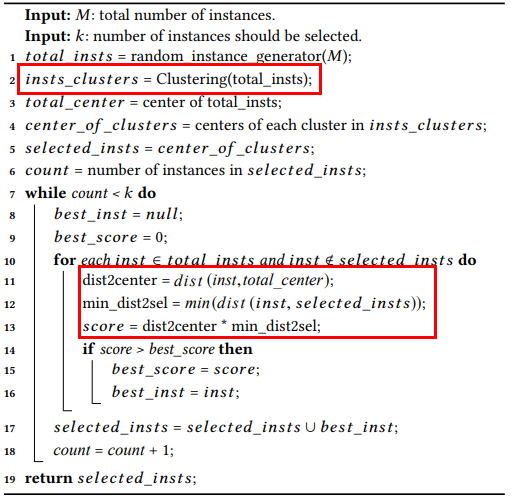
Selection of representative instances
# 实验评估
我们从以下两个方面来评价 CTOS 的有效性。
## RQ1:本文所提出的选择策略是否有助于检测优化序列故障/p>
因为之前没有人专门研究过优化序列导致的编译器故障检测,所以对比实验中主要探讨了 CTOS 的各种变种的故障检测效果。在经过 14 组对比试验后,结果表明,CTOS 的故障检测能力明显优于其他方法,平均能比其他方法提升 24.76% ~ 50.57%,CTOS 所提出的选择策略有助于提升测试效率。
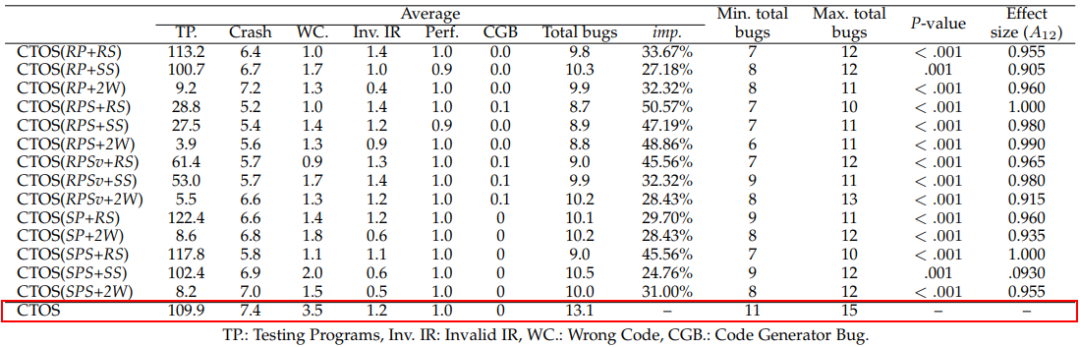
Results of CTOS and its 14 variants.
## RQ2:在实践中,CTOS 的故障发现能力如何/p>
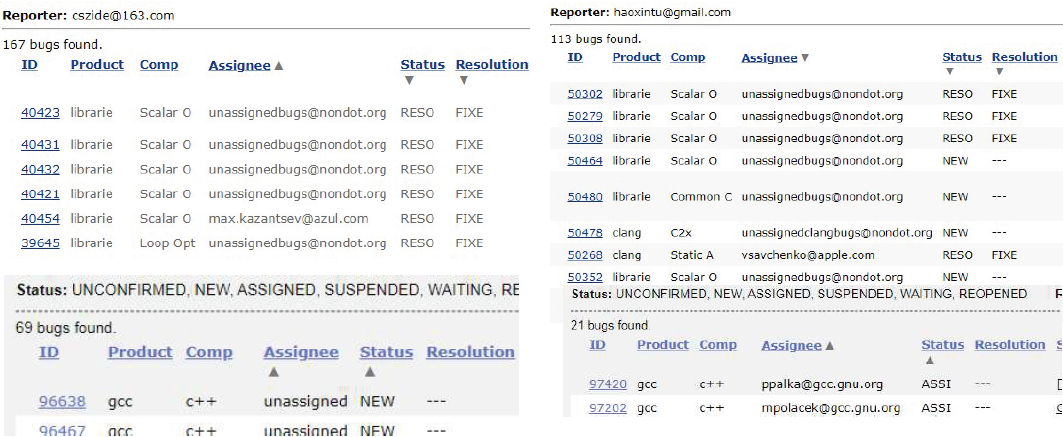
此外,我们还关心 CTOS 的实际故障检测能力。我们在 2019 年针对当时最新版本的 LLVM 进行了测试,测试时间超过七个月,发现了 5 类 104 个有效的故障,其中导致编译器崩溃的编译器故障有 57 个,还有一些生成无效 IR 的故障。这些故障在当时有 21 个已被确认或修复:
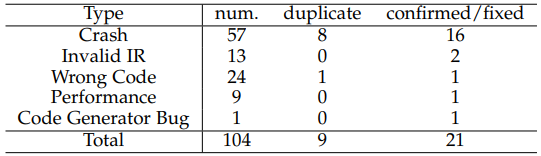
Reported bugs.
此外,在检测出的这 104 个有效故障中,涉及了 47 个单独的优化,其中 15 个与循环优化有关(下表中粗体字)。这个结果表明,LLVM 循环优化的设计可能存在一些缺陷,应该由开发者进一步加强。

Buggy optimizations for reported bugs.
# 编译器优化序列故障定位 – LocSeq #
在做了前面有关优化序列故障检测的工作后,下一步我们要考虑的是,如何对检测到的故障进行准确定位,找出编译器出现故障的具体位置。编译器的故障定位十分困难,给定一个能够触发编译器故障的测试程序,其编译过程通常会涉及数百个编译器文件。因此,编译器开发者要进行定位的话,我们希望可以尽可能地推荐到准确的代码文件,甚至推荐到准确的函数级别。
当前大家用的比较多的故障定位方法还是 基于程序频谱的故障定位(program spectrum-based fault localization),即给定能够触发编译器故障的测试用例,看编译器执行的路径是什么,结合一些能够正常执行的测试用例,查看编译器执行路径与之前的差异。通过一些相似性公式,从而计算路径上每条边故障的可能性并排序。
程序频谱 Program Spectrum [14],或者叫代码覆盖率 Code Coverage,可以定义为测试执行过程中覆盖的程序实体的集合。
-
如何获取差异化的编译器执行信息/strong> 编译器故障定位可视为利用编译器执行信息进行比对,排除无关文件的过程。所以获取差异化的编译器执行信息是定位编译器故障的关键。
-
如何对获取的差异信息进行对比,确定故障位置/strong> 经典的软件故障定位方法,如 Ochiai [15] 公式。
业界针对编译器故障定位已有一些技术方法,如下图中 Diwi [16] 和 RecB [17] 是陈俊洁老师的工作,其方式是给定一个固定的编译器优化序列,针对测试程序进行变换,比如做局部变异,来生成可编译成功的编译程序。既获得了编译器的不同执行路径,同时保证大部分路径是高度重合的,从而使用一些公式来计算触发故障的路径和可正常执行的路径的差异,来定位故障。但这类方法生成变异程序消耗的时间过长,难以高效定位。
因此,为了高效、准确地定位编译器优化序列故障,我们团队做了以下工作LocSeq [18]。

编译器优化序列故障定位:Diwi [16], RecBi [17], LocSeq [18]
# LocSeq 介绍
LocSeq [18] (Automated Localization for Compiler Optimization Sequence Bug of LLVM) 的动机是,将编译器优化序列故障定位问题,转化为无故障优化序列的构造问题,使故障优化序列与无故障优化序列之间的 编译器执行轨迹尽可能相似,从而排除故障无关的文件,定位故障的位置。LocSeq 框架如下:

LocSeq 框架
## LocSeq 核心思路:CGA 算法
为了搜索到不触发编译器故障的所有优化序列,LocSeq 采用了 CGA(约束遗传算法,Constrained Genetic Algorithm)。CGA 算法的步骤如下:

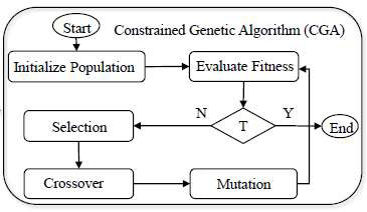
CGA 的执行流程
目标 构造一组无故障优化序列,并使故障优化序列与无故障优化序列之间的编译器执行轨迹尽可能相似。
解的表示 CGA 中每个个体(即每条优化序列)被表示为一个列表,该列表包含可触发故障的优化序列中的所有优化,以及候选列表中的某些优化。
适应度评价 即衡量无故障优化序列与故障优化序列下编译器执行轨迹的相似度。假设 为某个无故障优化序列, 为故障优化序列, 和 为 , 作用下编译器的执行的代码语句,LocSeq 采用 杰卡德相似性系数 作为衡量 , 间相似度的方法,具体定义如下,其中 越大且 不会触发编译器故障,则优化序列 的适应度越好。在对每个无故障优化序列进行适应度计算后,按降序排序。
交叉 即对两条无故障优化序列以一定概率进行拆分与重新拼接,以构成新的优化序列。LocSeq 采用了 单点交叉(One-point Crossover)的方式获取新的优化序列,拼接后的优化序列仍然需要保证可覆盖故障序列中的所有优化。

单点交叉拼接优化序列
变异 在经过 交叉 后,LocSeq 会将优化序列进行变异。即对每个优化以一定的概率进行 删除、替换、移位、插入 四种变异操作。当然,变异后的优化序列仍然需要保证可覆盖故障序列中的所有优化。
故障定位 根据故障优化序列,和无故障优化序列集合,计算故障发生时,编译器所执行的各条代码语句的可疑度,然后将文件中所有被执行代码语句的平均可疑度作为该文件的可以读。依据文件可疑度进行降序排序,文件可疑度越大,则表明该文件越有可能包含故障。
-
代码语句可疑度 采用 Ochiai 公式 计算:
其中,, 分别表示执行和未执行语句 s 的 故障优化序列数, 表示执行语句 s 的 无故障优化序列数。在 LocSeq 中,我们仅考虑一个故障优化序列,且只考虑故障发生时被执行到的代码语句,所以上述公式可简化为:
-
文件可疑度 为该文件中所有被执行语句可疑度的 均值:
经过一系列对优化序列的变换,我们最终会获得一个排序后的文件列表,以帮助编译器开发者提高故障定位效率。
# 实验评估
## RQ1:与经典方法相比,LocSeq 定位优化序列故障的效率怎么样/p>
最终我们关心的是 LocSeq 的定位效果到底怎么样。我们将 LocSeq 与 DiWi、RecBi 进行了对比。实验结果表明,LocSeq 的优化序列故障定位能力明显优于 DiWi 和 RecBi,Top-5 的性能提升分别为 77.27% 和 56%。

LocSeq [18] 的框架
## RQ2:CGA 是否有利于提升 LocSeq 的效率/p>
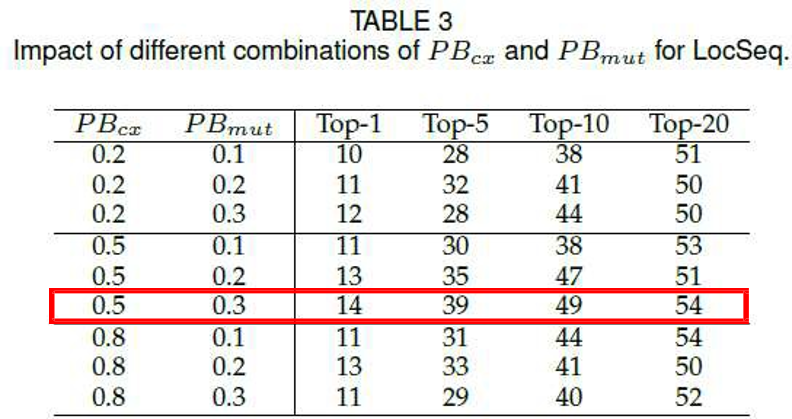
进一步地,我们探讨了 CGA 以及约束对 LocSeq 效率的影响,对比发现,使用 CGA 的 LocSeq 定位故障的性能明显优于其他方法。此外,我们还测试了 CGA 的交叉概率 和 变异概率 对 LocSeq 效率的影响。实验结果表明,LocSeq 的性能对 CGA 的交叉、变异概率并不十分敏感。但交叉、变异概率分别为 0.5 和 0.3 时实验结果相对更好。
# 谛听
我们后面会将前面讲到的这些工作做成一个工具 —— 谛听。到目前为止,谛听已为 GCC 和 LLVM 提交了近 400 个 Bug Reports,其中有 180+ 个已经被编译器团队确认或者修复。
以上,谢谢大家。
往期 SIG-编程语言测试 文章回顾
参 考
[1]
Fu, H., Liao, J., Yang, J. et al. The Sunway TaihuLight supercomputer: system and applications. Sci. China Inf. Sci. 59, 072001 (2016). https://doi.org/10.1007/s11432-016-5588-7
[2]
寒武纪 Compilers 介绍 —— 寒武纪 CNToolkit 文档 https://www.cambricon.com/docs/cntoolkit/chapter_components/index.html#compilers
[3]
OpenArkCompiler 方舟编译器开源代码官方主仓库 https://gitee.com/openarkcompiler/OpenArkCompiler
[4]
CompCert – The CompCert C Compiler https://compcert.org/
[5]
Test Oracle – Wikipedia https://en.wikipedia.org/wiki/Test_oracle
[6]
Vu Le, Mehrdad Afshari, and Zhendong Su. 2014. Compiler validation via equivalence modulo inputs. In Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI ’14). Association for Computing Machinery, New York, NY, USA, 216–226. DOI: https://doi.org/10.1145/2594291.2594334
[7]
Chengnian Sun, Vu Le, and Zhendong Su. 2016. Finding and analyzing compiler warning defects. In Proceedings of the 38th International Conference on Software Engineering (ICSE ’16). Association for Computing Machinery, New York, NY, USA, 203–213. DOI: https://doi.org/10.1145/2884781.2884879.
[8]
J. Chen, G. Wang, D. Hao, Y. Xiong, H. Zhang and L. Zhang, “History-Guided Configuration Diversification for Compiler Test-Program Generation,” 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2019, pp. 305-316. DOI: https://ieeexplore.ieee.org/document/8952321.
[9]
Y. Tang, H. Jiang, Z. Zhou, X. Li, Z. Ren and W. Kong, “Detecting Compiler Warning Defects Via Diversity-Guided Program Mutation,” in IEEE Transactions on Software Engineering, doi: 10.1109/TSE.2021.3119186.
[10]
Zhide Zhou, Zhilei Ren, Guojun Gao, He Jiang, An empirical study of optimization bugs in GCC and LLVM, Journal of Systems and Software,
Volume 174, 2021, 110884, ISSN 0164-1212. DOI: https://doi.org/10.1016/j.jss.2020.110884.
[11]
编译优化序列选择研究进展. 高国军, 任志磊, 张静宣, 李晓晨, 江贺. 中国科学: 信息科学, 2019,(10):1267-1282. http://scis.scichina.com/cn/2019/N112019-00050.pdf
[12]
H. Jiang, Z. Zhou, Z. Ren, J. Zhang and X. Li, “CTOS: Compiler Testing for Optimization Sequences of LLVM,” in IEEE Transactions on Software Engineering, doi: 10.1109/TSE.2021.3058671. DOI: https://ieeexplore.ieee.org/abstract/document/9353261
[13]
Quoc V. Le and Tomas Mikolov. Distributed representations of sentences and documents, 2014. DOI: https://arxiv.org/abs/1405.4053
[14]
Souza, Higor & Chaim, Marcos & Kon, Fabio. (2016). Spectrum-based Software Fault Localization: A Survey of Techniques, Advances, and Challenges. https://arxiv.org/pdf/1607.04347.pdf
[15]
R. Abreu, P. Zoeteweij and A. J. c. Van Gemund, “An Evaluation of Similarity Coefficients for Software Fault Localization,” 2006 12th Pacific Rim International Symposium on Dependable Computing (PRDC’06), 2006, pp. 39-46. DOI: https://doi.org/10.1109/PRDC.2006.18
[16]
Junjie Chen, Jiaqi Han, Peiyi Sun, Lingming Zhang, Dan Hao, and Lu Zhang. 2019. Compiler bug isolation via effective witness test program generation. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2019). Association for Computing Machinery, New York, NY, USA, 223–234. DOI: https://doi.org/10.1145/3338906.3338957
[17]
Junjie Chen, Haoyang Ma, and Lingming Zhang. 2020. Enhanced compiler bug isolation via memoized search. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering (ASE ’20). Association for Computing Machinery, New York, NY, USA, 78–89. DOI:https://doi.org/10.1145/3324884.3416570
[18]
Zhide Zhou, He Jiang*, Zhilei Ren, et al. LocSeq: Automated Localization for Compiler Optimization Sequence Bug of LLVM. IEEE Trans. on Reliability. (Under review).
END
来源:li49665
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!