一、分组查询
1.1 概念
在使用聚合函数对数据进行查询时,无论通过where条件筛选后的数据有多少条,仅返回聚合后的单一结果,如果想对多条数据进行分别的聚合查询,就需要使用分组group by。这样,在查询数据后就会根据不同的分组,进行数据的聚合操作返回对应数据
1.2 group by语法
查询不同住址的平均年龄
group by 子句规则
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数) 。如果在SELECT中使用表达式,则必须在 GROUP BY 子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后 (如果有 WHERE 子句的话 ),ORDER BY子句之前。
1.3 having 语法
查询分组后对分组使用的聚合函数进一步进行数据过滤
HAVING 非常类似于 WHERE。事实上,目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,而HAVING过滤分组。
语法
查询平均年龄小于等于20的地址
HAVING和WHERE的差别
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
但是 where 和 having 可以同时使用
示例:年龄大于25岁的雇员进行分组,每个性别 多于 2人的数据
二、排序
2.1 概念
检索出的数据并不是以纯粹的随机顺序显示的。如果不排序,数据一般将以它在底层表中出现的顺序显示。这可以是数据最初添加到表中的顺序。但是,如果数据后来进行过更新或删除,则此顺序将会受到MySQL重用回收存储空间的影响。如果不明确规定排序顺序,则不应该假定检索出的数据的顺序有意义。
为了明确地排序用SELECT语句检索出的数据,可使用ORDER BY子句。ORDER BY子句取一个或多个列的名字,据此对输出进行排序。
2.2 order by语法
Order by 子句的位置
- 在给出ORDER BY子句时,应该保证它位于FROM子句之后
- 如果使用 LIMIT,它必须位于ORDER BY之后。使用子句的次序不对将产生错误消息。
Order By 执行顺序
- 执行 from
- 执行 where
- 执行 select
- 执行 order by
在对单个字段进行排序时,可能出现数据相同的情况(各科考试成绩),那么我们就可以通过对多个字段进行分别排序的方式进行排序。
按照各科成绩语文成绩从小到大 数学成绩从大到小 英语成绩从大道行排序
按照年龄升序排序,年龄相同按学号降序排序
分组与排序的区别
虽然GROUP BY和ORDER BY经常完成相同的工作,但它们是非常不同的。见下表
| ORDER BY | GROUP BY |
|---|---|
| 排序产生的输出 | 分组行。但输出可能不是分组的顺序 |
| 任意列都可以使用(甚至非选择的列也可以使用) | 只可能使用选择列或表达式列,而且必须使用每个选择 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
三、子查询
3.1 概念
当本次查询的条件或数据依赖于另一次查询的结果时,就需要使用子查询
子查询的本质是书写多条sql语句同时执行(在一次查询中书写多个select语句)
3.2 作为条件语句进行数据筛选
可以使用其他查询返回的一条或多条数据作为条件的结果
查询与jack住在同一个地址的其他学生信息
3.3 作为临时表数据提供
临时表概念
实际上数据库存储数据的形式,根据引擎而定,但是这些数据我们是不能直接查看的,通过sql语句管理软件会根据语句返回对应的临时表的形式进行查看
四、多表连接查询
4.1 概念
在查询时,在满足数据库设计三范式的前提下,数据会存储在不同的表中,各个表通过字段产生关联,如果想在一次查询中将两个或多个表的信息一同显示,这个时候就需要使用连接查询,将多个表的数据连接在一起使用,进行结果的显示
4.2 内连接
将多个表中的数据根据连接条件连接为新的表,在新的表上继续进行查询操作
查询所有学生姓名以及班级
4.3 全连接
在使用连接时必须on 书写连接条件否则会将所有数据的笛卡尔积返回,但是有时我们还需要这样的数据,不使用连接的语法 ,而是使用where进行条件筛选
查询与jack住在同一地方的学生信息
4.4 外连接
在进行连接查询时,内连接只会返回满足连接条件的数据,如果连接的两表中,没有与其对应满足条件的数据,那么这条数据将不会显示,外连接就是用于解决这一问题的,使用外连接即使没有对应满足条件的数据,也会将当前数据显示
左外连接
以左表为准,即使右表中没有与之对应的数据,那么也会显示左表的全部数据,对应右表使用null填充
右外连接
以右表为准,即使左表中没有与之对应的数据,那么也会显示右表的全部数据,对应左表使用null填充
五、组合查询
与连接查询不同是,连接查询将量表数据左右连接通过连接条件进行拼接,组合查询是将多条拥有相同类型列相同列数的多条sql语句上下拼接
UNION规则
- UNION 必须由两条或两条以上的 SELECT 语句组成,语句之间用关键字 UNION 分隔(因此,如果组合4条SELECT 语句,将要使用3个 UNION 关键字) 。
- UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)
如果遵守了这些基本规则或限制,则可以将并用于任何数据检索任务
UNION ALL包含或取消重复的行
使用UNION ALL,MySQL不取消重复的行。因此这里的例子返回9行,其中有一行出现两次
- UNION几乎总是完成与多个WHERE条件相同的工作
- UNION ALL为UNION的一种形式,它完成WHERE子句完成不了的工作
- 如果确实需要每个条件的匹配行全部出现(包括重复行),则必须使用UNION ALL而不是 WHERE
六、视图
视图与每次sql语句查询的结果虚拟表类似,只不过与普通的虚拟表不同,视图可以通过创建的形式保存虚拟表,并使用视图把其当做一张已存在的表进行使用(视图表包含的是已存在表的动态数据,所以对存在表数据操作,视图的数据也会修改)
通常的做法是将经常使用的多表的关联创建视图进行使用
视图的规则和限制
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字) 。
- 对于可以创建的视图数目没有限制。
- 为了创建视图,必须具有足够的访问权限。这些限制通常由数据库管理人员授予。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造一个视图。
- ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也含有ORDER BY,那么该视图中的ORDER BY将被覆盖。
- 视图不能索引,也不能有关联的触发器或默认值。
- 视图可以和表一起使用。例如,编写一条联结表和视图的SELECT语句。
七、SQL执行顺序
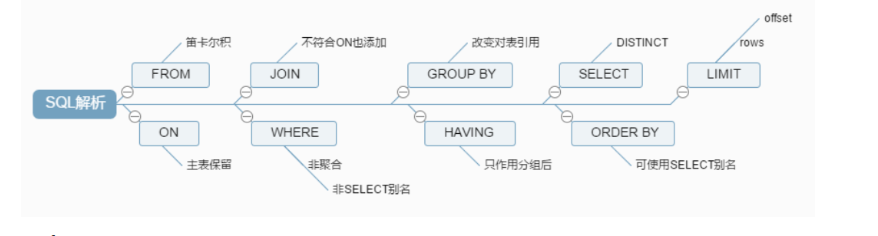

- from :数据源,查询数据来源
- join :连接数据源,当一个表数据不能满足需求进行连接
- on :连接条件 在连接数据源时过滤不必要的数据
- where :条件筛选,进一步对数据进行筛选
- group by(开始使用select中的别名,后面的语句中都可以使用)
- avg,sum… (聚合函数)
- having :对分组的数据进一步进行筛选
- select :选择结果集中最终展示的列
- distinct :对相同数据去重
- order by:对指定列进行排序
- limit :截取指定长度数据
八、SQL优化
硬件优化
使用更好的设备,从服务器,存储,内存,运存,网络多方面更新硬件
软件优化
主要是服务器管理软件以及数据库管理软件进行优化
数据库管理软件一般通过修改配置文件
- thread_concurrency:# 并发线程数量个数
- sort_buffer_size:# 排序缓存
- read_buffer_size:# 顺序读取缓存
- read_rnd_buffer_size:# 随机读取缓存
- key_buffer_size:# 索引缓存
- thread_cache_size:# (1G—>8, 2G—>16, 3G—>32, >3G—>64)
sql优化
数据库结构优化
创建数据库时使用数据库三范式进行表结构的创建
创建表时对于表的字段类型进行优化
在字段类型设置时不要使用null 可能使索引失效
sql语句优化
添加索引
在查询时减少不必要字段的查询(*)
减少null 与not null 的使用 因为会导致索引失效
减少in 与not in 的使用 因为会导致索引失效
减少like 的使用 因为可能会导致索引失效
减少or 的使用 因为可能会导致索引失效
尽量使用连接查询替代子查询
在进行连接查询时,尽量将条件书写在on中(数据的连接可以理解为数据的准备阶段,在准备阶段直接将数据进行过滤,减少where条件的书写)
减少在where字句中条件的书写
减少排序ordery的使用
在进行查询添加等操作时,书写的数据类型最好与字段的类型相匹配
https://bbs.csdn.net/topics/397417232ist=1149931
文章知识点与官方知识档案匹配,可进一步学习相关知识MySQL入门技能树数据库组成表31861 人正在系统学习中
来源:狮子弓少
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!