恒生电子:
**
···如果性能测出来,数据库查询慢,怎么给开发建议:
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。一个表的索引不能过多,过多不利于删除,插入等操作。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=205.in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like ‘%abc%’
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=‘abc’–name以abc开头的id
应改为:
select id from t where name like ‘abc%’
9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,
否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
11.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)
12.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引, 如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率, 因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。 这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间, 其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
18.避免频繁创建和删除临时表,以减少系统表资源的消耗。
···数据库主键与唯一索引的区别
区别:
- 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
- 唯一性索引列允许空值,而主键列不允许为空值。
- 主键列在创建时,已经默认为空值 + 唯一索引了。
- 主键可以被其他表引用为外键,而唯一索引不能。
- 一个表最多只能创建一个主键,但可以创建多个唯一索引。
- 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
- 在 RBO 模式下,主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。
···需求评审,怎样真正站在用户角度
···Linux指令
···接口用例,比如有10个参数,反向用例你手写太麻烦,怎么设计br> ···python学到什么程度
···微信群发红包的金额数,设计用例
大华
UI自动化,除了Xpath,还有别的方法定位吗/strong>
1、id属性
2、name属性
3、class属性
4、标签名
5 6 、链接元素 link_text #完全匹配 #模糊匹配
7 8、 xpath =ZZ 易懂 css = 难懂
active mq,除了队列,还有什么概念/strong>
mq
Chmod777是怎么理解

RF框架基本语法。如果一条用例里面要跳过某条语句是什么
Run Keyword And Return Status,
Run Keyword And Ignore Error
Run Keyword And Continue on Failure
详见 RF框架基础知识
常见问题
新华三
!!入职要提供工资流水,工资要如实说。
问的涉及技术的基本是网络技术相关知识:路由协议,路由器的作用,7层网络模型等。网络技术要复习好
路由协议
【面试杂知识】
1.网络
二层交换机、三层交换机和路由器的原理及区别
网桥也叫桥接器,是连接两个局域网的一种存储/转发设备,它能将一个大的LAN分割为多个网段,或将两个以上的LAN互联为一个逻辑LAN,使LAN上的所有用户都可访问服务器。
网桥和交换机的区别
局域网交换机的基本功能与网桥一样,具有帧转发、帧过滤和生成树算法功能。但是,交换机与网桥相比还是存在以下不同:
1、交换机工作时,实际上允许许多组端口间的通道同时工作。所以,交换机的功能体现出不仅仅是一个网桥的功能,而是多个网桥功能的集合。即网桥一般分有两个端口,而交换机具有高密度的端口。
2、分段能力的区别
由于交换机能够支持多个端口,因此可以把网络系统划分成为更多的物理网段,这样使得整个网络系统具有更高的带宽。而网桥仅仅支持两个端口,所以,网桥划分的物理网段是相当有限的。
3、传输速率的区别
交换机与网桥数据信息的传输速率相比,交换机要快于网桥。
4、数据帧转发方式的区别
网桥在发送数据帧前,通常要接收到完整的数据帧并执行帧检测序列FCS后,才开始转发该数据帧。交换机具有存储转发和直接转发两种帧转发方式。直接转发方式在发送数据以前,不需要在接收完整个数据帧和经过32bit循环冗余校验码CRC的计算检查后的等待时间。
计算IP
IP协议
三次握手
简单来说,就是
建立连接时,客户端发送SYN包(SYN=i)到服务器,并进入到SYN-SEND状态,等待服务器确认
服务器收到SYN包,必须确认客户的SYN(ack=i+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器进入SYN-RECV状态
客户端收到服务器的SYN+ACK包,向服务器发送确认报ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手
有人可能会问,为什么连接的时候是三次握手,而断开连接的时候需要四次挥手br> 这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接时,当收到对方的FIN 报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,再 发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。
A发送一个FIN,用来关闭A到B的数据传送,A进入FIN_WAIT_1状态。
B收到FIN后,发送一个ACK给A,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),B进入CLOSE_WAIT状态。
B发送一个FIN,用来关闭B到A的数据传送,B进入LAST_ACK状态。
A收到FIN后,A进入TIME_WAIT状态,接着发送一个ACK给B,确认序号为收到序号+1,B进入CLOSED状态,完成四次挥手。
字节
一个字节=8位(bit)
1个字节是8位,二进制8位:xxxxxxxx 范围从
00000000-11111111,表示0到255。
一位16进制数(用二进制表示是xxxx)最多只表示到15(即对应16进制的F),要表示到255,就还需要第二位。
所以1个字节=2个16进制字符,一个16进制位=0.5个字节
MAC地址则是48位的(6个字节),通常表示为12个16进制数,每2个16进制数之间用冒号隔开,如08:00:20:0A:8C:6D就是一个MAC地址。
IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节)。

链接:https://www.zhihu.com/question/25532384/answer/411179772
死锁
内存:
栈 1.存放局部变量 2.不可以被多个线程共享 3.空间连续,速度快
堆 1.存放对象 2.可以被多个线程共享 3.空间不连续,速度慢,但是灵活
方法区 1.存放类的信息:代码、静态变量、字符串常量等等 2.可以被多个线程共享 3.空间不连续,速度慢,但是灵活
总的来说:我们先来记住两条黄金法则:
1.引用类型总是被分配到“堆”上。不论是成员变量还是局部
2.基础类型总是分配到它声明的地方:成员变量在堆内存里,局部变量在栈内存里。
Hash表
即散列表,其最突出的优点是查找和插入删除具有常数时间的复杂度
其实现原理是:把Key通过一个固定的算法函数即所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,几乎可以看成是常数时间;而代价仅仅是消耗比较多的内存。然而在当前可利用内存越来越多的情况下,用空间换时间的做法是值得的。另外,编码比较容易也是它的特点之一。哈希表又叫做散列表,分为“开散列” 和“闭散列”。
我们使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数,也叫做散列函数),使得每个元素的关键字都与一个函数值(即数组下标)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照关键字为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方。
但是,不能够保证每个元素的关键字与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。后面我们将看到一种解决“冲突”的简便做法。 总的来说,“直接定址”与“解决冲突”是哈希表的两大特点。
3.测试
软件测试笔试面试题目完全汇总
一个合格的优秀的测试工程师,应该是能做到如下几点:
懂业务。能扎实的保证业务质量。不排斥用脑力和体力去保证质量。
懂技术。能够做深入的自动化或者分析工作。能够利用工具和技术解决问题。
懂架构。能够跟研发和产品进行正常的交流,保证产品需求和实现都没问题。能带团队走上更好的发展。
切莫在不该有的年龄追求权利
这会断送你的整个前程. 在一些面试场合, 如果面试官问你愿不愿意做管理, 如果你回答是, 那么面试基本就挂了.
一定要确认面试你的人是不是真的希望你走管理路线. 大多只是测试你是不是真的是个实干家.
过早参与管理工作也会导致个人技能发展的不健全. 这会为以后带来隐患.
测试报告章节
1.引言
编写目的
项目背景
系统简介
术语和缩写词
2.测试概要
包括测试的一些声明、测试范围、测试目的等等,主要是测试情况简介
测试环境与配置
测试方法(和工具)
3.测试结果及缺陷分析
测试执行情况与记录
测试组织
测试时间
需求覆盖分析
缺陷的统计与分析
DI:10,3,1
残留缺陷与未解决问题
4.测试结论与建议
4.1 测试结论
1. 测试执行是否充分(可以增加对安全性、可靠性、可维护性和功能性描述)
2. 对测试风险的控制措施和成效
3. 测试目标是否完成
4. 测试是否通过
5. 是否可以进入下一阶段项目目标
4.2 建议
1.对系统存在问题的说明,描述测试所揭露的软件缺陷和不足,以及可能给软件实施和运行带来的影响
2.可能存在的潜在缺陷和后续工作
3.对缺陷修改和产品设计的建议
4.对过程改进方面的建议
测试计划章节
测试计划章节
质量准入
需求完成率:(完成需求数/总需求数,b1≥95%、b2≥100%)
? 第一轮关键需求完成率100% 完成需求明细表(需求跟踪矩阵填写需求实现情况)
缺陷修复率:中高级缺陷清零(未清0的高中缺陷给出影响分析),所有缺陷修复率95%,其中自测(评审、代码审核、单元测试)类缺陷100%关闭 缺陷修复率
自测记录:各组件集成自测结果、合规性验证结果(含驱动)、安全扫描报告 ET自测用例冒烟功能100%通过、合规性测试结果地址、安全扫描报告无高级别缺陷
更新说明:需求/设计变更情况 更新说明
测试建议:各组件从开发角度建议测试人员重点关注及测试的功能模块 测试建议
版本测试准出
整个版本用例(包含功能、性能)执行覆盖率≥99%
整包版本冒烟用例通过率100%
已修复缺陷处理率100%
不存在高风险遗留缺陷
更具体的分析如风险
具体
风险
设计方面:
风险:(1)没有详细设计说明书;
解决方案:测试人员要在开发阶段对相关设计及需求文档进行分析,对大体模块功能进行分类,分析业务逻辑,在不清楚的地方及时与开发人员沟通。
风险:(2)没有统一的界面设计规范。
解决方案:与项目负责人确认测试标准。
开发方面:
风险:(1)所有模块开发没有统一设计,开发人员有自己的设计方式;
解决方案:与项目负责人确认标准方式,与标准方式不一致的地方全部以BUG形式提交。
风险:(2)需求变更开发。
解决方案:建议将需求变更形成文档,对没有文档的需求变更,在测试过程中发现及时与开发负责人确认,并存档相关变更文档。
测试本身:
风险:(1)人力资源;
解决方案:保证稳定的人员安排。
风险:(2)硬件资源;
解决方案:事先分析测试所需硬件资源,及时申请,保证测试工作顺利进行。
风险:(3)版本控制;
解决方案:严格控制版本,BUG以版本为单位进行提交。在测试过程中及BUG确认阶段禁止任何代码更新。
风险:(4)测试时间不足。
解决方案:动员测试人员完成测试任务,必要时,应给予相应物质奖励。
测试风险是不可避免的、总是存在的,所以对测试风险的管理非常重要,必须尽力降低测试中所存在的风险,最大程度地保证质量和满足客户的需求。在测试工作中,主要的风险有:
一、质量需求或产品的特性理解不准确,造成测试范围分析的误差,结果某些地方始终测试不到或验证的标准不对;
二、测试用例没有得到百分之百的执行,如有些测试用例被有意或无意的遗漏;
三、需求的临时/突然变化,导致设计的修改和代码的重写,测试时间不够;
四、质量标准不都是很清晰的,如适用性的测试,仁者见仁、智者见智;
五、测试用例设计不到位,忽视了一些边界条件、深层次的逻辑、用户场景等;
六、测试环境,一般不可能和实际运行环境完全一致,造成测试结果的误差;
七、有些缺陷出现频率不是百分之百,不容易被发现;如果代码质量差,软件缺陷很多,被漏检的缺陷可能性就大;
八、回归测试一般不运行全部测试用例,是有选择性的执行,必然带来风险。
前面三种风险是可以避免的,而四至七的四种风险是不能避免的,可以降到最低。最后一种回归测试风险是可以避免,但出于时间或成本的考虑,一般也是存在的。
做好测试进度管理可以有以下几个方面:
1、精确评估版本工作量,划分需求优先级。
2、提前协调测试相关资源
3、多层布点,层层可控。
4、按照用例优先级执行用例。
5、版本测试进度日报。
6、测试范围变更管理
接口测试:
什么是接口(API)
API全称Application Programming Interface,这里面我们其实不用去关注AP,只需要I上就可以。一个API就是一个Interface。我们无时不刻不在使用interfaces。我们乘坐电梯里面的按钮是一个interface。我们开车一个踩油门它也是一个interface。我们计算机操作系统也是有很多的接口。(这是目前个人找到比较好理解的一段解释)
接口就是一个位于复杂系统之上并且能简化你的任务,它就像一个中间人让你不需要了解详细的所有细节。那我们今天要讲的Web API就是这么一类东西。像谷歌搜索系统,它提供了搜索接口,简化了你的搜索任务。再像用户登录页面,我们只需要调用我们的登录接口,我们就可以达到登录系统的目的。
现在市面上有非常多种风格的Web API,目前最流行的是也容易访问的一种风格是REST或者叫RESTful 风格的API。从现在开始,以下我提到的所有API都是指RESTful风格的API。
什么是接口测试和为什么要做接口测试
接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
现在很多系统前后端架构是分离的,从安全层面来说,只依赖前端进行限制已经完全不能满足系统的安全要求(绕过前端太容易了),需要后端同样进行控制,在这种情况下就需要从接口层面进行验证。
如今系统越来越复杂,传统的靠前端测试已经大大降低了效率,而且现在我们都推崇测试前移,希望测试能更早的介入测试,那接口测试就是一种及早介入的方式。例如传统测试,你是不是得等前后端都完成你才能进行测试,才能进行自动化代码编写。而如果是接口测试,只需要前后端定义好接口,那这时自动化就可以介入编写接口自动化测试代码,手工测试只需要后端代码完成就可以介入测试后端逻辑而不用等待前端工作完成。
接口测试的策略
接口测试也是属于功能测试,所以跟我们以往的功能测试流程并没有太大区别,测试流程依旧是:1.测试接口文档(需求文档) 2.根据接口文档编写测试用例(用例编写完全可以按照以往规则来编写,例如等价类划分,边界值等设计方法)3. 执行测试,查看不同的参数请求,接口的返回的数据是否达到预期。
对于有系统大量并发访问,你会如何做测试,有什么建议
如何做高并发系统的测试,一般而言,整体的测试策略是:先针对部分系统进行性能测试及压力测试,得到各部分的峰值处理性能,再模拟整体流程测试,重点测试整体业务流程以及业务预期负荷,着重测试以下几点:
1、不同省份,不同运营商CDN节点性能,可采用典型压力测试方案
2、核心机房BGP网络带宽,此部分重点在于测试各运行商的BGP网络可靠性,实际速率,一般采用smokeping,lxChariot等工具
3、各类硬件设备性能,一般采用专业的网络设备测试工具
4、各类服务器并发性能,分布式处理能力,可采用压力测试方案工具
5、业务系统性能,采用业务系统压力测试方案
6、数据库处理性能,这部分需要结合业务系统进行测试,以获取核心业务场景下的数据库的TPS/QPS,
7、如果有支付功能,需要进行支付渠道接口及分流测试,此部分相对而言可能是最大的瓶颈所在,此外还涉及备份方案,容灾方案,业务降级方案的测试。
关于python的自动化测试知识
python激活:http://idea.medeming.com/jet/
用requests 来实现 RESTFUL API 测试。
Selenium 来实现网站测试。
Appium 来实现App 测试。
其实对很多测试开发岗位来说,你不会算法都没事,一般的自动化测试工具对性能要求是比较低的,能把业务逻辑实现了才是关键。
其次,熟悉 Python 常见内库。这样你在实现一些业务逻辑或者功能的时候,能很快想到用哪个内嵌的模块,或者第三方模块。Python 开发速度快很重要的一个原因就是有非常丰富的自有库和第三方库。
然后,熟悉接口测试中的 Requests,APP 自动化测试 Appium, Web自动化的 Selenium,数据库的连接和操作库 pymysql,还可以简单的了解下 Windows 下 GUI 的自动化测试库 pywinauto。
接着,学习 UnitTest, pytest, page object 的设计模式,掌握大型的自动化测试工具的设计思路。当然,最后要实现持续集成,快速测试、迭代,你还需要学习 Jenkins。
最后,Just Do It! 实践是检验真理的唯一标准,代码是检验你学习效果的最好途径,把你实际工作中重复的、或者手工很麻烦的事情,尝试用 Python 来实现它!
另外,最好能找到一个既懂 Python 又懂测试开发的导师或朋友,请教学习规划和建议,最重要是在遇到卡壳的地方请他指点,这样会事半功倍,少走很多弯路。
unittest框架
》》》》》》》》》》》》》》》》》》。参考文章:
Python中的单元测试模块Unittest快速入门
介绍2
1.用setUp与setUpClass区别
setup():每个测试case运行前运行
teardown():每个测试case运行完后执行
setUpClass():必须使用@classmethod 装饰器,所有case运行前只运行一次
tearDownClass():必须使用@classmethod装饰器,所有case运行完后只运行一次
一、项目构建
1、建立项目chen
打开pycharm左上角File>New Project,在Location输入testing项目所在文件夹D:chen,创建后选择Opin in current window。
2、创建子文件夹
PS:创建文件夹,一定要选Python Package的方式创建。
3、创建测试脚本
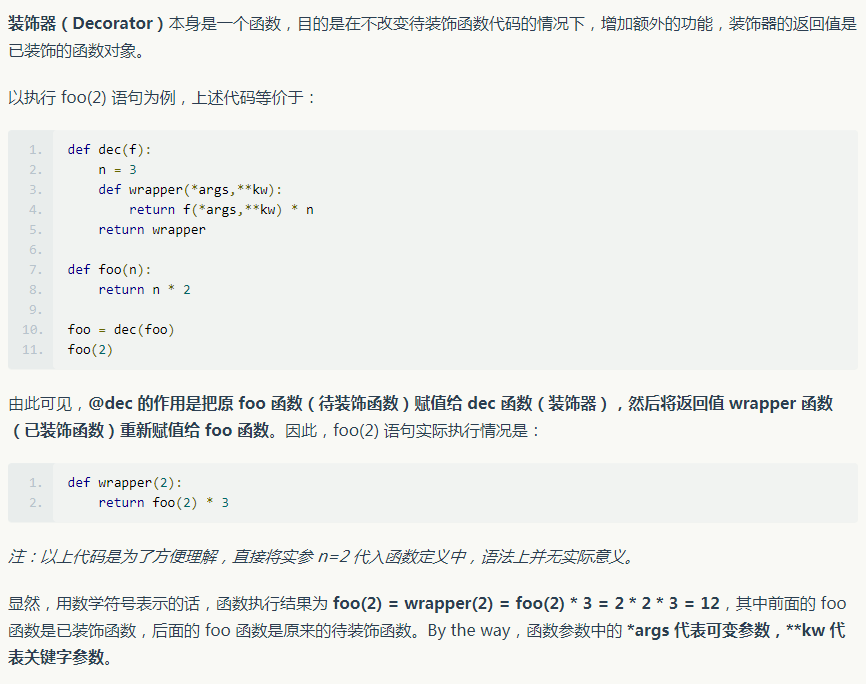
foo(n) = n * 2 * 3
-
isinstance(object,classinfo)
用于判断object是否是classinfo的一个实例,或者object是否是classinfo类的子类的一个实例,如果是返回True.
issubclass(class,classinfo),用于判断class是否是classinfo类的子类,如果是返回True -
_xxx
不能用’from module import *’导入 (相当于protected)
xxx 系统定义名字 (系统内置的,比如关键字)
__xxx 类中的私有变量名 (privated),所以更加不能使用from module import进行导入了 -
一次读取多个输入值可以这样,
a,b,c = input(‘enter a b c: ‘).split()
5.Linux
基本指令:略
- echo
echo hello >> file;
echo world > file;
使用>>指令向文件追加内容,原内容将保存。
使用>指令覆盖文件原内容并重新输入内容,若文件不存在则创建文件。
6.数据库
软件测试笔试——数据库题型
1.单表查询
【条件】:
| operator |example |
|!= ,=| |
| (not) between…and…| |
| (not) in…| in (1,2,3) |
like:查通配符
2.多表查询
- major表:mno, mname
- stu: sno, sname, age, sex,mno
- cou: cno ,cname, ctime, ccredit
- sc: sno, cno, grade
等值连接
--查询每个学生和选修课程信息select stu.*,sc.* from stu,sc where stu.sno=sc.sno--选修’2020‘的学生姓名select sname from stu,sc where stu.sno=sc.sno and sc.cno='2020' --查询每个学生和选修课程信息和学时select
来源:小棉袄_
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!