浅谈网络爬虫
- 什么是网络爬虫/li>
- 爬虫能干什么
-
- 搜索引擎
- 抢票、刷票等自动化软件
- 部分破解软件
- 金融等行业数据挖掘、分析数据来源
- 其他
- 爬虫很简单
-
- 语言的选择
- 两种语言的小demo
- 爬虫也不简单
-
- ip、浏览器头(User-Agent)、和cookie限制
- 需登录的验证码限制、参数限制
- JavaScript渲染/ajax加密
- 爬虫知识储备路线
-
- 1.基础语法:
- 2.正则和爬虫相关库,以及浏览器F12抓包和Fidder等抓包工具抓包
- 3.扎实的语法
- 4. 多线程、数据库、线程安全相关知识。
- 5. 分布式的概念和知识。
- 6. js进阶、逆向等知识.
- 总结
什么是网络爬虫/h1>


- 你熟知的谷歌、百度、360等搜索都是形成的一套持久运行、相对稳定的系统。当然,这类爬虫并不是大部分人都能接触的,通常这类对硬件成本和算法的要求较高,要满足一定的爬行速率、爬行策略并且你还要通过一定 ,通过文本价值和外链数量等等判权信息给搜索排名加权。具体不做过多介绍。笔者也不会。但是如果有兴趣完全可以运用开源软件或者工具做个站内搜索,或者局域搜索。这个如果有兴趣可以实现,虽然可能效果不好。
抢票、刷票等自动化软件
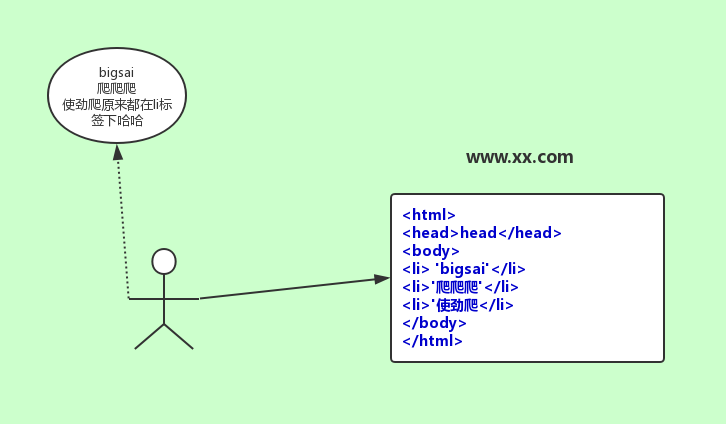
就拿一个csdn的个人主页来说https://blog.csdn.net/qq_40693171
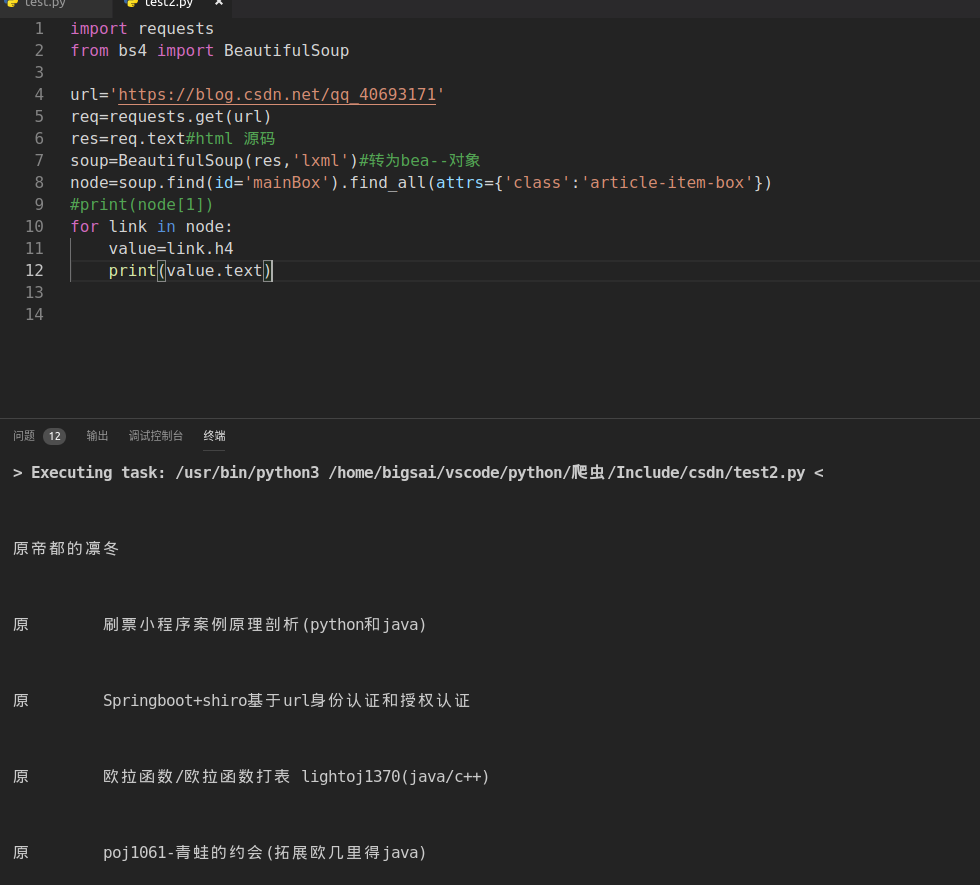
如果用java来完成
运行结果
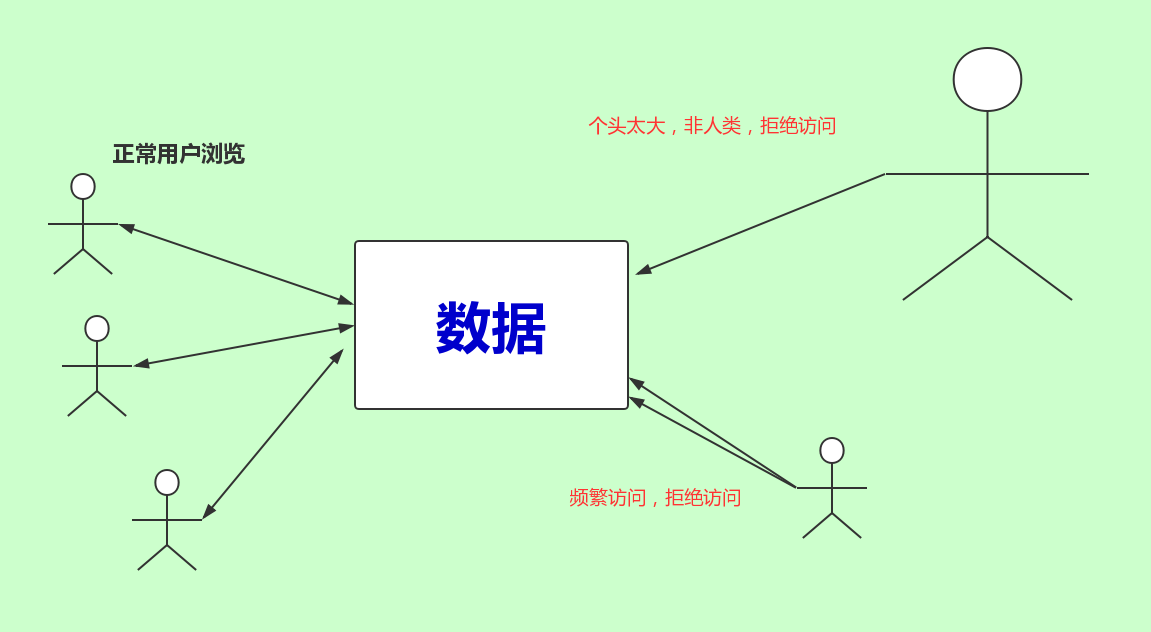
一个http请求要携带很多头信息带给后台,后台也能够获取这些信息。那百度的首页打开F12刷新
有很多数据是开放可以查看的,但是也有很多数据需要注册登录之后才能查看数据的,比如国内的各大招聘网站都需要你先登录然后才能爬取。
对于普通验证码来说,你大致有四个选择。
- 验证码,直接手动登录用网站,复制cookie放到请求的去抓取数据。这种最不智能也是最简单的方法。(pandownload就是内置一个浏览器driver然后你手动登录后它获取你的cookie信息然后一波操作)
- 将验证码下载到本地(应用),让用户识别然后登录。
- 通过人工智能和数字图像相关技术,提前好验证码识别模型,在遇到验证码时候执行程序识别。对于简单的验证码识别。也有不少开源作品。
- 通过,让第三方专业打码。
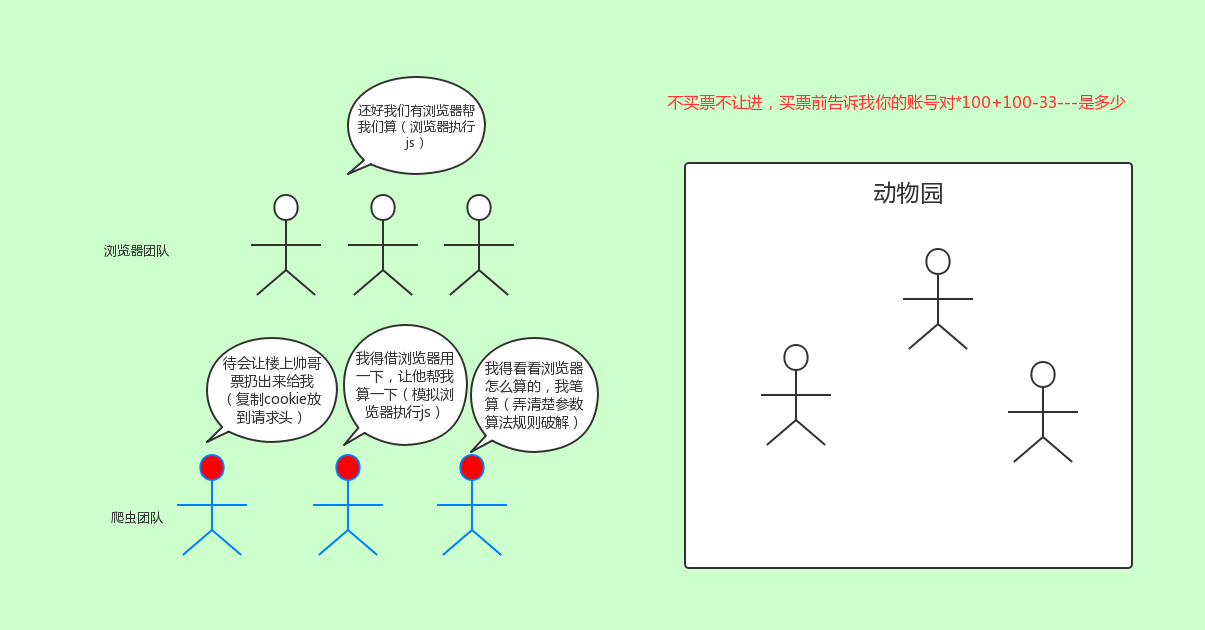
而对于滑块以及其他奇葩如滑块,点选等等,那你要么借助第三方,要么就是自己研究其中js运转流程。以及交付方式。算法原理,还是很复杂的。笔者这部分也不是特别了解。只是略知一二。
不仅如此,在登录环节,往往还会遇到一些其他参数的会放到JavaScript里面,这需要你抓到比较。有的还会针对你的数据进行加密传到后台。这就需要你娴熟的js解密能力了。
JavaScript渲染/ajax加密
- 有不少页面的数据是通过或者渲染进去的。而在数据上,爬虫无法识别、执行JavaScript代码,只能借助等模拟执行js获取数据。或者就是自己研究js流程。弄懂里面参数变化过程。但是实际是相当有难度的。毕竟人家一个团队写的逻辑,要你一个人(还不是搞前端的搞懂)真的是太困难的。所以,爬虫工程师的水平区别在解决这些复杂问题就体现出来了。
- 而异步传输如果借口暴露,或者能找到规则还好。如果做了限制,又是比较的问题。
爬虫知识储备路线
虽然一些高难度的爬虫确实很难,没有一定的工作经验和时间研究确实很难变强。但是我们还是能够通过掌握一些大众知识能够满足生活、学习的日常需求和创意。
1.基础语法:
- 无论你使用java和python,爬虫也是程序,你首先要掌握这门编程语言的语法。而基础语法入门也不需要太久,但是还是 需要一点时间,不能急于求成。
2.正则和爬虫相关库,以及浏览器F12抓包和Fidder等抓包工具抓包
- 当掌握基础语法后,爬虫一些简单好用的基本库需要花时间学习。正如上面表格所列的库。。在其中一定要学会使用抓包。简单分析请求的参数和地址等信息。而是一款强大的抓包工具。通过配置你也可以尝试抓安卓的包,爬去的数据。至于简单抓包浏览器就可以完成。推荐。
3.扎实的语法
- 因为一个爬虫项目它的,所以你需要,抓取这些数据能够。并且url遍历也需要深度优先遍历或者广度有限遍历等策略。需要熟悉这些基本算法,熟悉语言中集合模块的使用。
4. 多线程、数据库、线程安全相关知识。
- 单线程的爬虫是没灵魂的爬虫,一定要试试多线程,多进程爬虫的快感,然而这个过程可能会遇到封ip等问题,需要你自己搭建一个ip池。
5. 分布式的概念和知识。
- 一直单机的爬虫是没灵魂的爬虫。要试试多台程序多线程跑一个爬虫任务。当然,这里就会遇到分布式锁的问题。需要你对该方面稍微了解。运用。
6. js进阶、逆向等知识.
- 随着前后端分离,js流行等等,网页其实对于爬虫变得复杂,难度和学习成本也在提升。试着找一些登录网站模拟登录,调用一些开源算法等等。这部分其实才是真正大佬能力体现。当能够识别这种加密,然而其他app协议也就能慢慢解开,可能还会遇到app逆向脱壳编译等等。完成一些牛逼的事情。
总结

- 如果对等感性趣欢迎关注我的个人公众号交流:

来源:Big sai
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!