Generic Text Recognition using Long Short-Term Memory Networks
光学字符识别(OCR)的研究是模式识别(PR)中的一个老问题。 开发一台能够以与人类相同的阅读方式阅读文本的机器灵感来自于人类阅读的过程。 其实,OCR的早期系统旨在帮助盲人阅读。 几十年的研究已经产生了许多实用的系统,从后期[RH89]中的帖子分类到自动识别银行支票[GAA + 99],从手持扫描仪到阅读自然场景中文本的复杂系统[Mat15]。
将纸质文档转换为数字文档的过程通常称为文档图像分析(DIA)。 典型DIA系统的流水线如图1.1所示。 DIA中的OCR模块识别文本; 但是,由于图形,图像,页面方向和倾斜问题的存在,它不能轻易这样做。 因此,有必要将文本与给定文档图像中的非文本区域分开,并将其带到可以应用OCR模块的表单中。


针对上述许多挑战的OCR研究仍处于起步阶段。 许多复杂的现代脚本,如梵文和类似阿拉伯语的脚本,缺乏可靠的OCR系统。 历史文件的情况也是如此,其中不可用 Ground-Truth(GT)数据是开发自动识别系统的主要限制。
本文旨在通过一方面应用最先进的RNN,另一方面开发新技术来解决有限转录数据的问题,从而解决其中的一些问题。 基于RNN的方法产生了优异的OCR结果。 使用自动学习功能和简单使用的附加优势允许相同的体系结构用于各种脚本的出色结果。
这项研究工作的主要假设是基于RNN非常接近地模仿生物神经网络[GEBS04]的功能的主张。 因此,他们应该能够在很大程度上复制人类的阅读能力。 它们处理上下文信息的能力使他们能够学习序列到序列映射,使它们成为文本识别任务的合适选择。 在这种情况下,上下文在可靠地预测角色方面起着不可或缺的作用。 而且,他们的能力
自动从文本行图像中学习区别特征,使其能够处理各种脚本和语言。
下面是该论文的章节的描述:
相似性计算的公式如下所示:
2.2.2 Sequence Learning Approach
在序列学习(或[Gra12]中表示的序列标记)中,监督学习是在完整序列而不是单个组分上进行的。输入和目标都是序列的形式,分类的工作是进行序列到序列的映射。 RNN在当代序列学习任务中用作核心分类器。这种网络中隐藏层的神经元之间的反馈连接允许它们记住序列的上下文;从而使他们学习长期的背景信息。然而,在实践中,他们没有表现出记住很长时间背景的力量。在使用基于梯度下降的学习时,误差信号(实际输出和目标输出之间的差异)被传播回来以更新内部重量连接。已经证明[HS97,BSF94],一阶梯度值的值呈指数增长,爆炸梯度问题,或者它们以指数方式消失为零,消失梯度问题。这些问题使得RNN学习非常缓慢且不切实际。 Hochreiter和Schmidhuber [HS97]通过用一个称为长短期记忆(LSTM)的存储单元取代隐藏层的传统激活单元,解决了训练RNN的问题,能够保留梯度值更长的时间。
但是,神经网络需要分段输入,以便他们可以学习该输入与目标类的关联。 输入分割的这种要求使得它们不适合学习完整的序列。 在基于LSTM的序列学习任务中,在文献中描述的与HMM的前向后向算法类似的连接主义时间分类(CTC)的专用算法用于将神经网络的输出激活与目标标签对齐。 这种学习算法的输出是一系列离散标签。 对于文本识别任务,这些标签是给定的脚本系列的字符。 图2.4显示了使用序列学习范例的示例。

UNLV-ISRI数据库:UNLV-ISRI数据库[TNBC00]由1056份文件和46,586页组成。 与UW3数据库类似,此数据库中仅使用了普通文本行。
许多字符识别算法需要相当大的地面实体(Ground Truth)数据进行培训和基准测试。 训练数据的数量和质量直接影响可训练OCR模型的泛化精度。 然而,手动开发GT数据非常费力,因为它需要大量的工作来生成一个涵盖语言所有可能单词的合理数据库。 抄写历史文件更加艰苦,因为除了手动标注之外,它还需要语言专业知识。 增加的人力资源会产生开发此类数据集的财务方面,并可能限制用于OCR目的的大规模注释数据库的开发。 在前一章中已经指出,训练数据的稀缺性是为许多历史脚本和一些现代脚本开发可靠的OCR系统的限制因素之一。
本论文的以下贡献克服了有限训练数据的挑战:
?已经提出了一种半连接方法,用于在连字级别为草书脚本生成GT数据库。 该方法同样可以应用于生成字符级GT数据。 第4.2节报告了草书Nabataean脚本的此方法的特定方法。
?已开发出合成生成的文本行数据库,以加强OCR研究。 这些数据集包括Devanagari脚本(Deva-DB)的数据库,印刷的Polytonic Greek脚本(Polytonic-DB)的子集,以及用于多语言OCR(MOCR)任务的三个数据集。 第4.3节详述了这个过程,并描述了这些数据集的关键点。
在文献中已经提出了基本上两种类型的方法。 第一个是从文档图像中提取可识别的符号,并应用一些聚类方法来创建代表性的原型。 然后为这些原型分配文本标签。 第二种方法是从文本数据合成文档图像。 使用各种图像缺陷模型降低这些图像以反映扫描伪像。 这些降级模型[Bai92]包括分辨率,模糊,阈值,灵敏度,抖动,偏斜,大小,基线和字距调整。 其中一些工件在4.3节中讨论,它们用于从文本生成文本行图像。
合成训练数据的使用正在增加,并且文献中报道了许多数据集使用了这种方法。 在这些类型中突出的一个数据集是阿拉伯语印刷文本图像(APTI)数据库,其由Slimane等人提出。[SIK+09]。 该数据库是综合生成的,涵盖十种不同的阿拉伯字体和多种字体大小(范围从6到24)。 它由各种阿拉伯语来源生成,包含超过100万个单词。 使用十种字体,四种样式和十种字体大小渲染时,数字增加到超过4500万字。
合成文本行图像数据库的另一个例子是由Sabbour和Shafait [SS13]出版的乌尔都语印刷文本图像(UPTI)数据库。 该数据集包含从各种来源中选择的超过1万个独特的文本行。 每个文本行都使用各种降级参数进行综合渲染。 因此,数据库的实际大小非常大。 数据库包含文本行和连字级别的GT信息。
使扫描文档图像生成OCR数据库的过程自动化的第二种方法是使文本行的转录与文档图像对齐。 Kanungo等。 [KH99]提出了一种为扫描文档自动生成字符GT的方法。 首先使用任何排版系统以电子方式创建文档。 然后将其打印出来并进行扫描。 接下来,找到来自同一文档的两个版本的相应特征点,并估计变换的参数。 使用这些估计相应地转换理想的GT信息。 Kim和Kanungo [KK02]通过使用属性分支和绑定算法提出了该方法的改进。
4.2.1 Preprocessing
二值化是所提方法中唯一的预处理步骤; 然而,可以包括偏斜检测和校正作为进一步的预处理步骤。 局部阈值技术[SP00]用于二值化目的。 Shafait等人提出的这种算法的快速实现。 [SKB08]已被用于加速这一过程。 需要根据文档凭经验设置两个参数,即局部窗口大小和k参数。 局部窗口大小为70×70,k参数设置为0.3。
4.2.2 Ligature Extraction
可以通过两种方式进行连字提取:一种是直接在二值化图像上应用连字提取算法,另一种是在应用连字提取之前提取文本行。 前者适用于文档清晰且文本行间距清晰的情况(见图4.1-(a)),后者适用于文本行在文档中没有很好分离的情况(图4.1-(b)) ,如出现退化的历史文件。
窄线分离导致连通成分分析不良; 因此,来自上下文本行的许多连字合并在一起。 应用文本行分割的决定是基于特定文档中的行间距。 通过应用连通分量分析开始连接提取。 连接组件列表首先分为两部分,基本组件和变音符号(包括点)。 这种划分基于连通组件的高度,宽度和两者的比例。 在本章的上下文中,不考虑字体变体,主要关注的是乌尔都语书籍和杂志中常用的字体。 因此,分离主连字和变音符号的阈值是根据主要字体的大小凭经验设置的,并且对于我们数据集中的所有文档图像它们保持相同。
4.2.3 Clustering
正如已经提到的那样,由于草书中存在大量的连字,单个连字的标记变得非常不切实际。 因此,建议根据相似的形状对提取的连字进行聚类。 出于聚类的目的,采用epsilon-net聚类技术。 通过简单地改变epsilon的值,我们可以控制簇的数量。 根据经验设置epsilon的值以获得适量的集群,以便可以在验证的手动步骤中轻松管理它们。 用于epsilon聚类的特征是连字的位图。 而且,该方法比k均值聚类相对快。
4.2.4 Ligature Labeling
下一步是验证类簇并在需要时手动修改它们。 OCRopus框架提供了一个高效的图形用户界面,可以毫不费力地完成这项工作。 聚类也可能在一个以上的聚类中划分单个连字(参见图4.2-(a)),因此需要合并不同的聚类以在标记的后期节省时间。 此外,还可以修改以仅保留有效成员(与代表的标签相同的标签)的方式划分集群的步骤,将空类分配给不正确的成员,然后在空类上应用进一步的集群迭代。 在当前的工作中,在手动标记之前合并相同的连字簇,并且仅使用单个簇迭代。 在此验证步骤之后,单独检查每个群集以识别无效群集,然后将其丢弃。 OCRopus框架再次用于此目的(见图4.2-(b))。
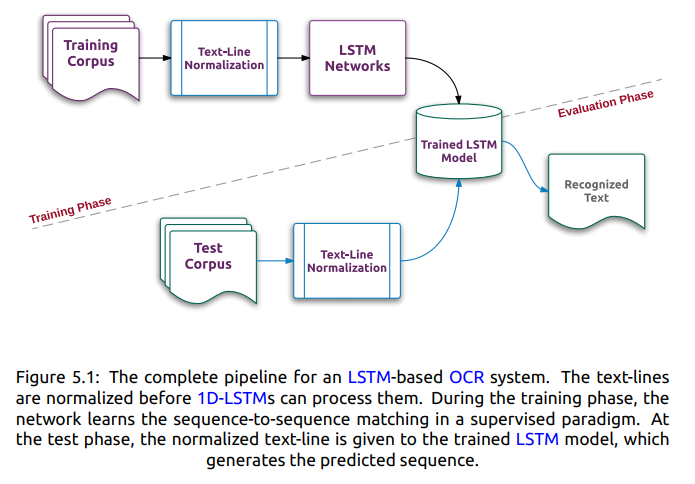
使用基于LSTM的OCR系统的完整过程如图5.1所示。 要使用1D-LSTM网络,文本行图像规范化是唯一重要的预处理步骤。 这是因为这些网络在垂直维度上不是平移不变的,因此在使用这些网络之前必须对这个维度进行固定。 本论文中使用的各种归一化方法在附录B中描述。
5.1.1 Network Parameters Selection
有四个参数,需要在使用1D-LSTM网络时进行调整:文本行图像的高度,隐藏层大小,学习速率和动量。 输入图像高度标准化取决于数据。 这些的具体值可以在相关章节中找到。 然而,对于所有实验,动量值保持在0.9。 对于剩余的两个参数(隐藏层大小和学习速率),根据经验找到合适的值。
已经进行了分析以找出Urdu Nastaleeq脚本的最佳隐藏层大小和学习速率。 总之,隐藏层大小和学习率的最佳参数分别为100和0.0001。 这些值也与其他研究人员[Gra12,GLF + 08]报道的值相匹配,并且它们也被发现与本论文报道的其他实验一致。 因此,对于本章中的所有实验以及论文其余部分中报告的那些,这些值保持固定。
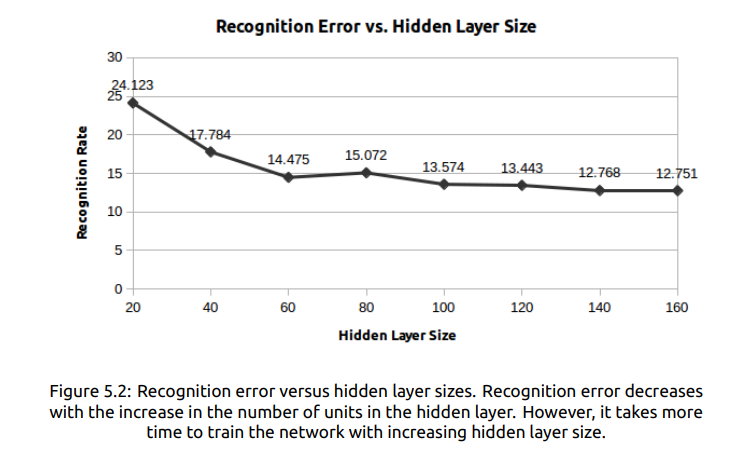
为了得到最佳隐藏层数,学习率和动量分别保持在0.0001和0.9。 已经用隐藏层训练了各种LSTM网络,该隐藏层包括20,40,60,80,100,120,140和160个LSTM单元。 测试集上各个识别错误与隐藏层大小的函数的比较如图5.2所示。 作为隐藏层大小函数的训练时间如图5.3所示。 从图5.2和图5.3中,我们可以推断出,首先,增加隐藏层大小的数量会降低识别误差,但同时,对具有大尺寸隐藏层的网络进行训练需要更多时间。 其次,训练时间的增加几乎是线性的,而当隐藏层大小从100增加到160时,隐藏层大小的增加不会使识别精度提高5%以上。因此决定选择100作为 当前工作的最佳隐藏层大小。
在下一步中,将隐藏层大小设置为100,学习率在0.001,0.0001和0.00001之间变化。 测试集上各个识别错误的比较如图5.4所示。 从图中可以明显看出,学习率为0.0001是最合适的选择。
印刷英语几十年来一直是OCR研究的主要焦点,现代OCR算法声称识别错误非常低。 然而,在实践中,将这种系统概括为新类型的现实世界文档是非常不令人满意的。 这主要是因为OCR数据的性质,这意味着应用OCR系统的新文本通常与OCR系统在培训期间看到的所有训练样本明显不同。 目前,文档分析社区中没有标准测试程序或广泛使用的数据集来解决此问题。
5.2.1 Related Work
人工神经网络用于文本识别始于20世纪70年代。 福岛[Fuk80]提出了一种自组织神经网络架构来识别模拟人物。 该网络由两个隐藏层组成,并以无人监督的方式进行训练。 该网络的结构与Hubel和Wiesel [HW65]提出的用于视觉神经系统的结构非常相似。
LeCun [LC89]引入了卷积神经网络(CNN)用于孤立的手写数字识别。 在这种类型的神经网络中,称为特征图的专用层在不同位置扫描输入图像以提取特征。 使用多个特征图从图像中提取不同的特征。
杰克尔等人。 [JBB + 95]使用上述CNN“LeNet”进行手写字符识别。 该系统基于基于分割的哲学,其中从给定的字符串开始提取单个候选字符。 然后应用LeNet来查看它是否能够以高可信度识别它。 然后,一个简单的阈值识别出以更高概率识别的候选者。 其他的被丢弃为不正确的分割。
Marinai等人。 [MGS05]介绍了人工神经网络在文档分析的各种任务中的使用情况,包括预处理,布局分析,字符分割,单词识别和签名验证。 对于OCR任务,他们将技术分为单个字符识别或单词识别。
隐马尔可夫模型(HMM)由Rabiner [Rab89]于1989年提出,它们在连续语音识别领域变得非常流行。 施瓦茨等人。 [SLMZ96]为语言无关的OCR系统改编了语音识别系统,称为“BBN BYBLOS”。 在多字母阿拉伯语OCR语料库中,他们报告的字符错误率为1.9%。 El-Mahallaway [EM08]使用HMM方法提出了一种用于阿拉伯语脚本的Omni-Font OCR系统。 然而,基于HMM的系统主要用于类似于自动语音识别的手写文本识别。
已经进行了各种尝试来开发混合ANN / HMM方法以克服基于HMM的方法的缺点。 这种系统的ANN部分提取判别特征,HMM部分用作无分割识别器。 Rashid [Ras14]报道了一种使用这种混合方法的印刷OCR系统。 在该方法中,使用多层感知器(MLP)从给定的文本行中提取特征。 为此,使用[Bre01]中报告的字符分割方法提取单个字符。 使用30×20窗口扫描在字符分割的文本行上提取特征。 为字符和非字符类提取这些功能。 AutoMLP [BS08]用于从包含非字符(垃圾)的95个类中学习它们。 然后使用标准Baum-Welch算法对HMM进行这些特征的训练。 他们报告印刷英语标准数据集的准确率为98.41%。
针对这些混合系统报道的大多数文献将MLP与HMM结合起来; 然而,Graves [GS05]描述了使用RNN / HMM混合进行音素识别。 他们报告说,使用RNN / HMM杂交产生的结果比ANN / HMM杂交或基于简单HMM的方法报告的结果更好。
在这些实验的上下文中,在预处理步骤中将文本行标准化为32的高度。 从左到右和从右到左的LSTM层都包含100个LSTM内存块。 学习率设定为1e-4,动量为0.9。 训练进行了一百万步(根据训练集的大小,大致相当于100个时期)。 每10,000个训练步骤报告测试集错误并绘制。 受过训练的LSTM网络的配置如图5.5所示。 两个隐藏层对应于LSTM网络的双向模式。
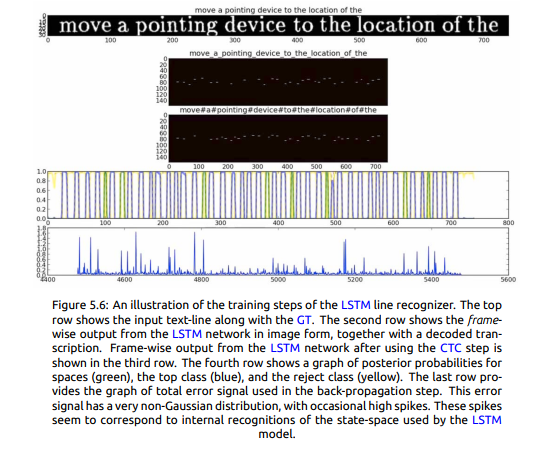
LSTM线识别器的训练步骤的说明。 顶行显示输入文本行和GT。 第二行显示来自LSTM网络的图像形式的帧输出,以及解码的转录。 使用CTC步骤后,LSTM网络的逐帧输出显示在第三行。 第四行显示空格(绿色),顶级(蓝色)和拒绝类(黄色)的后验概率图。 最后一行提供了反向传播步骤中使用的总误差信号的图表。 这个错误
信号具有非高斯分布,偶尔有高峰值。 这些尖峰似乎对应于LSTM模型使用的状态空间的内部识别。
5.2.4 Error Analysis
代表性的输入和输出如图5.8所示。 LSTM网络能够识别各种字体大小,样式和降级(触摸字符,部分字符)的文本。 当缺少某个字符的重要部分或在大写字符的情况下出现错误。
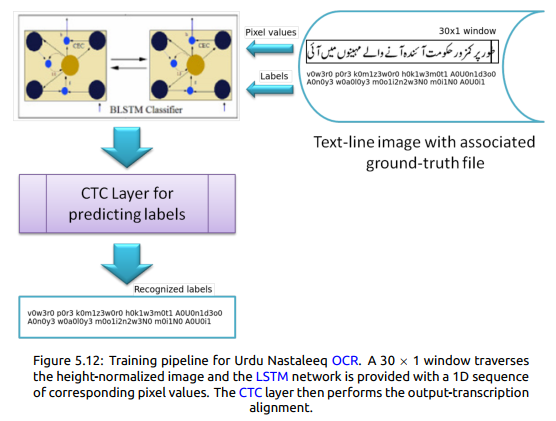
归一化的文本行图像连同它们的转录被馈送到网络,该网络首先执行前向传播步骤。 输出与相关转录的对齐在下一步骤中完成,然后执行最后向后传播步骤。 在每个时期之后,计算训练和验证错误并保存最佳结果。 当预设数量的历元的训练和验证错误没有显着变化时,停止训练。 记录训练和验证错误,并在测试集上评估网络。
参数调整将在5.1.1节中详细讨论。 简而言之,隐藏层大小和学习率的最佳值分别为100和0.0001。 对于具有最佳参数的网络,作为时期数的函数的训练和验证错误如图5.13所示。 这个网络需要77个时代汇聚。 但是,可以看出,在41个时期之后验证误差最小(在图5.13中标记为虚线)。 此网络作为最佳网络返回。
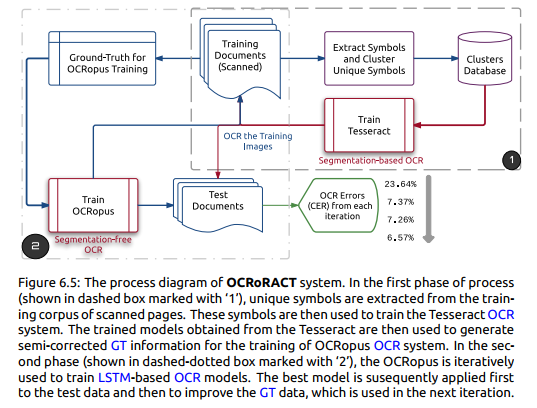
7.3 Machine Learning Based Approaches
当代机器学习(ML)技术,如深度信念网络(DBN)和深度卷积神经网络(CNN),在计算机视觉(CV)和模式识别(PR)的领域越来越受欢迎,这也是他们的原因之一。 该领域的广泛应用是它们不依赖于复杂的手工制作功能。 相反,他们从给定数据本身学习特征,并且仍然比基于手工特征的方法表现更好。 同样,最近有一些应用这些技术进行脚本识别的方法。
本章介绍的方案将脚本标识建模为多类分类问题。 单个目标类标签被分配给特定脚本的所有字符,LSTM网络在监督分类范例中学习。 文本行不会分割成单个字符; 相反,LSTM网络以序列到序列的映射方式学习脚本的形状。 换句话说,我们正在训练LSTM网络,以便为给定语言/脚本中的所有字母表学习特定的目标类标签。
图7.1显示了建议的脚本标识过程。开源OCRopus文档分析系统[OCR15]用于实验评估。 OCRopus线识别器基本上是为OCR任务设计的,其目标是转录给定的文本行;因此,所提出的想法基本上使该OCR系统适应于执行脚本识别任务。在当前设计中进行的修改以适应OCR系统非常简单。 不是在文本行中提供有关各个字符的GroundTruth(GT)信息,而是在训练阶段提供一系列类标签作为GT。为了在实践中实现这一点,修改了GT信息,使其代表了两类分类问题(见图7.1)。 修改的GT信息在训练期间用作给定文本行图像的目标序列。LSTM网络根据自己的形状以及周围形状的上下文信息来学习每个字符的类关联。 在测试阶段,训练的网络产生与文本行中的个体字符相对应的脚本标签。 它会生成一个与每个字符对应的标签字符串,如图7.2所示。网络还预测单个字符的大致位置,而这些字符又用于分离脚本。

来源:编辑尼撑
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!