2.1 程序的执行成本
优秀的程序员会让程序使用最少的计算量,就是让指令的执行时间(即执行成本)尽可能缩短。
本章重点在于让大家了解平时所写的程序如何被执行,以及每个操作对应的执行时间。
2.2 计·测·谋
衡量操作所需执行时间的程序为基准测试程序(benchmark test program)。
书中的探讨
考虑以下计算机循环执行加法运算所需时间。
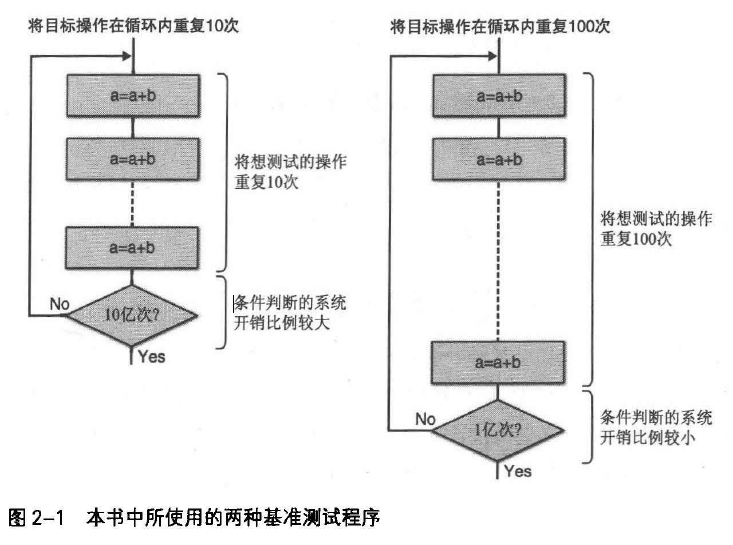

结果如图2-2所示
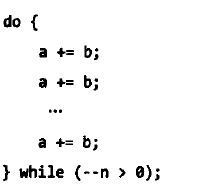
优秀的编译器,优化如下:

循环内添加标签,并在程序开始追加跳转switch代码。编译器会跳转到进行加法运算的代码块中,不会将加法运算归并为乘法运算。
防止变量在初始化时被优化
编译器会在变量初始化时堆积秦星优化。例如下面两个例子:
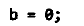
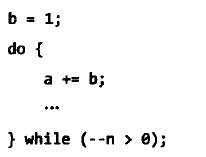
被优化为:

防止重复单一指令被优化
假设执行如下赋值操作。

编译器将“a=3”编译成movl指令,将“a+=3”编译成addl指令。
在生成的汇编代码中,asm代码作为向汇编程序传达命令的工具被输出。
编译后生成的汇编代码中被“DUMMY1”和“DUMMY2”括起来的“addl指令”将被替换成”movl指令”来执行。
本书中的基准测试程序
本节开始介绍的重复加法的基准测试程序经过防止优化处理后结果如程序2-1所示。

此处的switch代码和asm代码是为了防止在基准测试程序中出现不适当的编译器优化。
经过编译后生成汇编代码,程序2-2摘取其中重复运算的部分。

为了计算赋值运算的执行时间,可将上述重复加法的汇编语言程序中的addl指令替换为movl指令。Linux环境下操作如下:
2.4 验证——哪一步操作导致执行速度缓慢
接下来测试各种条件下数据传输、各种运算、条件跳转、函数调用等操作的执行时间。环境定义如下:
64位操作系统
- OS:CentOS 5.5
- 编译器:GCC 4.1.2
- CPU:Xeon W5580
- 主频:3.2GHz
32位操作系统环境
- OS:Red Hat Enterprise Linux 4
- 编译器:GCC 4.1.2
- CPU:Xeon W5580
- 主频:3.2GHz
按照上述方法生成基准测试程序。很多因素会导致执行时间不同,例如,做变量的加法和常量加法,编译器生成代码不同;CPU内部有多个计算器与缓存,在充分和不充分利用的情况下执行时间不同。
表2-1列举了基准测试程序,其中设置了特定条件已进行多方位测试。可在USP研究所官网上找到这些程序。
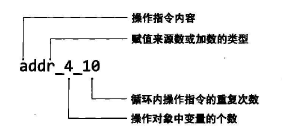
操作数或加数的类型:
“r”为变量,“c”为常量。
循环内操作数指令的重复次数:
“10” 表示单次循环重复10次操作,循环10亿次
“100” 表示单次循环重复100次操作,循环1亿次
操作对象个数:
CPU指令中,当操作对象中变量不一致时,可并行执行多条指令,因此可增加变量个数来测试执行时间。
“4” 代表重复操作中使用4个不同变量进行重复操作,使其与其他基准操作程序结果相平衡。
2.5 基础加法与赋值运算
图2-3为赋值和整数加法运算需要的执行时间,测试环境为64位。
变量间的乘法运算
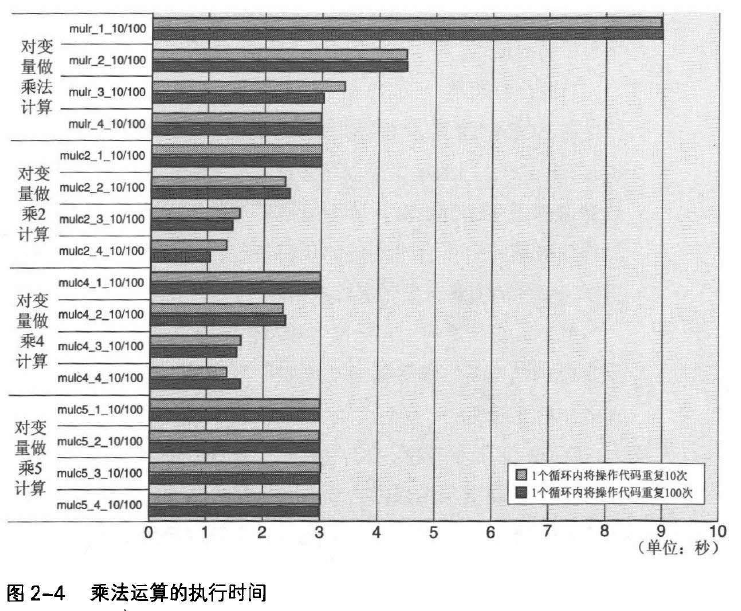
mulr_1_10/100将变量a和变量b的乘法运算重复100亿次,如下:
这里a和b相互制约,乘法运算需要等待前面的乘法运算结束后才能进行。图2-4可见,1次乘法运算需要花费0.9ns,是加法运算的三倍。
另外,增加被乘数变量个数,执行时间会缩短。原因与加法运算相同,CPU内有多个乘法计算器,能并行进行乘法运算。但是,当乘数为3个时,CPU运算速度已达到极点,可以看出,此CPU具备3个乘法运算器。
变量与常量相乘
乘法计算器是乘法运算执行成本提高。所以,当编译器进行常量乘法计算时,尽可能不使用CPU内的乘法计算器,替换为提成本操作。
常量为“2的乘方”(2、4、8……)时,可采用被乘数移位操作
图2-4中,mulc_2_10/100和mulc_4_10/100的执行时间,比变量互乘少了约1/3;常量为2和4时,执行时间差也很少。
与图2-3中变量加常量的结果对比,移位指令可将乘法运算执行时间缩短到与加法运算相同。
常量为“2的乘方+1”(3、5、9……)时,可采用lea(Load Effective Address)指令
例如,执行与常量5相乘:
编译后生成汇编代码:
lea指令本用于地址值的计算。
图2-4结果来看,使用lea指令的mulc5_1_10/100中,每次运算仅需花费0.3ns。而增加被乘数数量不会影响执行时间(只有1个计算器)。
常量为“2的乘方-1”(1、3、7……)时,可结合移位操作和加法运算
2.7 更为耗时的除法运算
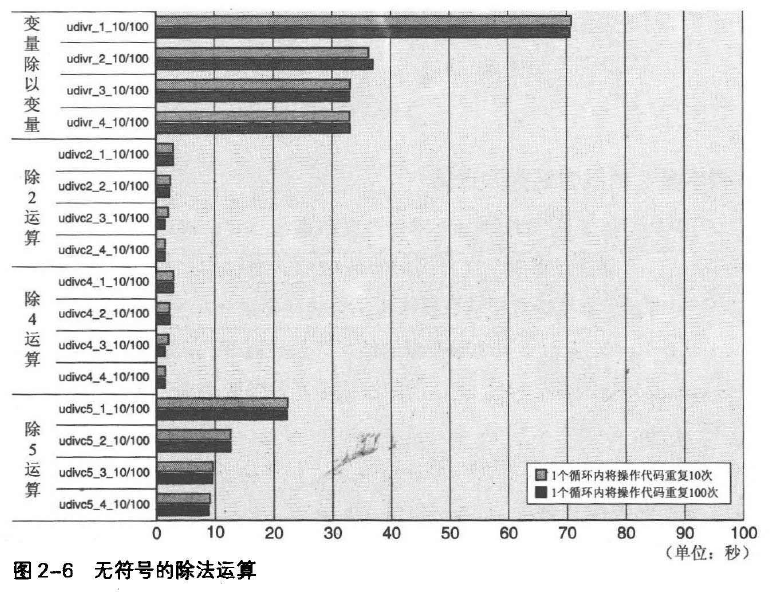
图2-5为带符号的整数除法运算的基准测试结果,图2-6为无符号整数除法运算的基准测试结果。
变量的除法(寄存器间的计算)
divr_1_10/100为重复执行int型变量a除以变量b操作的测试,如下:
变量a相互关联。根据测试显示,每次除法运算需要花费7.3ns,说明CPU中除法运算指令性能非常低。
divr_2_10/100 ~ divr_4_10/100中,将被除数变量个数增加到2 ~ 4个,如下:
divr_2_10/100中,解除了被除数之间的相互关联,运算可并行,执行时间缩短了50%。
但是继续增加被除数变量无法提升性能,因此推断CPU有2个除法计算器。
除数为2、4的除法运算
原始方法会使除法运算执行成本增加,所以编译器应尽可能不使用CPU中的除法运算指令,改用其他低成本指令。
除以2的乘方时,可通过寄存器内数据移位来提高效率。
图2-5中divc_2_10/100 ~ divc_4_10/100时变量除常量2或常量4所得结果。两者都比使用CPU内出发运算指令效率高得多。但由于常量2和常量4进行运算时负数的运算补正方法不同,执行时间有少许差异。
除数不是2的乘方的除法运算
当除数不是2的乘方,编译器会使用常量乘法运算和移位操作相结合的代码来展开操作。
以常量5除变量的结果,展开代码比常量2与4的除法运算复杂些,但比CPU除法指令快3倍,执行成本控制在乘法运算的2.5倍。
无符号整数除法运算
图2-6为unsigned char型的变量同图2-5一样进行除法运算的结果。
在CPU除法指令中,展开的udivr_1_10/100 ~ udivr_4_10/100的操作速度比带符号的除法运算快得多;常量2或4的除法运算由于采用简单的移位操作,执行时间近乎与加法运算相同。
被除数为常量的运算方法
除数为2的乘方除无符号的整数时,可采用简单的移位操作。如下图:
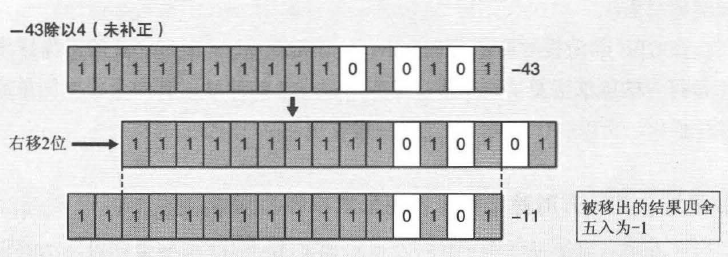
因此,在移位前通过加**剩余最大数(除数为4,剩余最大数为3)**对结果进行补正。
除数不是2的乘方时,例如n位有符号整数除以m,采用以下步骤:
- 先乘以 2 n2^n 2n/m;
- 移位操作进行 2 n2^n 2n的除法运算。
例如,对43除以3操作如下图:
小数组的读取(小范围内的内存操作)
结果如图2-7所示
读取
在mrcm_1_10/100~mrcm_4_10/100中,我们按以下方法进行数组读取。
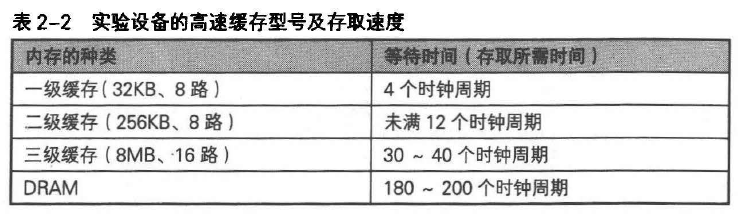
从图2-8中,mrcm_1_10 ~ mrcm_4_10比mrcm_1_100 ~ mrcm_4_100的性能明显高很多。
mrcm_1_10 ~ mrcm_4_10在320 ~ 1280KB的范围内。mrcm_1_10 执行一条指令费时0.6ns,变量个数增加到4个的mrcm_4_10,则需1.4ns。
mrcm_1_10 ~ mrcm_4_10基准测试程序中,变量个数为1时,所有数组保存在一级缓存中;变量个数增加到2、3、4个时,访问的内存范围相应扩大;数组读取每超过256KB,产生一次二级缓存未命中,此时在三级缓存中进行读取操作;但是,全部数组刚好在三级缓存处读完,执行时间最长只有原来的2倍。
另外,mrcm_1_100 ~ mrcm_4_100内存分配在3200 ~ 12800KB范围内。mrcm_1_100~mrcm_4_100中,执行1条指令需要6.8ns,十分耗时。访问时会发生二级缓存未命中情况。
写入
mwcm_1_10执行一条指令需要花费2.4ns,mwcm_1_100需要7.8ns,比读取操作更耗时。mwcm_1_10会出现二级缓存未命中的情况。
图2-8中mrcm_2_10~mrcm_4_10也开始出现二级缓存未命中,但并不代表性能会突然降低,随着访问内存扩大,会产生阶段性性能低下。
以上推断,除了LRU外,一级缓存的替换算法有PLRU或RANDOM等。
与台式机的CPU进行对比
缓存命中何时产生、对程序的执行时间有多大影响,这和CPU的缓存构成、缓存置换算法相关。下面对比台式机的CPU。
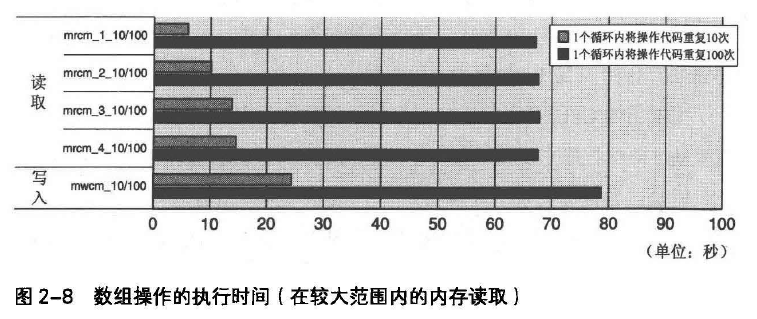
图2-9和图2-10为Athlon 64 X2 5400+上执行相同数据操作所得结果。
Athlon 64 X2 5400+的一级缓存是32KB的2路缓存,其缓存置换算法为LRU。
因此,如果每间隔32KB或其倍数分散访问3个以上内存块数据,到第2个数据块位置的值被存放于2路缓存中的某一路内,第三个值将置换出某个缓存内容。所以经常发生一级缓存未命中情况,图2-10中执行时间增加7~8倍。
以上,缓存未命中的情况会使性能大大降低。
内存访问非常耗时,编程时注意先建立数据操作,尽早将数据从内存中读出。
2.9 造成执行时间差别的判断语句
图2-11为不同情况下条件判断语句所需时间的测试结果。
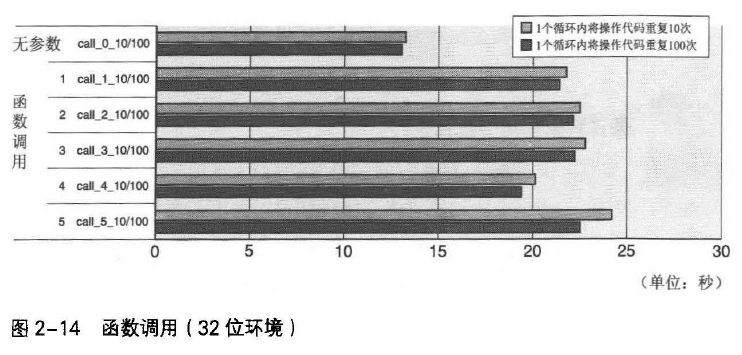
call_0_10/100为重复以下无参数函数调用的结果。
call_1_10/100 ~ call+5_10/100为重复执行以下有参数函数调用的测试结果,分别使用1~5个参数。
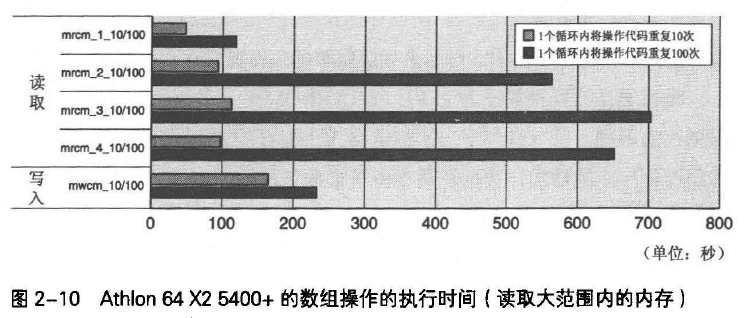
图2-13和2-14可见,64位环境中,无论有无参数,执行时间都为1.3~1.4ns;32位环境中,无参数执行时间位1.3ns,有参数位2.2ns,满了50%。
以上结果是因为参数的赋值方式不同。64位环境中,寄存器可分配整数、指针引用的参数最多6个,浮点参数最多8个,超过者被分配到内存中;32位环境中,参数全部被分配到内存的栈中。
2.11 实验总结
总结如下:
- 寄存器间的加减法运算和赋值运算速度非常快。
- 内存上的数据操作比寄存器的操作费时。
- 乘法和除法运算非常耗时,常量除法运算比一般运算快。
- 2的乘方的乘法除法运算速度快。同理,(2的乘方+1)或(2的乘方-1)和其倍数的运算也较快。
- 忽略数组长度的操作很费时。
来源:贺二公子
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!