基于音悦台网站榜单的数据爬取与分析
本实验代码:进入
一、研究背景
在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网爆炸性的发展,普通网络用户想找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的专业搜索网站便应运而生了。在Matthew?Gray的Wanderer基础上,一些编程者将传统的―蜘蛛程序工作原理作了些改进。其设想是,既然所有网页都可能有连向其他网站的链接,那么从跟踪一个网站的链接开始,就有可能检索整个互联网。到1993年底,一些基于此原理的搜索引擎开始纷纷涌现,
Jump
Station和WWW?Worm以搜索工具在数据库中找到匹配信息的先后次序排列搜索结果,因此毫无信息关联度可言。目前,互联网上有名有姓的搜索引擎已达数百家,其检索的信息量也与从前不可同日而语。比如最近风头正劲的Google,其数据库中存放的网页已达30亿之巨。
网络检索功能起于互联网内容爆炸性发展所带来的对内容检索的需求。搜索引擎不断的发展,人们的需求也在不断的提高,网络信息搜索已经成为人们每天都要进行的内容。
通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
应对于一些用户想找到好听并感兴趣的歌曲的需求不断提高,仅仅凭借手机端或者网页端机械性一个一个去找热门中的目标歌曲会十分麻烦,用户对此的查询效率也没有显著的提高和有意义的帮助,为此使用怎样的搜索引擎或者抓取有价值的数据信息去满足用户需求成为重点关注。对于网络爬虫的研究从上世纪九十年代就开始了,目前爬虫技术已经趋见成熟,网络爬虫是搜索引擎的重要组成部分。网络上比较著名的开源爬虫包括Nutch,Larbin,Heritrix。网络爬虫最重要的是网页搜索策略(广度优先和最佳度优先)和网页分析策略(基于网络拓扑的分析算法和基于网页内容的网页分析算法)。
掌握网络爬虫技术,便可以在新的大数据时代去把握数据的价值,而传统搜索引擎并不能支持定制搜索和信息处理、挖掘,可以预见互联网信息抓取、挖掘和再处理,将成为相关用户越来越多的需求,而满足这种需求的,就是各种各样的爬虫与相关的信息处理工具。现在网络上流行的信息采集工具、网站聚合工具,都是未来新一代爬虫的先驱,甚至已经具备其特点。
二、研究目的及意义
互联网可以比拟成一个庞大的非结构化的数据库,将数据有效的检索并组织呈现出来有着巨大的应用前景。搜索引擎作为一个辅助用户们检索信息的工具,成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个相对灵活的爬虫有着无可替代的重要意义。
在此研究提出,运用已经课上学习的基础爬虫技术,来解决这些对音悦台网中的热门歌曲选择性的用户需求。对应于问题提出,必然有应对的解决方案和结果,而在研究中提出榜单歌曲数据的爬取以及处理,在横向领域中都有相似的处理机制,运用爬虫技术得到用户所需要的部分信息,以此提高他们的工作效率
网络爬虫目前已经比较普遍,国内外有众多对网络爬虫的研究成果,大部分的技术难题已经有解决方案。因此本实验研究的可行性较高。
三、实验环境及技术介绍
实验环境:Python 3.5,Anaconda3;
操作系统:Windows10;
主要技术:Pycharm IDE平台,使用Python语言进行网络爬虫,依赖库主要为BeatifulSoup4以及Urllib;获取到的数据以txt文件保存,并导入到数据可视化分析软件Tableau上,同时进行数据的清洗和预处理,再使用相关统计工具进行数据分析,最后以直观的形式展现。
工程代码分为3部分:第一部分为index.py,爬虫爬取数据的主要文件;第二部分为resource.py,请求Header及ip代理;第三部分为mylog.py,记录工程运行时的流程及排除潜在问题。
数据分析模块,则使用上述所提及的Tableau平台进行数据可视化,这款软件操作简单,可以直观显示出数据关系,易于人决策自己喜欢的歌曲。
四、数据爬取
4.1 爬虫准备工作
音悦台网站榜单目标地址http://vchart.yinyuetai.com/vchart/trends如下面所示在Chrome浏览器中打开此网址后,单击F12查看网页的源代码。
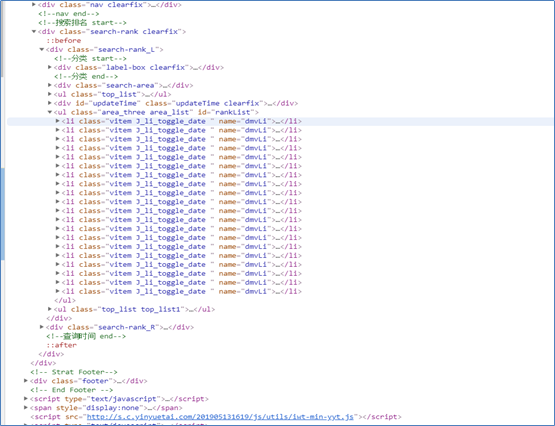

在浏览器中源代码,为了找到榜单数据所在标签,点击各个标签栏,然后会看见隐藏在源代码标签中的内容,这些内容都是后面过程中需要爬取榜单数据特征的信息,因此这里提前观察浏览这些标签里的内容。如下图所示,隐藏在标签内的内容。
4.3 index.py主文件
如下方所示,index.py所依赖的库以及标头代码内容。
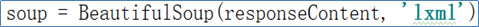
如上面代码块内容所示,Bs4支持Python标准库中的HTML解析器,还支持一些第三方的解析器,没有这个工具的话则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
Urllib库:urllib是Python中一个功能强大用于操作URL,并在爬虫时经常用到的一个基础库。其中request用于访问和读取URL,给这个库方法传入URL和其他参数就可以模拟实现读取目标网页数据的过程。其中parse用于解析URL,提供了很多URL处理方法,比如拆分、解析、合并、编码。
Random库:python中产生随机数的库,这里用于伪造随机的请求头。
Codecs库:python中进行文件的读取,这里用于对数据整合后形成txt文件的输出。
Requests库:用python语言基于urllib编写的,采用Apache2 Licensed开源协议的HTTP库,requests比urllib更加方便,可以节约大量的工作。requests是python实现的最简单易用的HTTP库。
Time库:Python提供了time模块可以用于格式化日期和时间,这里使用time模块用以形象描述暂停给定秒数后执行程序。
Resource.py文件:里面包涵请求头和代理ip,代理ip从网络平台资源中获取。有的网站进行了反爬虫设置,上述代码可能会返回一个40x之类响应码,因为该网站识别出了是爬虫在访问网站,这时需要伪装一下爬虫,让爬虫模拟用户行为,给爬虫设置headers(User-Agent)属性,模拟浏览器请求网站。
Mylog.py文件:用于写日志文件,通过查看log日志来判断index.py文件主体代码工程的是否正常running。
爬取的主要目标就是从非结构性的数据源提取结构性数据,Item对象是种简单的容器,保存了爬取到得数据。参考scrapy中item用法来封装数据,使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误,主要作用定义爬取的内容。如下面所示。

init,定义一些初始化的数据,且自动执行了self.geturls函数。如果没有在__init__中初始化对应的实例变量的话,导致后续引用实例变量会出错。

Areas为mv歌曲区域,pages为当前页数。这里提出运用for循环抓取第一页到第四页的歌曲信息。Urls则为保存下来的歌单链接,作用为urls池。在此区间内,进行第一页至第四页url抓取。Self.log.info的作用是直观使用户可以看到将当前的url地址添加到了urls池中。Self.spider就是定义爬取的动作及分析某个网页(或者是有些网页)的地方,(area,urls)这里用于榜单音乐作品所属的区域和所在页码的链接地址。如图上方所示。
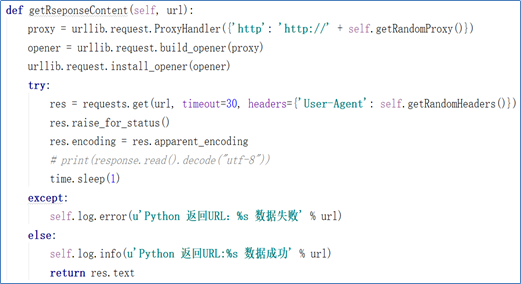
如上方所示,增加请求头以及代理ip其中,请求头部分用了一个写的随机函数,从resource中随机挑选一个请求头,代理ip部分也是。UserAgents和PROXIES两个函数在获取页面时调用。同时引入log内容,直观显示数据操作处理的过程。
Spider()函数,根据爬虫的抓取规则,从返回的数据中抓取所需的数据。

这里运用Soup.find_all(),在li字段一行,查找name=”dmvLi”的内容。
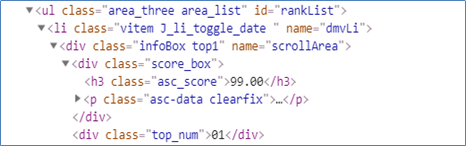
根据上方所示,获取到歌曲分数,并get_text()得到此数值。

随机选取Proxy代理地址,如上方所示。

Piplines()函数作用将所有的数据保存到 指定的txt中,此处命名为音悦台top榜单.txt。
NowTime变量作用为实时操作抓取数据时,将当时处理时间点保存下来。
并且以现有的area,即区域来分别抓取各个区域的歌曲榜单排名内容,以分割线来划分。其间运用python编程语法,%s代表字符串。
Fp.write()函数将歌曲榜单信息以for循环遍历的形式排列下来,从左依次排名、分数、发布时间、mv名字以及歌手。
并在log文件中以直观的方式来显示歌曲名字数据导入是否正确,方便用户查错。
核心代码如上方所示。

因为需要使用不同的proxy和headers来进行爬取数据。如上方所示需要代理地址和请求头。
4.5 mylog.py
引入logging、getpass以及sys模块。

榜单歌曲数据在txt文件的显示如下方所示。直接来看,第一列为排名,第二列时得分,第三列是发布时间,第四列是歌曲名字,第五列是歌手。
在PycharmIDE查看txt数据时,可以根据已有的特征,在分析工具Tableau上进行数据分析。

图5-1 榜单数据txt文件导入图
如图5-2数据内容在tableau列表中所示,第一列内容为排名以及分数,造成数据混乱,为此采用数据数值拆分,将两列数值内容从第一列中拆分出来。
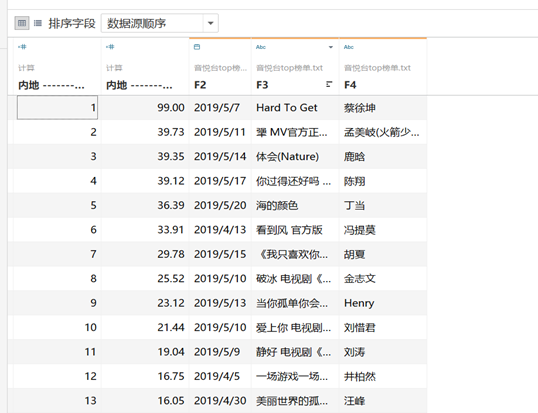
图5-3 新字段数据图
5.2 数据可视化
应用Tableau软件,将规范化数据内容在表中发挥作用,如图5-4所示。
图5-5 字段处理图
通过字段处理,可以直观看到各个音乐语言区域的各个排名都连同歌手以及对应的歌曲名字,展现在Tableau的工作表上。如图5-6歌曲排名间与分数的联系图所示。

图5-7 每周分数靠前热榜歌曲汇总图
在Tableau中,将发布时间单位改成周,且改成离散值数据类型,分数以连续型数值划分,歌手和歌手名字以离散值数据放在标签功能的标栏中,同时引入一个离散数值的分数字段数据,方便用户直观查看。
根据图5-7所示,将爬取的数据以周为单位,并以最高分区别开来划分出一个树形图,并且用颜色进行区分。
比如用户查看最近一周上榜的歌曲,5月19号那一周的数据,最高分98.95来自于女团T-ara,用鼠标划过板块会显示详细信息,方便用户查找当周最热门的歌曲信息。

图5-9 歌曲详细信息内容图
歌曲数据在tableau工作表上,将其发布时间、歌曲名字、分数以及所属周挪动到标记页面上的详细信息功能区,则鼠标滑动到表中散点处,即可使歌曲详细的内容更加直观。
而根据图5-8每周的最热门歌曲可以看出,女团组合以及Taylor Swift等在目前各自领域内仍然是大势;国内领域中,蔡徐坤新兴出道的歌手偶像也十分热门;蔡依林的《红衣女孩》也是在热播剧中火了一把。
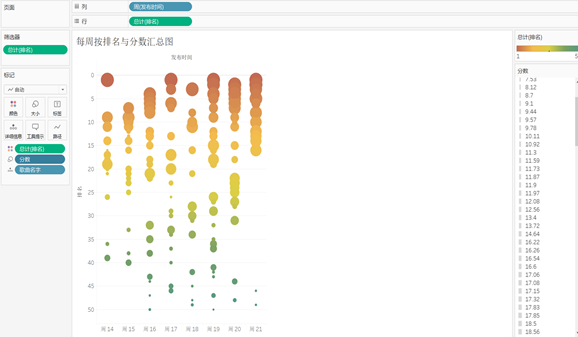
图 5-10 每周按排名与分数汇总图
周14至周21为音悦台榜单爬取的数据间隔时间,这里使用行坐标为以周为单位的发布时间,以排名降序为纵坐标。同时使用颜色区别排名,红色重度为靠前排名,绿色重度为靠后排名。利用大小视觉差异,看出分数的不同。
但是在下一次另一首歌曲上榜,名次靠后,但是分数却很高。这样的情况,在整体所有语种歌曲区间里都有不同的差异性,为此用户需要明白名次和分数并没有绝对性的关系,要找到参照因素,在某周里对比的结果会有不同,所以要尽可能选择自己的喜好因素,或者用以分数作为参考,在不同的时间里选择热门的歌曲。
5.3 分析结果
根据上述几个模型以及可视化出来的图例,进而可以推论出,从主观角度要去选择自己喜欢的歌曲,不一定非要看排名或者分数,因为这并不是绝对性的,选择上会与自己心中的期望有所差异;而从客观角度要把握热门的歌曲所处的时间时期,利用有效的搜寻方式找出排名、分数和发布时间的相关性,然后利用这些客观因素去选择大家所喜欢的歌曲。
爬取数据所得到的字段,仅仅有排名、分数、发布时间以及两个文本字串信息数据(歌曲名和歌手),所以得出的价值意义不是很高,但是仍然提供了很有效的决策。
六、总结
从定题音悦台榜单爬取数据,再到数据分析,主要工程在数据爬取阶段上。三个Py文件,除了一个请求头代理ip反爬虫的文件和一个mylog记录日志信息文件,大部分代码在于主文件上。
为了使主文件运行顺利且在输出窗口可以直观显示运行过程信息,在网络上寻找到log的函数方法,套用了此类文件的编程。
在主文件上,主要依赖库bs4使此次爬虫过程比较顺利,爬取到的数据比较规范化,且没有被拦截。
在python接口处曾遇到pandas库无法pip安装以及在pycharm上无法安装的情况,后来发现使python接口没有选择对。而数据分析上,本来想使用python上sys等分析库,后来发现更直接的数据可视化软件,也就是tableau,这为此省去了很多的工作难题。
经过张老师的课上指导,技术手段渐渐有了头绪,也大体有了一个构想。通过查阅资料,逐渐确立系统方案。在整个过程中,学到了新知识,增长了见识。
在整个数据爬取到分析上,数据内容作为原料有着很大的价值意义。有脏数据、不规范数据以及数据缺失,都可以在数据清洗处理过程中解决,因此在爬取数据的代码工程中,如何去选择框架爬取数据是很重要的。
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树网络爬虫urllib208555 人正在系统学习中
来源:莫名不知悉
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!