这篇文章主要介绍软件性能优化,主要以.net、c++、object-c 为例,内容大多是跨语言的。作为我个人的经验总结。
不同的程序员,实现同一个需求,可能会写出性能各不相同的代码。
而性能优化类似于木桶效应,要找出决定水位的那块短板。
网站低性能表现举例:
例子1:关于网站低性能的表现我举个简单的例子:一个上海的用户通过浏览器明明只想看四大名著的书名、作者、一句话概括信息、价格,结果你从北京的数据库里取出来整整四本书所有图文内容通过互联网传输给该用户。这种情况属于冗余数据的加载。优化方式很简单,就是去掉冗余数据,只取目标数据。
例子2:我们把例子1更进一步,公司决定双十一对四大名著搞促销,0元秒杀活动,双十一凌晨0点,全国可能有1万个用户同时想查询四大名著的书名、作者、一句话概括信息、价格信息。这种情况下,高并发的网络请求可能导致服务器超负荷运转甚至崩溃。这个时候就要想尽一切手段去优化性能了。比如:手段1:利用分布式缓存如redis,把四大名著的信息缓存到内存中,第一个用户访问的时候从数据库加载数据到redis,后面9999个用户都从redis里取数据,减少数据库压力。手段2:利用其他多级缓存技术,减少服务器压力。手段3:数据库、web应用程序分别部署到不同的服务器上。手段4:针对全国用户地域分布,针对性购买多台服务器,负载均衡web应用程序。手段5:提升服务器硬件设备性能。手段6:CodeReview相关代码,提升代码性能水平,减少一次请求消耗的内存、硬盘、cpu等资源,甚至用高性能框架重构代码。手段7:前后端分离,把前端静态资源和后端动态资源分离。手段8:前端优化,压缩css、js、前端图片尺寸压缩。等等等等。
性能优化可以从计算机组成、数据结构、算法、计算机网络、数据库、编译原理几个方面展开。
-
计算机组成方面:
-
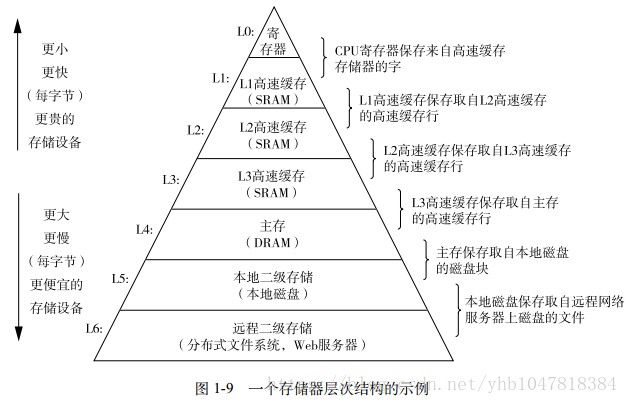
概念理解:gpu、cpu、寄存器、一级缓存、二级缓存、三级缓存、内存(主存)、固态硬盘、机械硬盘(硬盘接口分为sata口、usb口)、U盘、网络
-


-
-
具体请参考文章:
- CPU,内核,寄存器,缓存,RAM,ROM的作用和他们之间的联系/li>
-
CPU 与 Memory 内存之间的三级缓存的实现原理
-
GPU编程、GPU架构了解一下!、4倍速!ML.NET Model Builder GPU 与 CPU 对比测试
-
-
价格比较:速度越高价格越贵。(花钱,也是性能优化的一个大招)
-
性能比较:
- 运行速度上:CPU>寄存器>一级缓存>二级缓存>三级缓存>内存>固态硬盘(SATA口>USB口)>机械硬盘>U盘>网络(光纤>电缆, 有线>无线) 。
- 这里每一个 “>” 相当于一个降维打击。
- 内存与硬盘的速度比较(内容来自知乎):
-
连续读取
L1CACHE大概是100~500GB/s的水平
L3CACHE 大概是10~50G/s的水平
DDR4内存大概是3GB/s的水平
nvme ssd大概是2000MB/s的水平
SATA ssd大概是450MB/s的水平
机械硬盘大概是100~150MB/s的水平
随机读写不清楚,总之也是差n个数量级,只会比连续读写差距更大。
-
- 图像处理或矩阵运算上GPU>CPU。深度学习算法,会用到gpu加速
-
- 空间上:一般来说,寄存器<一级缓存<二级缓存<三级缓存<内存<硬盘、U盘<云存储。
- 运行速度上:CPU>寄存器>一级缓存>二级缓存>三级缓存>内存>固态硬盘(SATA口>USB口)>机械硬盘>U盘>网络(光纤>电缆, 有线>无线) 。
-
其他特性:
- 通常,数据读取(read)速度 > 数据(write)写入速度
- 虚拟内存(virtual memory):是计算机内存管理的一种技术。它使你的应用程序(进程)认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分(冷门数据)暂时存储在外部磁盘存储器上,在需要时进行数据交换。
-
掌握了这些基础知识,怎么优化软件性能/span>(深入理解计算机组成,然后组织你的代码)
-
连续内存空间读取速度比不连续内存快n倍
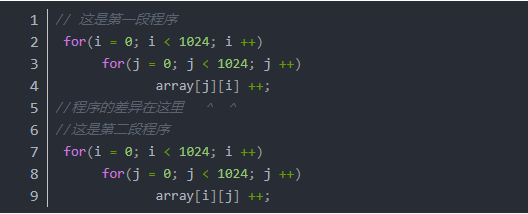
- 拿一段代码举例:(内容来自:性能优化,我们应该知道的更多一点)大家看一下下面两段程序,两段程序的作用完全相同,就是将一个二维数组中的每一个元素做加1操作。大家看一下,觉得这两段的程序是否会有性能差异strong>实际测试结果是第二段代码速度是第一段代码的四倍。
-
-
性能差异的原因分析:
-
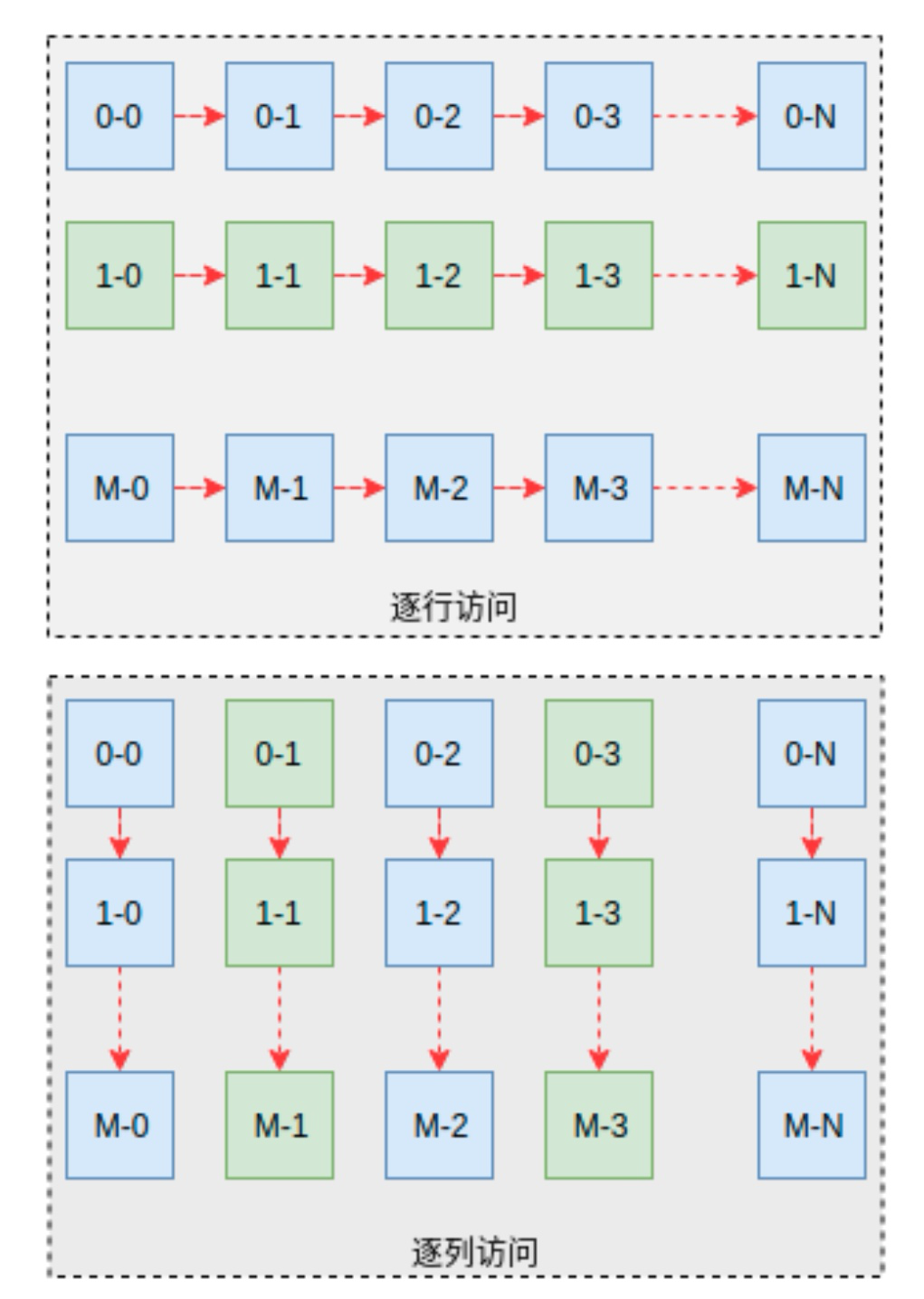
为什么有如此之大的性能差异合代码,我们看到两段代码的差异在于对数组元素的访问顺序,前者是逐列访问,而后者是逐行访问。结合图1可能会理解的更加清楚一些。然后,我们在结合C语言中二维数据数据在内存中的排布规则(可以在上述代码中通过打印地址的方式验证一下),可以知道前者是访问连续的地址空间,而后者访问的是跳跃的地址空间。
-
以整形数组为例,也就是说,前者访问的地址依次为X,X+4,X+8等等。而后者访问的地址则依次为X,X+4096,X+8192。后者每次跳跃4KB的地址空间。
了解了上述差异后,大家有没有想到性能差异的原因们知道CPU为了提升访问内存的性能,在其和内存之间增加了缓存,现代CPU缓存通常为3级缓存,分别是L1、L2和L3,其中L1和L2是CPU核独有的,而L3是同一颗CPU的多核共享的。其基本的架构如图2所示。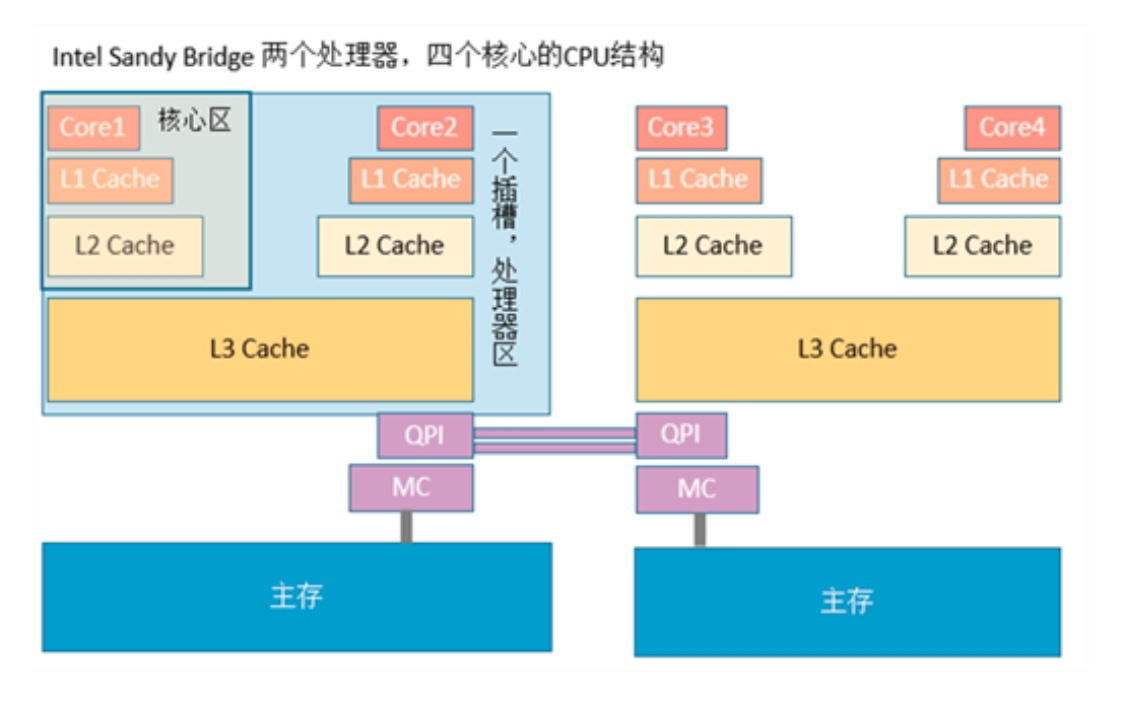
-
由于缓存分布式的特点,在多个CPU之间需要保证其一致性。扯远了,总之缓存需要切割为比较小的粒度进行管理,这个小粒度的管理单元称为缓存行(可以类比页缓存中的缓存页)。由于缓存的容量远远小于内存的容量,因此缓存无法把内存中的内容都加载其中。缓存能够作用的最主要的原因是利用的常规业务访问数据的两个特性,也就是空间局部性和时间局部性。(说白了,就是:缓存每次只能从内存中加载一行连续的内存空间,比如一行64*8位,一行64个字节,而一个普通int型变量占4个字节,所以,每次从内存中读取数据,都多读了60个连续字节到告诉缓存中,但这60个字节很可能在下一次被访问到)
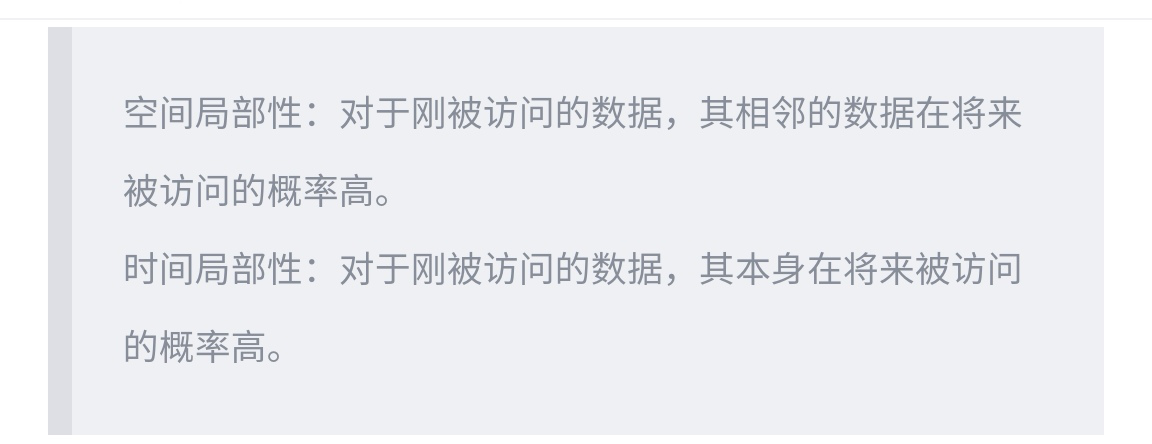
了解了上述原理,我们就知道,对于上面程序程序代码,由于第二段程序依次跳跃的太远,也就是不满足空间局部性,从而导致缓存命中失败。也就是说第二段程序其实无法访问缓存中的数据,而是直接访问的内存。而内存的访问性能要远远低于缓存的访问性能,因此就出现了文章一开始的近4倍的性能差异。
-
参考文章:性能优化,我们应该知道的更多一点
-
-
- 拿一段代码举例:(内容来自:性能优化,我们应该知道的更多一点)大家看一下下面两段程序,两段程序的作用完全相同,就是将一个二维数组中的每一个元素做加1操作。大家看一下,觉得这两段的程序是否会有性能差异strong>实际测试结果是第二段代码速度是第一段代码的四倍。
- GPU加速: 矩阵、图像运算交给GPU。(我个人感觉,在GPU资源充足的情况下,能交给GPU的全都交给GPU,解放CPU)
- 开辟io子线程,避免主线程阻塞:我们知道文件读写的任务计算机是交给硬盘来做。写文件的时候,主线程可以开辟一个子线程调用硬盘io去写文件,主线程继续做他想做的事(不阻塞主线程),只要最后子线程运行完成的时候通知一下主线程即可。
- 运用多线程加速:我们知道进程、线程都是在内存中运行,运算都在cpu中,对于内存的运行速度来说CPU简直堪比光速。所以一个主线程如果要进行一个复杂的逻辑运算(运算在CPU上),比如循环、多重循环,可以开辟n个线程分别去处理n分之一的任务,最后线程同步一下,速度提升约为n倍不到一点点(开辟、同步线程的消耗)。(一个人变身成n个人去使用cpu)当然一台普通电脑,估计8个线程同时并行运算复杂逻辑已经差不多了。
- 硬件升级加速:数据库服务(如sql server)、数据文件(mdf、ldf) 安装在SATA口的固态硬盘上,比装在机械硬盘快。
- 减少内存与硬盘或远程的连接次数 我们知道,所有持久化存储的数据都放在硬盘上,如数据库、xml、或者远程服务器上,但硬盘读写、网络加载速度太慢。对此,代码可以这么写:先把本次要查的所有数据都一次性从硬盘或网络中全部加载到内存中的一个object内,再关闭连接,从object中一个一个读数据,进行逻辑处理(用cpu),输出最终结果,如Excel、word、图片。(数据加载的时候,也可以再优化,如多线程读取、图片读取使用空间索引、数据库读取优化:多表联查、视图、存储过程、luncence等)
-
利用缓存加速:既然内存>硬盘>网络,那就可以对经常用到的数据做缓存,原理就是,一份经常用到的数据第一次从硬盘或者网络加载到内存中之后就放到内存中(全局数据区),以后每次查询都直接在内存中读取使用(如:memory chache、redis、单例模式)。参考文章:.Net 数据缓存浅析
-
- 代码质量级别优化:只改该改的,只读该读的,最大程度减少资源浪费。所以写代码的时候,保持一个好习惯:只有在真的需要修改数据的时候才去修改。比如:有一个用户想要修改自己用户名,在修改函数中,我们得知修改行为前后只有用户名发生了变化,就只需要保存新的用户名到数据库中,而不需要把用户所以其他信息(比如身份证号码、年龄)都更新一个遍(我发现很多程序员有这个偷懒的习惯)。
-
文件压缩,减负io与带宽:在客户端上传一张大图到服务器上的之后。可以根据业务需求对图片进行压缩。举例:
- 图片有损压缩:类似于微信发朋友圈,默认是压缩格式(有损压缩),原图上传之后会被微信服务器以较小损失图片质量的方式进行压缩。这样你的朋友们都能流畅但不高清地看到你朋友圈。
- 图片无损压缩(缩略图):针对微信朋友圈九宫格显示图片的特点,可以在图片上传到服务器上的时候,按等比例压缩分辨率得到缩略小图。这样你的朋友们就能在朋友圈顺畅且高清地看到你的九宫格朋友圈了。
- zip、rar压缩:文本文件被zip之后体积小很多,便于网络传输。在项目中可以
- 前端压缩:对一个网站的速度性能优化方法之一就是对请求数据的压缩。参考文章:.NET MVC中HTML&CSS&JS的压缩与混淆加密
- 集群和分布式:用多台设备解决cpu、内存、硬盘不足的问题
-
连续内存空间读取速度比不连续内存快n倍
-
概念理解:gpu、cpu、寄存器、一级缓存、二级缓存、三级缓存、内存(主存)、固态硬盘、机械硬盘(硬盘接口分为sata口、usb口)、U盘、网络
-
数据结构与算法方面:
-
利用适当的算法来优化你的程序
- 这一方面很考验一个程序员的工作经验和能力。往往是具体问题需要给出具体的解决方案。用几个我工作中遇到的例子来说:
- 问题1举例:图片富文本的性能优化问题。
- 问题分析:用户使用我们的网站或App,发推文、博客、帖子的时候会用到富文本编辑器。富文本编辑器中添加图片时编辑器会将图片转化成base64的二进制文件,如此造成整个富文本内容非常大,富文本最后以带html标签的字符串格式存到数据库长字段,回显时将此长字符串查询返回前端通过v-html来渲染成对应dom,可想而知这么大的内容提交和回显的请求都是非常耗时的,导致页面延迟高,体验差。
- 解决思路:将图片二进制文件抽离出来异步上传服务器返回图片url替换富文本中的二进制部分。异步上传服务器的时候可以顺便对图片进行低损失的压缩。
- 参考文章:富文本有图片时提交回显加载慢问题解决
-
用 StringBuilder 拼接字符串
- 我们知道,字符串 是不可变的。因此,每当你用“”+=“”拼接字符串时,就会分配一个新的字符串对象,并填充内容,最终被回收。所有这些都有昂贵开销,这就是为什么 在字符串拼接时总有更好的性能。原理是:StringBulider 的实现类似于List,每次Add,如果超过Capacity,就2倍扩展。比string类型的每次拷贝性能高了超多倍。参考文章:c#中几种字符串拼接的性能优劣对比
-
集合的初始化方式优化,比如 , 和 。所有这些集合都有动态的容量,当你添加更多的项目时,它们的大小会自动扩大。当集合达到其大小限制时,它将分配一个新的更大的内存缓冲区,这意味着要进行额外的开销去分配容量.
-
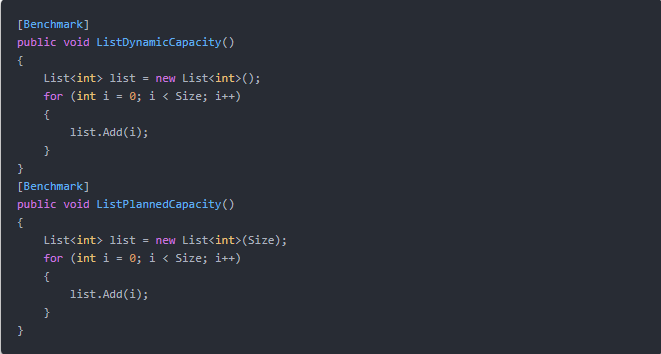
-
大数据量,如size =1000以上,下面的函数比上面的函数速度快很多倍。
-
-
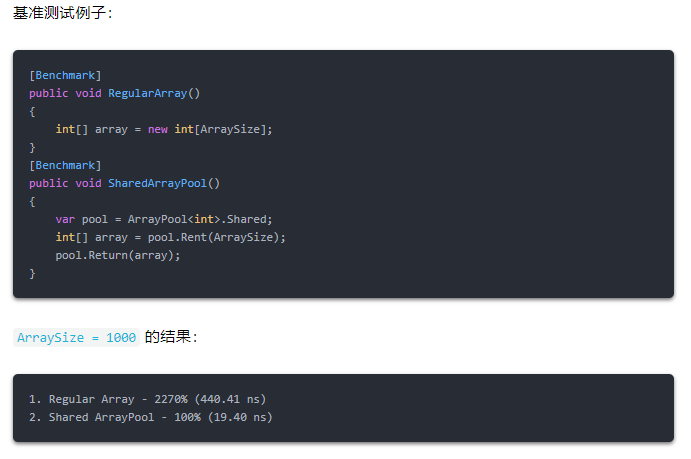
ArrayPool 用于短时大数组
数组的分配和回收的开销可能是相当昂贵的,高频地执行这些分配会增加 GC 的压力并损害性能。一个优雅的解决方案使用是 类,它可以在 NuGet 的 中找到。
这个思想和 很相似。为数组分配一个共享缓冲区,你可以重复使用,而不需要实际分配和回收它们占用的内存。基本用法是调用 ,这将返回一个常规数组,你可以以任何方式使用它。完成后,调用 将缓冲区返回到共享池中。
-
-
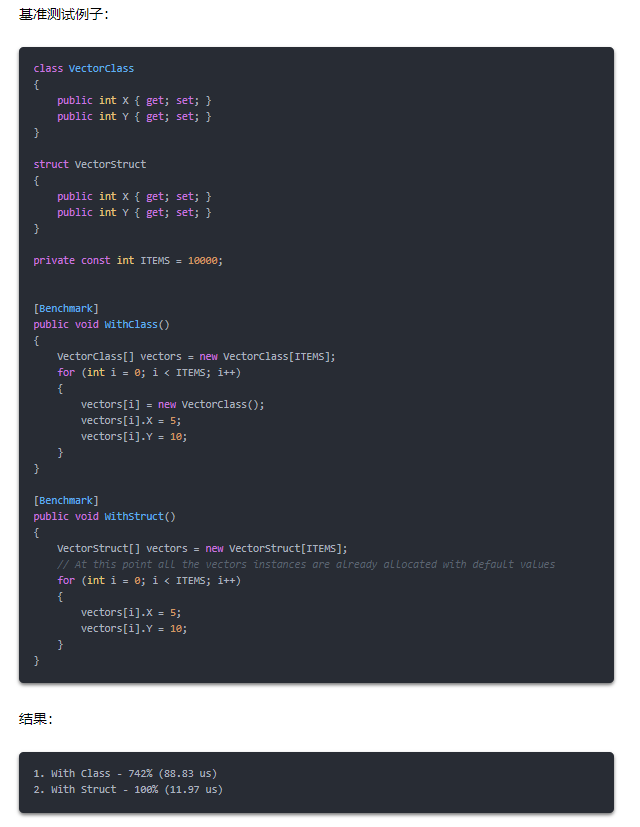
结构代替类
-
当涉及到对象回收时,Struct 有如下几个好处:
-
当结构类型不是类的一部分时,它们被分配在堆栈中,根本不需要垃圾回收。
-
当结构是类(或任何引用类型)的一部分时,它们被存储在堆中。在这种情况下,它们是内联存储的,并且会随包含类型回收而回收。内联意味着该结构的数据是按原样存储的,这与引用类型相反,在引用类型中,指针被存储到堆上另一个位置。所以回收的成本要低很多。
-
结构比引用类型占用的内存更少,因为它们没有 和 。
-
-
-
-
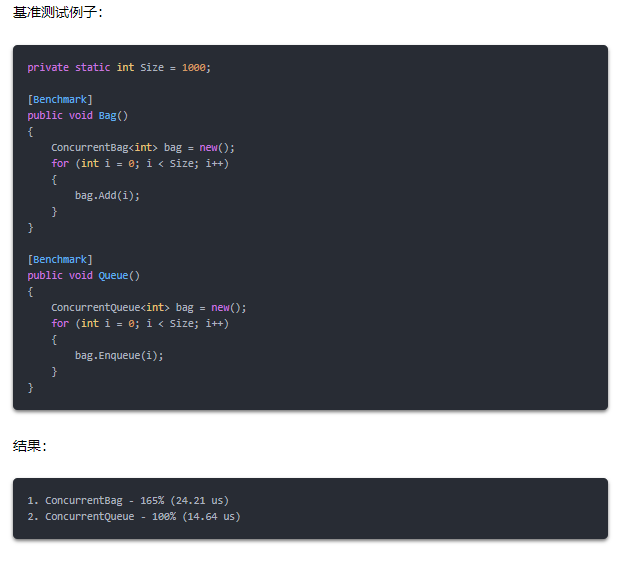
ConcurrentQueue<T> 代替 ConcurrentBag<T>
在没有基准测试的情况下,不要使用 。这个集合是为非常特殊的使用场景而设计的(当经常有项目被排队的线程删除时)。如果需要一个并发的集合队列,请选择 。
-
-
利用适当的算法来优化你的程序
-
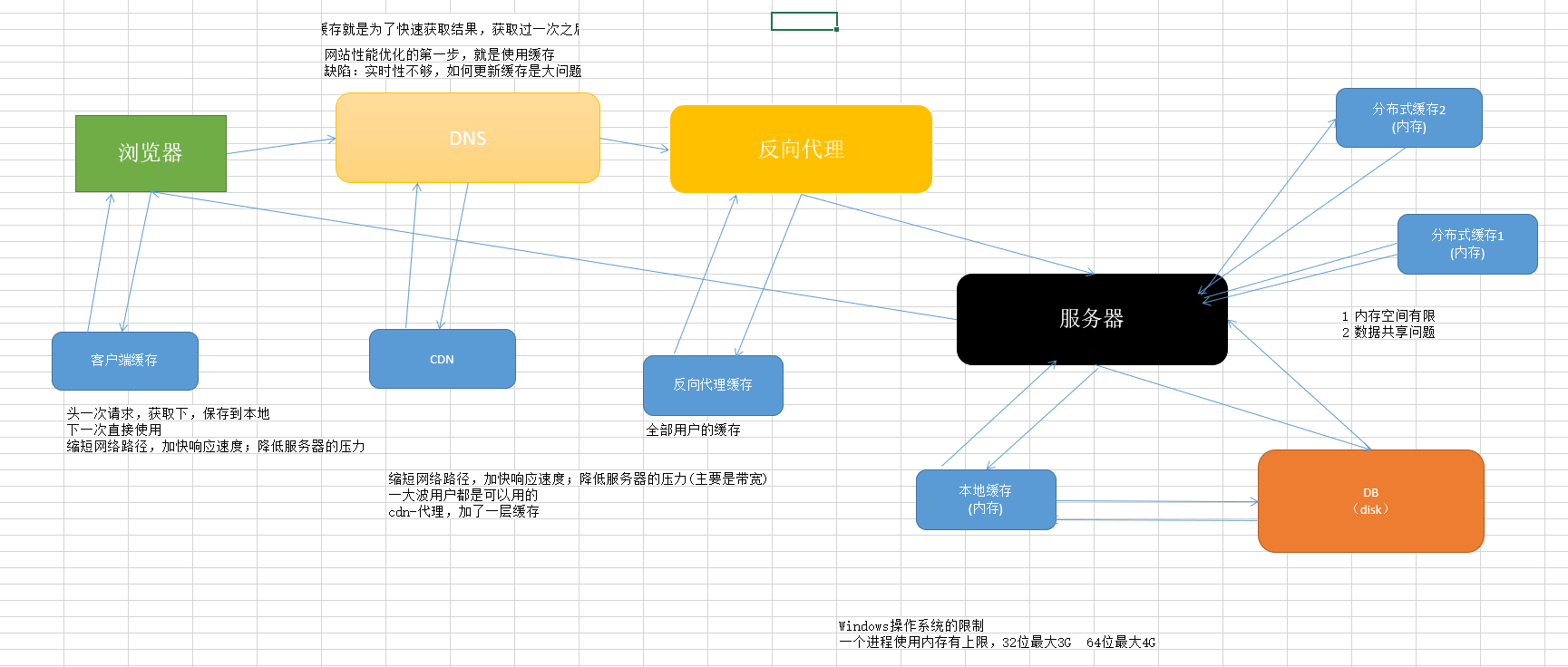
计算机网络(运维)
- 计算机网络类似于物流公司,大件和小件的物流代价天差地别。所以淘宝诞生了真空压缩棉被的商家(真空收纳袋。对应计算机技术:压缩技术)。减少了从北京服务器传输数据到杭州浏览器的运输成本。
- 前端静态文件压缩和后端响应压缩:一个网站,用户的访问分为两类,一种是前端静态文件的访问,比如css、js、静态样式图片文件
- 前端静态文件压缩:(这种方式可以返回一个压缩后的静态前端文件,体积比不压缩前小一个数量级,性能提升一个数量级)静态文件压缩是压缩的第一步。
- 另一种是动态请求数据的压缩:不同的用户访问的数据不同。场景主要是客户端访问服务器。服务器响应请求,响应内容主要是json,此时服务器可以对json压缩之后再传输到前端。主要压缩方式:GZip或者Brotli。代码实现参考文章:ASP.NET Core 中的响应压缩
- 一个Http请求的生命周期
- cdn,参考文章
- 反向代理
- 服务器优化
-
服务器性能优化:
-
以iis服务器为例,参考文章
-
iis 6 7 8预加载,提升web访速_我笔记-CSDN博客_iis 预加载
-
- 数据库配置用“localhost”比“127.0.0.1”快(localhost本身不经过网卡),“127.0.0.1”比“外网ip”快(少一次外网连接),”外网ip “比“域名”快(我猜的,少一次域名解析)
-
- 优化手段:
- 单服务器情况下,前端页面访问后端服务的时候,可以用IP地址访问,跳过域名解析服务,节省下域名解析的时间。
- 网络请求:增删改用post,查询、搜索用get。Get速度比Post快
-
数据库
- 关系型和非关系型
- 数据表都是存放在硬盘上
- 更新表的时候只更新要更新的字段。减少重复的无效修改。主从表更新的时候也只更新相关数据,比方说1条主表数据,10条从表数据,主表改了1个字段,从表改了2条数据,就只改主表的字段+从表的两条数据。(这是依据废话。但也要注意。我很久以前都是全部删除全部新增,暴力低效)
-
数据库优化方式有很多,参考文章:
-
Sql server 千万级大数据SQL查询优化
-
数据库访问性能优化
-
数据库与应用程序连接技术的优化:(以.NET为例):
-
大数据量操作时,使用bulk EF的性能优化
-
ADO.NET 的优化
-
-
- 建索引。聚集索引。索引的底层逻辑就是树。树的查询比数组或者链表快很多倍。
- 查询的时候用join代替where in。能直接用视图的就用视图。
- 用存储过程来实现统计查询。
- 用nosql来做缓存,如Redis。
- 数据库缓存,mysql8.0之前还支持数据库缓存,8.0以后弃用了数据库缓存,官方推荐使用客户端缓存如redis。
- 适当使用级联删除、级联修改,修改主表数据,从表数据自动修改。
-
编译级别优化
- 了解一个应用程序在:编译、链接、运行各个阶段和物理机的哪些硬件进行了什么交互有助于你在各个环节对程序进行优化。
- release 版本 性能 远大于 debug 版本。项目发布的时候关闭所有debug选项开关。
- 适当地使用内联函数,减少函数调用压栈的资源消耗。具体可参考文章:一文搞懂内联函数 与 C# 中的内联函数
-
从产品需求角度对程序进行优化
- 对展示内容进行分页
- 文章、新闻资讯的呈现分两页:标题列表页+单个文章详情页
-
不用改代码逻辑的提速方式
- 花钱:像阿里云服务器自带很多性能优化方式,有的是增值服务,有的买了服务器就可以直接使用:
-
- 数据类型的优化:
- 数据类型使用原则:够用就行,杜绝浪费,消耗内存或硬盘(数据库数据存放在硬盘上)空间越小越好。
- 计算机里面,(以c#为例,其他语言类似)数据类型如下:
-
bool -> System.Boolean (布尔型,其值为 true 或者 false)
byte -> System.Byte (字节型,占 1 字节,表示 8 位正整数,范围 0 ~ 255)
sbyte -> System.SByte (带符号字节型,占 1 字节,表示 8 位整数,范围 -128 ~ 127)
char -> System.Char (字符型,占有两个字节,表示 1 个 Unicode 字符)
short -> System.Int16 (短整型,占 2 字节,表示 16 位整数,范围 -32,768 ~ 32,767)
ushort -> System.UInt16 (无符号短整型,占 2 字节,表示 16 位正整数,范围 0 ~ 65,535)
uint -> System.UInt32 (无符号整型,占 4 字节,表示 32 位正整数,范围 0 ~ 4,294,967,295)
int -> System.Int32 (整型,占 4 字节,表示 32 位整数,范围 -2,147,483,648 到 2,147,483,647)
float -> System.Single (单精度浮点型,占 4 个字节)
ulong -> System.UInt64 (无符号长整型,占 8 字节,表示 64 位正整数,范围 0 ~ 大约 10 的 20 次方)
long -> System.Int64 (长整型,占 8 字节,表示 64 位整数,范围大约 -(10 的 19) 次方 到 10 的 19 次方)
double -> System.Double (双精度浮点型,占8 个字节)
-
- 一个整数变量,如果最大值不超过255,就直接用byte。整型变量能用byte存储就不要用short。能用short的就不要用int,能用int的就不要用long。
- 一个小数变量,能用float的就不要用double;
- 一个手机号,用数字存储比字符串,性能高:11位字符串是11个char,11位数字就一个长整型 ,用长整型匹配一次就够。
- 计算机里面除法比乘法慢,乘法比加减慢,位运算比加减快;所以:
-
能用位运算的都用位运算;
-
float 或者 double 类型变量能用乘法的就不用除法。比如除以3,可以写成乘以0.3333;
-
函数参数是数组的情况(c#为例):void function(List list) 这种写法,属于值传递,会在function内部拷贝另一份list。如果函数体内不对list进行修改,可以直接传如list的引用。即:function (ref list)。函数定义:void function( ref List list)
-
- 花钱:像阿里云服务器自带很多性能优化方式,有的是增值服务,有的买了服务器就可以直接使用:
-
坐享其成的优化手段:
-
学会享用别人的劳动果实:使用最新的框架、最新的技术。如.net core 代替 .net mvc.
-
-
代码逻辑:
- 减少运算。
- 多条件查询。把代价小的查询条件往前放。比如:年龄>20&&性别:男&&星座:白洋&&身高>175&&月薪>1万&&性格开朗&&帅气。其中,性别:男是一个bool值,可以最快排除女性的数据,放到最前面,性格可能是2-10个btye值,排在第二,星座:白洋,星座可以用12个byte值存储,范围是12,可以放在第二个。以此类推,然后依次是身高(10-300够了)、月薪、帅气的维度超级多,最复杂
- if 语句 判断条件同理。
- 数据库操作的时候,选择性能更高的工具:
- 分页:用真分页!分页是实际开发过程中减少查询压力最常用的方式。
- 以.net 为例:
- 勤于使用 NoTracking
- 算法级别的优化:
- 能用数据结构加速的就用数据结构加速:能用哈希表的就不要用树,能用树的就不要用数组,能用数组的就不要用链表。当然数据结构的选择主要依据的是你的代码逻辑;
- 排序算法算法的选择:好像快速排序最快(sort应该就是快速排序);
- 算法能用第三方库的就不要自己写。毕竟人家第三方库可能耗费了大量的人力物力沉淀了很多年,能发现的bug和考虑到的情况比我们自己写多了太多。
- 图像算法:
- 空间索引。
- 提高代码可读性,命名规范,删除并不起作用的无效代码。
- 耗时操作,用多线程来操作;
- 减少内存泄漏,要熟练使用内存泄漏工具查找内存泄漏。
- 能重新设计更强健快速的代码逻辑的就重新设计;
- 比如递归:递归用循环实现递归比函数实现速度快很多:少了函数压栈的消耗。
- BS架构:
- 运算逻辑能放在前端就不要放在后端,能放在后端就不要放在数据库。
- 避免前端页面频繁请求后端的情况,短时间内每次后段返回都一样的情况就用缓存,如redis、浏览器缓存、数据库内对频繁调用到但不要求实时性的查询做缓存表。
- cs架构:
- 多用sqllite。
- 减少运算。
-
性能优化工具
- 我用过的性能优化工具:
- 浏览器,F12->network 查看一个页面的加载逻辑、调用哪几个接口,每个接口多久,耗时长的接口重点关照。
-
Xcode自带的Instrument工具。查内存泄漏和性能分析。
-
Visual Studio 性能查探器。使用方法参考文章
- 我用过的性能优化工具:

来源:切糕师学AI
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!