导语
??互联网三高-高可用、高扩展、高性能,这样的一个软件结构,在真实的场景中如何落地实现。如何把合适的技术放到合适的地方,才能打造出这样的架构。不要让语言本身成为限制发展的瓶颈。
文章目录
-
- 高并发下的分布式缓存
-
- 为什么要使用缓存
- Redis集群常见的两个模式
-
- 主从副本模式
- 切面模式集群
-
- 如何能让数据能均匀的分布在这三台服务器上/li>
- 总结
- 一个优雅的切片规则(一致性Hash算法)
- 一致性Hash算法是有问题的/li>
- 缓存穿透
-
- 布隆算法
-
- 布隆算法的使用
- 缓存雪崩
高并发下的分布式缓存
??这个话题在面试的时候很大可能会被问道,在缓存的使用上,现在使用比较多的就是Memcache和Redis。而现在使用最多的就是这个Redis。那么为什么从Memcache迁移到Redis呢因其实就是Redis随着不断的发展,变的越来越优秀起来。
??从所支持的数据类型来看,Memcache所支持的数据类型主要是String类型的数据,而对于Redis来说它所支持的数据类型就多了。包括 String、Map、List、ZSet、Set这些。同时Redis是一个单线程模型,在处理一些业务的时候比较方面便。
为什么要使用缓存
??在一般的场景下,我们开发的项目都是一个B/S 架构的项目,对于B/S架构的项目。如下图所示,多个客户端通过一个服务器访问数据库,数据库进行增删改查操作。
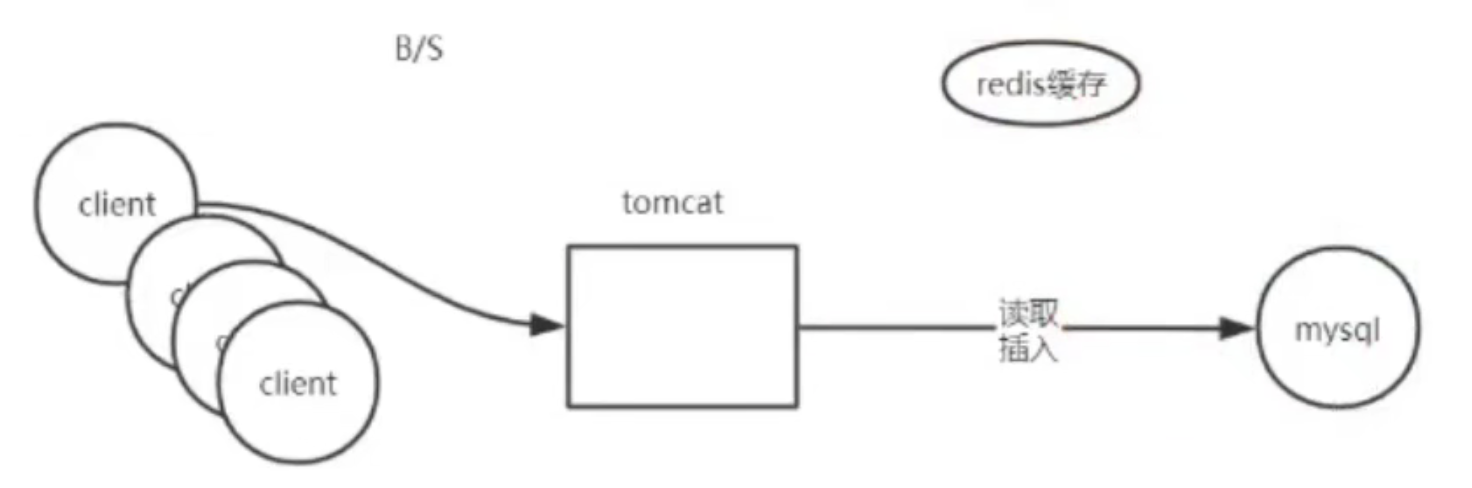

??可以把经常查询的数据称为是热点数据。将这些热点数据都存储到Redis中,当Tomcat想要到数据库中获取数据的时候。就可以先在Redis中进行查找,这样的话Redis就可以阻挡一部分对于数据库的访问数据。这样对于MySQL访问的时候就会提升一定的用户体验。

Redis集群常见的两个模式
主从副本模式
??什么是主从模式呢是由一个Master节点和一堆Slave节点组成。而我们这里看到的Master就是用来管理这些Slave节点的。
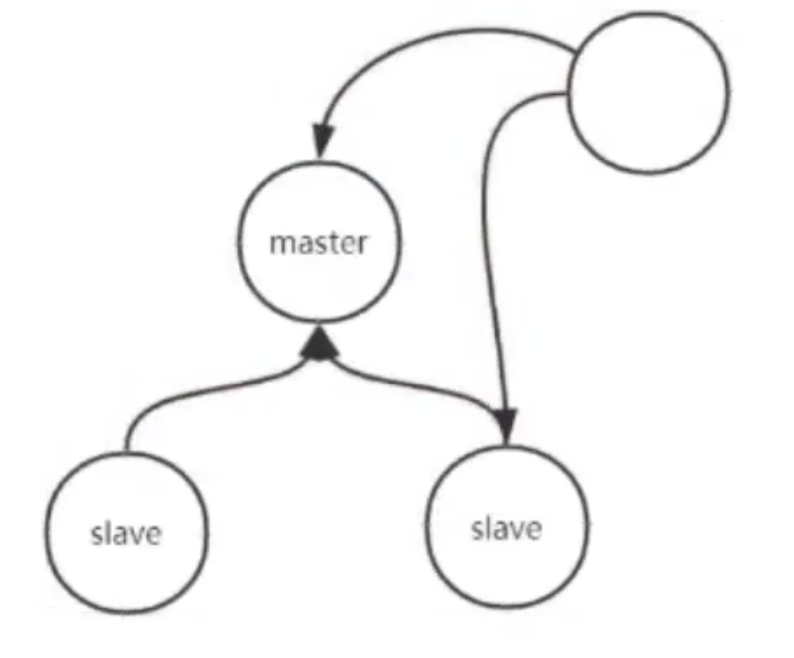
??那么搭建这样一个集群能否解决海量热点数据的存储问题单的分析一下,这个集群只是实现了一个读写分离的操作,将读操作拆分到了Slave节点上,将写操作放到了Master节点上,但是它所能存储的数据总量还是由其中的每台机器所能存储的数据总量所决定的。并没有解决大的数据缓存问题。
切面模式集群
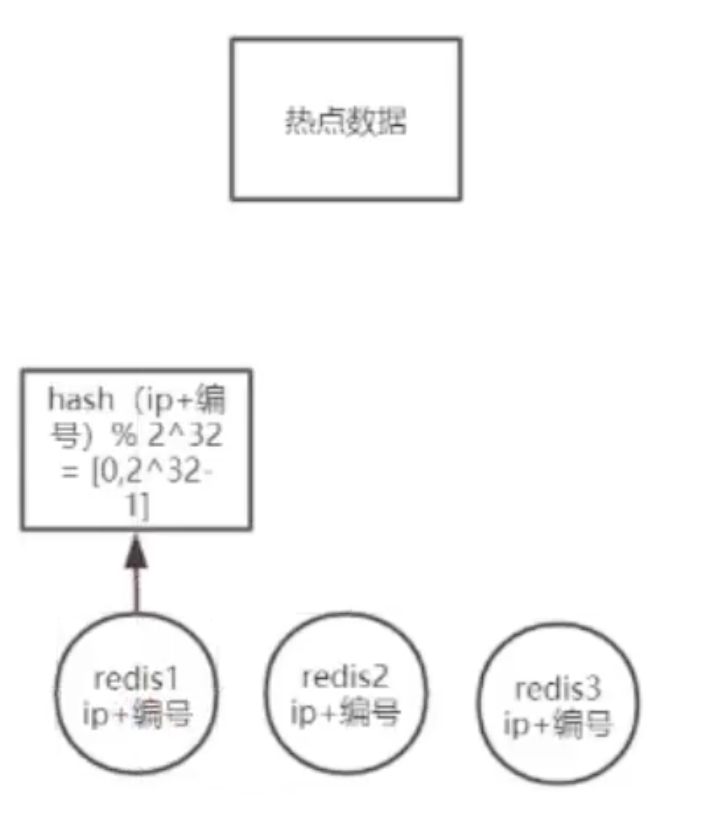
??如果我们有大量的热点数据,我们可以将这些数据按照某种规则进行切片,将这些切片存储到不同的数据库服务器上。如下图所示
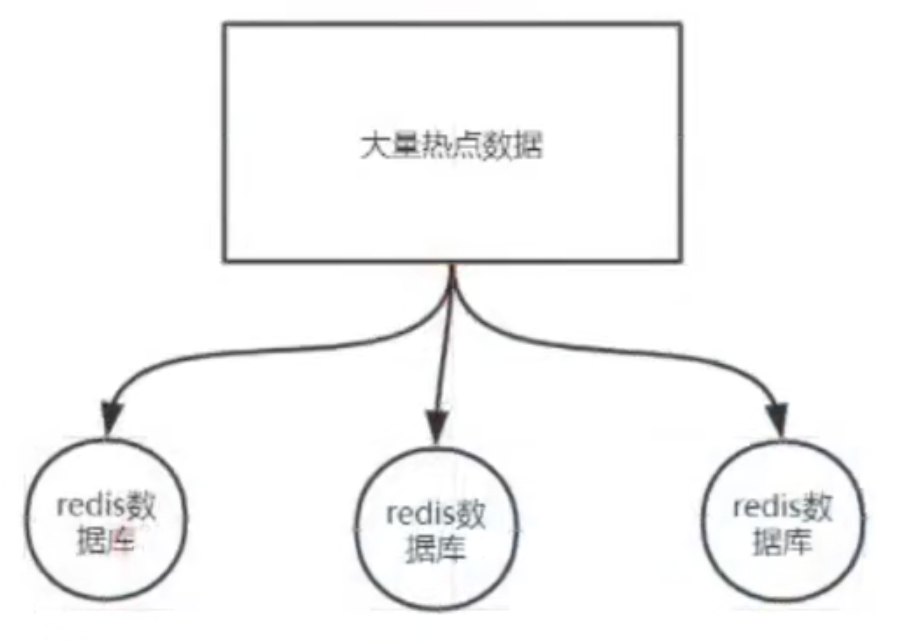
??但是这个规则好像是一点问题的,什么问题呢利于集群的扩展,这里回到上面的问题。就是需要在集群进行上下线扩展的时候它能不影响数据本身,实现一个平滑的过度。那么上面说的规则就不行了。例如,新增加一台数据库,那么新增加的这台数据库的数据量一定是比前面三台的数据量小。如图所示,那么这个时候就需要把前面三台的数据往这个数据库上进行迁移。因为你新增了一台数据库之后,你进行取模运算的时候就不在是3的模,而是4的模了,那么取模的结果就出现0、1、2、3 这四种结果。
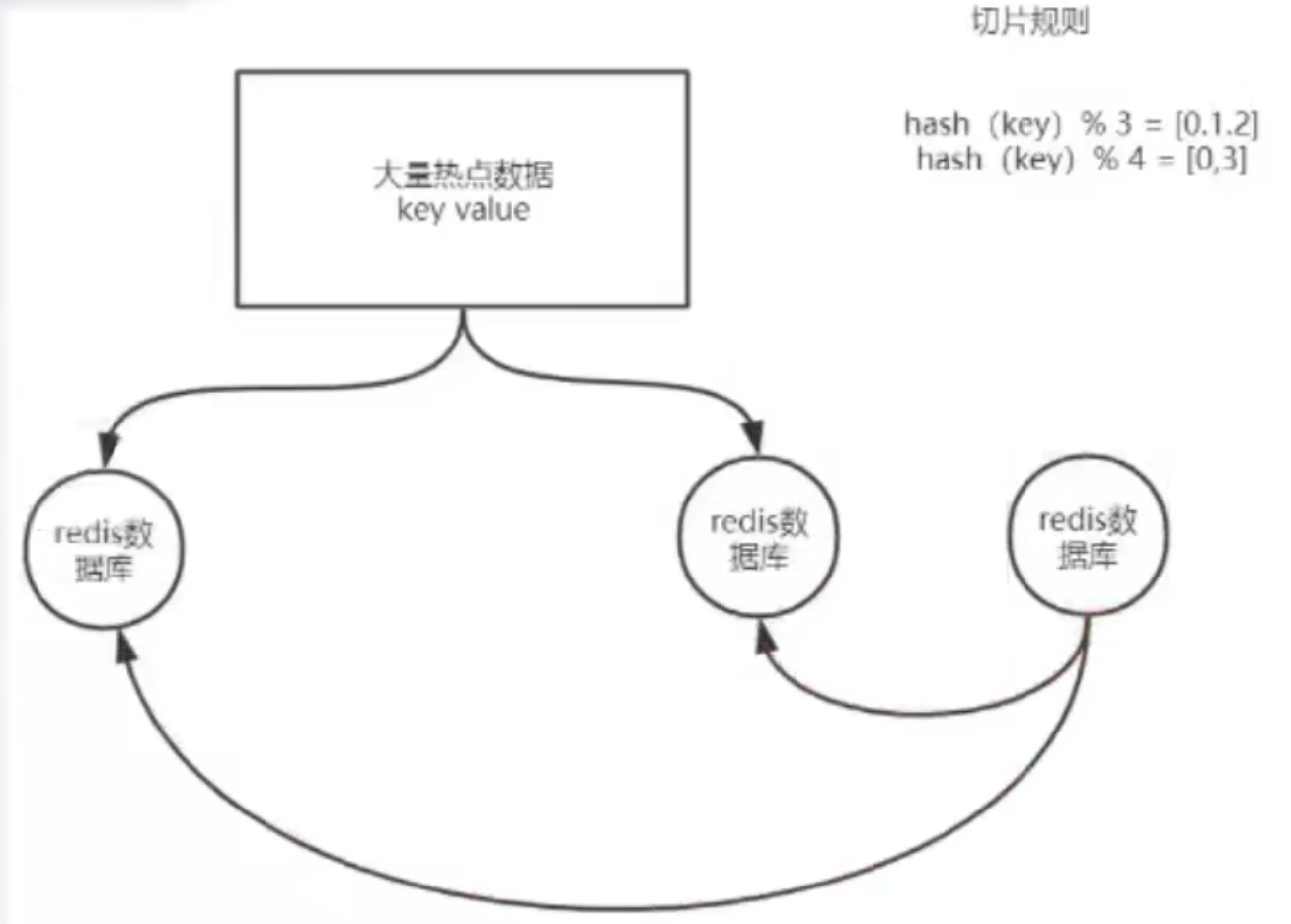
总结
??通过上面这种方式,就会导致集群中所有的Redis发生大面积的网络IO。而Redis是单线程的模式,一旦发生了网络IO操作,那么他就不能很好的往外提供服务了。就会导致大面积的Redis不可用。
一个优雅的切片规则(一致性Hash算法)
??现在有一个环,我们给这个环起一个名字叫做Hash环。如下图所示。假设一开始的时候,准备了也是三台服务器Redis1、Redis2、Redis3。数据也是很多的热点数据。
??假设映射完成之后结果如下图所示

??然后将这些数据顺时针进行查找,将数据存储在顺时针查找的第一个服务器上。
??通过这样的方式将数据与服务器关联到一起了。这样进行切片有什么好处呢就解决了集群扩展或者删除的问题。
??假设增加了一个Redis4 的服务器,那么通过上面计算完成之后它一定也在这个环的某一个位置,如图所示,我们只需要把前半段数据进行迁移到Redis4 上就可以了,原来存储在4到3 之间的数据顺时针的指向还是指向3。所以不需要进行迁移,当然删除一个服务器节点的时候也是一样的。这样就只有一台服务器的数据进行迁移。

??那么如何解决这个问题们可以在这个环上多虚拟几个Redis的点。例如将每个Redis的服务器都虚拟成2个点,都分布在这两个点,那么经过计算之后,他虚拟出来的点就会有不同的分布。

缓存穿透
??假设上面的操作完成了,这些大量的热点数据已经被我们有效的存储了,但是这个时候,如果有人往这个缓存集群中发送id=-1 的数据进行操作,那么这个时候,发现缓存中没有的话,就会到数据库中进行查询,这个时候数据库中也没有。如果有大量的这样的数据的操作,还是会导致MySQL的瘫痪。这样的话就相当于Redis集群不存在,缓存是没有的一样。这样Redis并没有起到一个限流的作用。这种情况就被称为是缓存穿透。
??缓存穿透不可怕,可怕的是大量的缓存穿透。
??这个情况也好解决,既然拿了id=-1的数据进行查询操作,那么数据库返回的数据是null,那么我们就将-1与null的键值对进行缓存。当第二次请求的时候就可以从缓存中找到对应的null的数据进行返回。但是人家也不傻,如果人家再次更换新的数据进行查询,就会导致Redis缓存被撑爆了,就会导致缓存不可用,最终还是会请求到数据库中的。当然短时间内会出现这样的问题,但是长时间的话,缓存是有一定的淘汰策略的例如说LRU、LFU等等。但是这样的话用户体验也不是太好。所以不能采用这样的方案。
??既然上面的方案是有问题的的,那么如何解决呢。可以搞一个过滤器,如果在Redis中没有找到数据,那么在这个过滤器中就保存了所有的数据库中id。经过过滤器之后,就会知道需要查找的这个数据在数据库中有没有,如果有的话操作,如果没有的话,直接将请求拒绝。但是这个过滤器,随着Mysql数据的增加,会占用大量的内存。所以需要解决过滤器内存占用过大的问题。
布隆算法
??这个时候就出现了一个算法,这个算法就是布隆算法。可以使用这个算法来降低这个过滤器的内存使用率。它是通过错误率来获取空间的占用。
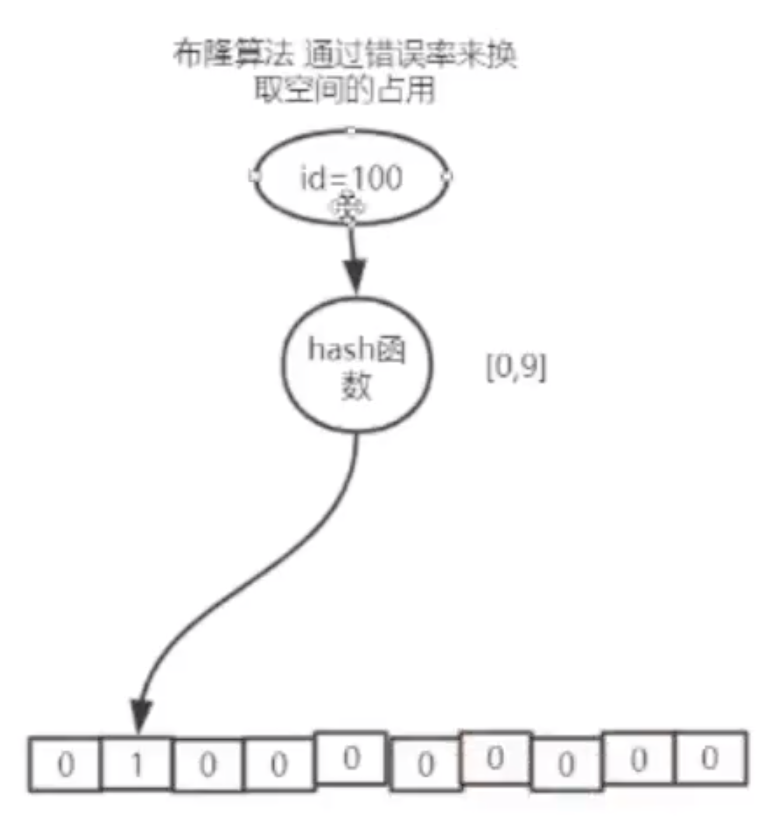
??算法原理: 它由一个二进制码数组,假设长度为10。布隆算法,就是通过这个数组中的数来标识这个MySQL里面的ID号。例如现在要标记一条id=100 的值,会把这个id值传入到一个Hash函数中,这个Hash函数的计算结果永远是在0~9之间,如果经过计算值为1 的时候,那么就会在第二个位置插入1,其他地方都是0。
??如果现在要标识一个id=999的数据也是同样的操作。
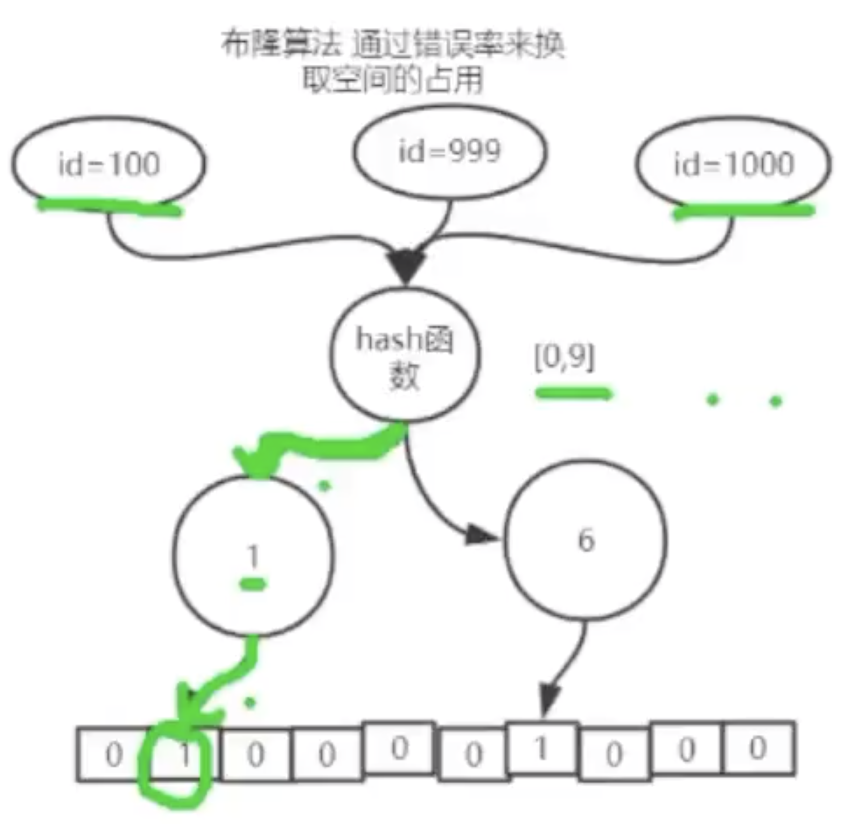
??那么当Client 请求了一个id=9988的数据,想要看一下这个数据是否被标记,那么这个值的计算结果也有可能是1,这个时候计算结果1,但是真实的情况是这条数据并没有被标识过。这其实就是一个错误率的体现。所以说如果使用布隆算法,出现数据存在,那么其实也是不一定的,那么如果使用布隆算法出现数据不存在,那么数据一定是不存在的。采用这种方式是比较节省空间的。
??也就是说使用一个比特位就可以表示一条数据存在。通过这种方式,会发现这种关系的错误率还是比较高的。那么这个错误率高的原因就是数组的长度太短了,那么如果数组的长度越长,那么hash冲突的概率就越小,将这种存储的粒度称为是装填比。也就是装填比越高,错误率越低。
??当然装填比是一个方式,那么如果我们将Hash计算的次数增多了之后呢果第一个hash的冲突的概率是1/10,第二个也是1/10,这样数量增多了之后,也会降低错误率。只有三个位置同时为1 的时候,才表示这个数存在,如果不满足的话,就说明这个数据不存在。
布隆算法的使用
??有两个文件1、2 每个文件中有100亿个url,使用最高的效率,找出文件交集,分别给出精准算法和模糊算法。
??这个问题考察的就是布隆算法。
精准的算法,采用分治法。拆分成一个个的小文件,怎么拆据Hash进行拆分,需要拆分成多少个,就对多少取模就可以了。所以只需要对比对应的小文件就可以了。而不是把第一个小文件与其他所有文件进行对比,因为没有必要。
??第一遍遍历拆分,第二遍把小文件进行比较。
 架构师面试宝典
架构师面试宝典  微信公众号
微信公众号  Java架构师成长记录,推荐一些好的Java相关
Java架构师成长记录,推荐一些好的Java相关
来源:nihui123
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!