转载请注明出处,部分内容引自banananana大神的博客
别说你不知道什么是树╮(─▽─)╭(帮你百度一下)
前置知识: d f s ” role=”presentation” style=”position: relative;”>序 L C A ” role=”presentation” style=”position: relative;”> 线段树
先来回顾两个问题:
1,将树从
这也是个模板题了吧
我们很容易想到,树上差分可以以
2,求树从x到y结点最短路径上所有节点的值之和
lca大水题,我们又很容易地想到,
然后对于每个询问,求出x,y两点的lca,利用lca的性质
时间复杂度
现在来思考一个b u g ” role=”presentation” style=”position: relative;”>:
如果刚才的两个问题结合起来,成为一道题的两种操作呢/p>
刚才的方法显然就不够优秀了(每次询问之前要跑
树链剖分华丽登场
树剖是通过轻重边剖分将树分割成多条链,然后利用数据结构来维护这些链(本质上是一种优化暴力)
首先明确概念:
重儿子:父亲节点的所有儿子中子树结点数目最多(
轻儿子:父亲节点中除了重儿子以外的儿子;
重边:父亲结点和重儿子连成的边;
轻边:父亲节点和轻儿子连成的边;
重链:由多条重边连接而成的路径;
轻链:由多条轻边连接而成的路径;
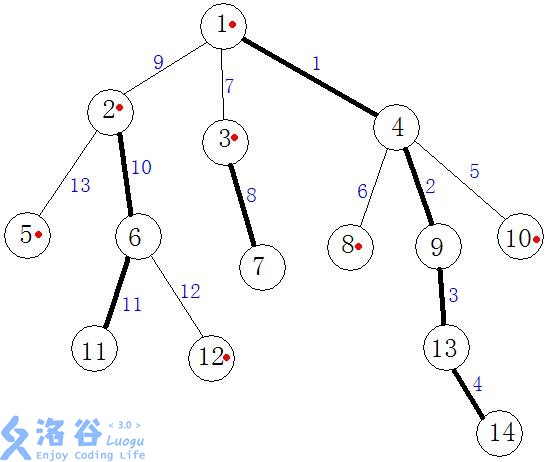

比如上面这幅图中,用黑线连接的结点都是重结点,其余均是轻结点,
2-11就是重链,2-5就是轻链,用红点标记的就是该结点所在重链的起点,也就是下文提到的
还有每条边的值其实是进行
统计学的介绍
定义:统计学是通过收集、整理、分析、描述数据等手段,以达到推测所测对象的本质,甚至预测对象未来的一门综合性学科。统计学的核心是数据。
收集数据可以用爬虫,整理数据用pandas,从几百万行中整理出需要的部分,分析数据找到规律,用可视化的形式呈现出来,描述数据也可以以可视化的形式呈现。
统计学的分类
统计学不仅可以推断数据的本质,还可以做预测。
描述统计学
定义:描述统计学是指运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动。
描述数据的集中趋势,离散程度,分布形态等都是描述统计学要做的事情。
股票分析:
1.采集股票数据,对数据进行加工处理;2.计算因子值。3.概括因子的分布特征、图表展示出来,得到相关的信息。
如果用历史的数据去推断出股票的未来走势,就要用到推断性统计学。
推断统计学
定义:推断统计学是研究如何利用样本数据来推断总体特征的统计方法,是在对样本数据进行描述的基础上,对统计总体的未知数量特征做出概率形式表述的推断。包括估计、假设检验、方差分析、相关分析、回归分析等。
描述性统计学是借用现有的数据,来计算指标,衡量数据的结果,常用的均值、中位数、标准差、方差等,而推断性统计学是以样本数据来推断总体,涉及到理和函数,x轴,y轴等。
数据分析用到的比较多的是描述性统计学的知识,机器学习。机器学习、深度学习大部分用到的是描述性加推断性统计学的知识。
二者是相辅相成的,没有好坏的区别,要看你所利用数据进行的分析。
统计学的基本概念
数据
统计学研究的核心是数据。
1000(元)、“女性”、“一年级”、[2000,4000] 等均为数据,数据不仅仅是阿拉伯数据,还有分类型的数据等。
统计学数据的分类
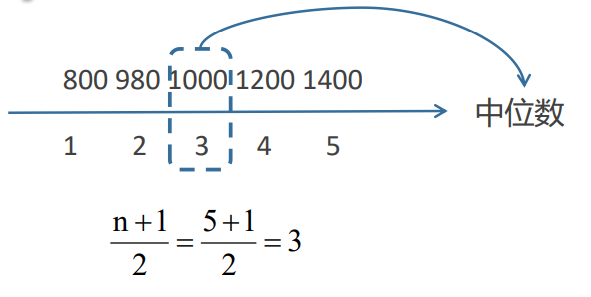
注意:计算时要先进行排序。
例题2:计算一下6个数的中位数:980,1400,1000,1200,800,1650

下四分位数: Q i Q_i Qi/span>
表示符号:
计算: n 4 frac{n}{4} 4n/span>
上四分位数:
表示符号: Q u Q_u Qu/span>
计算: 3 n 4 frac{3n}{4} 43n/span>
例题1:求以下数值的上四分位数和下四分位数。980 1400 1000 1200 800 1650 1100 1050 1500 950 900 1250

算术平均数
数据的和与数据个数之比,表示的符号为: x ˉ bar{x} xˉ
简单算术平均数(根据未分组数据计算的):
x ˉ = x 1 + x 2 + . . . + x n n = ∑ i = 1 n x i n bar{x}=frac{x_1+x_2+…+x_n}{n}=frac{sum_{i=1}^{n}{x_i}}{n} xˉ=nx1/span>+x2/span>+…+xn/span>/span>=n∑i=1n/span>xi/span>/span>
加权算术平均数(根据分组数据计算的):
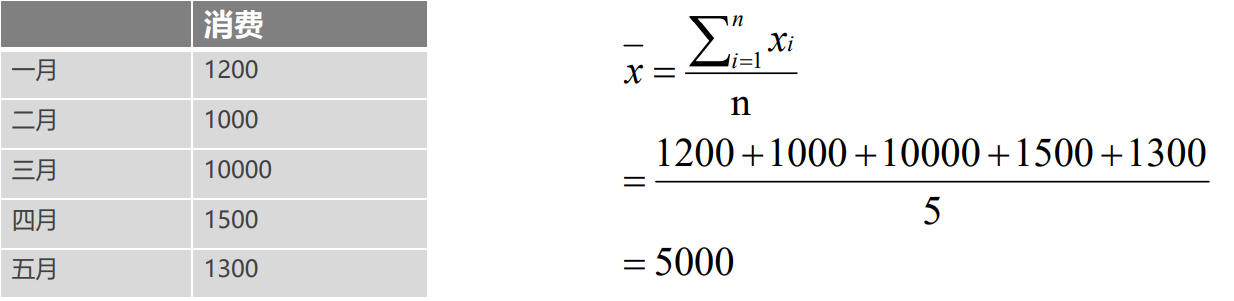
每个月的数据都是在1000左右,但是其中一个月的数值为10000,影响到整体的数据。
练习:计算一下平均消费。
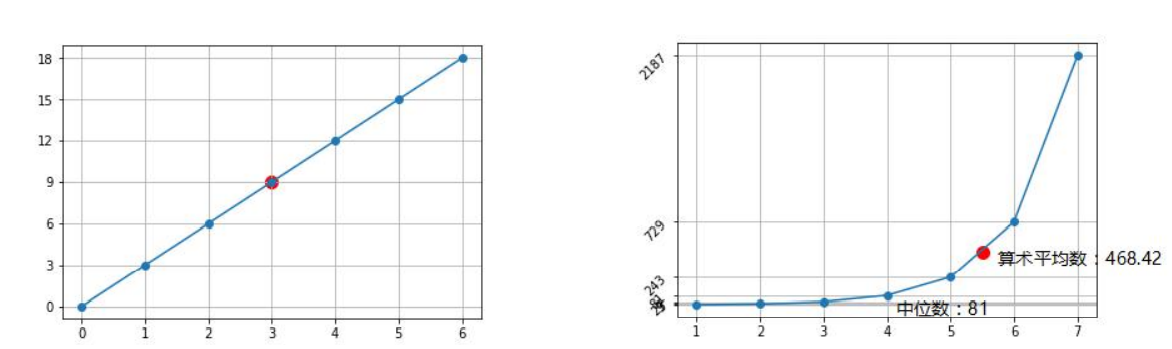
注意:算术平均数不适用于乘数级或者指数级增长的数据。均值跟中位数相差比较大,那么离散值就非常大,会偏差很多。
几何平均数
n个变量值乘积的n次方根
表示的符号: G G G
几何平均数(根据未分组数据计算的): G = x 1 x 2 . . . x n n G =sqrt[n]{x_1x_2…x_n} G=nx1/span>x2/span>…x来源:hwwaizs
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!