本文基于马樱博士《基于机器学习的软件缺陷预测技术研究》归纳总结而成,不具备论文作用,仅为学校交流
中文摘要
自过去几十年来,软件规模不断扩大,计算机程序设计变得更加复杂,软件规模显著增长,不同大小复杂度的软件被广泛应用于各个领域,电信、商业、国防、交通等各个行业都脱离不开软件的驱动,数据驱动未来,软件定义世界!然而这些行业的正常运行必须依赖软件的正常运行,一个细小的软件故障,都会为企业或者使用者带来不小的麻烦甚至经济损失,这些故障如果发生在国防软件中,更将产生难以估量的损失。但正是这些软件的存在,我们的生活才能顺利进行。但由于我们对这些软件或系统的以来,通常不知道何时,软件运行将会产生错。所以,与现实中其他可见的工程项目相比,软件质量的可靠性工程进度缓慢,也正因如此,这种缓慢的进步,阻碍了软件工程实践研究的发展;且软件的好坏并没有较为成熟和严格的标准,大多为主管喜好决策。因此对于软件缺陷的研究显得更为困难和重要。
英文摘要
Since the past few decades, the scale of software has continued to expand, computer programming has become more complex, and the scale of software has grown significantly. Software of different sizes and complexity has been widely used in various fields. Various industries such as telecommunications, commerce, national defense, and transportation have been separated from different industries. Driven by software, data drives the future, and software defines the world! However, the normal operation of these industries must rely on the normal operation of the software. A small software failure will cause a lot of trouble or even economic losses for the enterprise or user. If these failures occur in the national defense software, it will cause incalculable damage. loss. But it is the existence of these softwares that our lives can proceed smoothly. But because of our experience with these software or systems, we usually don’t know when the software will run incorrectly. Therefore, compared with other visible engineering projects in reality, the progress of software quality reliability engineering is slow, and because of this, this slow progress hinders the development of software engineering practice research; and the quality of software is not relatively good. Mature and strict standards, mostly for supervisors’ preferences. Therefore, the research on software defects is more difficult and important.
关键词
软件缺陷预测、机器学习、监督学习、半监督学习
- 引言
1.1软件可靠性面临挑战
自过去几十年来,软件规模不断扩大,计算机程序设计变得更加复杂,软件规模显著增长,不同大小复杂度的软件被广泛应用于各个领域,电信、商业、国防、交通等各个行业都脱离不开软件的驱动,数据驱动未来,软件定义世界!然而这些行业的正常运行必须依赖软件的正常运行,一个细小的软件故障,都会为企业或者使用者带来不小的麻烦甚至经济损失,这些故障如果发生在国防软件中,更将产生难以估量的损失。但正是这些软件的存在,我们的生活才能顺利进行。但由于我们对这些软件或系统的以来,通常不知道何时,软件运行将会产生错。所以,与现实中其他可见的工程项目相比,软件质量的可靠性工程进度缓慢,也正因如此,这种缓慢的进步,阻碍了软件工程实践研究的发展;且软件的好坏并没有较为成熟和严格的标准,大多为主管喜好决策。因此对于软件缺陷的研究显得更为困难和重要。
但早在2000年左右,由美国国家科学基金会成立的经验软件工程中心根据多为专家讨论的结果表明,由于软件缺陷对软件项目成败带来的影响和检测的相关问题,同时也提出了软件缺陷预测的研究目标和方向。他们也为该领域的研究贡献了大量样本数据,为软件缺陷预测研究的开展提供了条件。
软件缺陷预测方法的实际应用对软件的生产过程有很大的用处,例如,通过软件缺陷预测,可能获得一个更加高度可靠的软件系统;通过对容易产生错误的模块的关注,提高软件测试过程中的准确率和速度;通过使用面向对象的方法来使得设计更加合理,确定能重构的模块;基于结果分配资源。从而使得项目整体质量得以提高。
1.2软件缺陷预测技术研究内容及意义
软件缺陷预测对于软件质量保证而言是一个重要的活动,能够使用它来对有缺陷的软件模块进行风险预警。目前常用的技术有逻辑回归分析,判别分析和人工神经网络等各种方法。
1.2.1 软件缺陷预测的概念
软件缺陷可从两个方面进行定义,基于产品内部而言,软件缺陷指在系统开发时或维护的过程中存在的各种问题;基于产品外部而言,软件缺陷是指系统没有达到客户需求的某种功能的失效。
导致软件缺陷的原因有很多,例如:
-
-
- 由于设计问题导致软件功能与需求不一致使得,软件产生外部缺陷。
- 由于系统结构复杂,导致在软件测试的过程中不饿能测出所用函数或者对象类之间的相互作用。
- 程序之间协调不一致。
- 逻辑或者数据范围出问题等
-
根据机器学习的表示方法,软件缺陷预测模型可以表示为:
设包含n个样本数据集为Dn={(x1,y1),……,(xn,yn)},其中xi∈Rd表示当前model i的属性,yi∈Y为第i个model的标记。这些集合单独包含了k个属性,可以表示为:xi=(a1,a2,……,an)其中ai表示如模块的代码行数等的属性。这些属性可以认为是判断软件是否具有缺陷的重要属性。Y是一个有限集合,表示为标记的类别数。一般情况下只有两种即为有缺陷和无缺陷两种结果。其函数模型f可以表示为f(Rs) →Y。
1.2.2软件缺陷预测研究的基本内容
软件缺陷研究预测模型将模块的耦合渡河复杂度等结构方面的属性作为指标,其目的是探索不同方面的缺陷问题,并解决,以提高预测性能。影响预测模型的主要因素可以为数据集、建立模型的方法,以及软件内在属性和关系建立的合理性等。
1.2.2软件缺陷预测的研究意义
软件质量模型能用来确定有缺陷的程序模块,通过相关技术,对相关软件模块质量进行有针对性的分析。从而能够进行资源分配的合理化。但由于基于机器学习的预测是基于历史数据集的因此受训练数据集的影响较大,且由于行业的不断发展和变化,建立准确的预测模型是十分重要的研究内容。
- 软件缺陷预测相关技术
从缺陷预测模型使用的技术来看,经历了单变量统计分析法,多变量统计分析,统计分析联合专家分析,机器学习,以及机器学习联合统计分析的发展过程。
2.1软件缺陷预测的模型及相关算法
用于软件缺陷预测的模型主要有。基于监督学习的预测模型,基于半监督的预测模型,基于无监督的预测模型,基于回归方法的预测模型,基于属性约束的预测模型。
2.1.1 基于监督学习的缺陷预测算法
设有一样本空间为X,x是模块的若干属性组成的向量,x=(a1,a2,a3…..an)其中n为属性个数,ai为属性值,在以软件缺陷为模型的监督学习中,设结果为Y={0,1},0为软件无缺陷,1为软件有缺陷。基于监督的预测模型就是要学习下列目标函数C:X→Y


2.1.2 基于无监督学习的软件缺陷预测模型及相关算法
在日常生活中,很多软件模块都并非标记模块,尤其是面对多样化的工业领域,软件日新月异,很难判断一个软件是否为有缺陷的软件模块,因此很难对这部分数据进行标记。这时默认所有有缺陷的软件模型的某些属性具有类似的特征,所有没有却显得软件模块也拥有类似属性,通过聚类算法,对拥有这些属性的样本进行标记和区分预测。
常见的聚类方法主要包括K-means,X-menas,Fuzzy C-means等。
其中K-means算法可被描述为:
先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是以下任何一个:
1)没有(或最小数目)对象被重新分配给不同的聚类。
2)没有(或最小数目)聚类中心再发生变化。
3)误差平方和局部最小。
2.1.3 基于半监督学习的软件缺陷预测模型及相关算法
通过半监督方法简历软件缺陷预测模型的算法有期望最大化算法(EM)建立预测模型,该方法主要分为两步,有E-Step和M-Step,在E-step中,通过统计参数来估计缺失值。此算法把模块标记看作是缺失值,Y={Yobs,Ymiss},其中Yobs = ( yobs,1, yobs,2 ,……, yobs,n )为n个样本的变量集,其中K个变量服从正态分布,均值参数可设为m = (m1, m2 ,……, mk ),协方差矩阵为s jk,由此进行似然估计为:

其中,E-step 的计算式为:
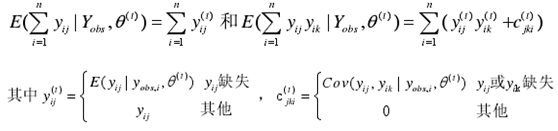
M-step估计两参数式为
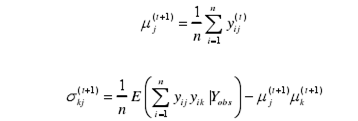
此为多个分类器集成的方法,设H = {h1, h2 ,…, hc},首先用带标记数据进行初始化,再通过投票原则,更新数据集,用新数据集建立新的分类器,最终集成方法为
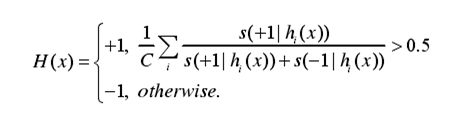
2.2基于主动学习的软件缺陷预测
2.2.1研究背景
在上文中提到,软件缺陷样本的有些数据集是没有标记的,那么当数据集中没有标记样本时,如何进行高效的模块标记问题呢/p>
这里就得用到上文所说的聚类方法。最先进行聚类研究的是由zhong提出的。他们应用K-means聚类算法和Nearal-gas算法将软件分为几个聚类,但是需要专家进行分类,显然这种方法依赖人力较多,效率较低
在后来的发展中,Seliya和Khoshgoftaar提出一种基于约束的半监督聚类方法,该方法利用初始具有标记的模块来进行聚类,然后由专家进行分析。在这个阶段中,初始标记数据是十分重要的,甚至还会大幅度影响实验结果。因此仍然具有较为严重的缺陷
Catral团队提出了基于K-means聚类和指标阈值的方法,使用阈值来减少人力的小号,然而对于聚类数k的值究竟取何值仍然是不明确的,这个因素也会对实验结果产生大幅度影响。最终试验结果表明,使用聚类方法和阈值的无监督软件缺陷预测可以使整个过程自动化,产生有效的预测结果。
而中国马樱博士对该问题提出了一种解决办法即为两阶段的主动学习算法,此算法在没有任何代表及的数据的情况下,能够有效减少人力代价,通过此算法建立的模型也具有较高的预测性能。
2.2.2两阶段主动学习算法
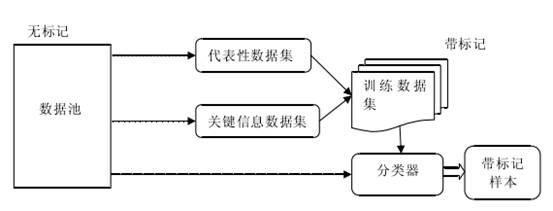
在上文提到的软件缺陷预测模型中,L = {(x1, y1),…..,(xl , yl )} ì X ′Y 代表了已经有标记的数据集, 其样本数目为l ,U = {xl +1,……., xl +u} ì X 表示未标记样本数据集,其样本数目为u . 在软件缺陷预测中, Y ì (+1, -1) ,有缺陷模块被标记为“ +1”,无缺陷的模块都标记为“ -1”。在之前的方法中,初始阶段的数据都是有标记的,而在此算法中,通过假设l=0的方式让初始阶段的数据不具有标记。
因此在这个阶段不能直接使用主动学习的方法,因为无法在没有标记的数据集上进行分类,为了得到初始标记数据,这里将这类数据命名为代表性数据,通过聚类技术再通过基于SVM的主动学习的算法,获得数据集中的关键数据,将其称为关键信息。由于代表性数据集和关键信息数据的数量都是有限的,因此大幅降低了标记代价。
2.2.3获取代表性数据集
将数据集D表示为Y R (D),设子集和{D1, D2 , …, Dn}其中D1∪D2∪, …, ∪ Dn=D,且任意两个子集之交必为空集,即Di∩Dj=nbsp;(i, j = 1, 2, …, n;i 1 j )。子集Di的中心表示为Ri,则
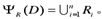
为了找出代表性数据集Y R (D),使用K-means方法,将k设为固定值,设k个数据点即为k个聚类中心。聚类质量公式为
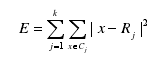
Cj为第j个聚类,x指数据集合岩本,通过K-means便能找到代表数据集。但是可能存在样本“溢出”问题即样本不包含在Y R (D)中。因此对这种算法进行改进得到级联聚类法,该算法伪代码为:

该算法基于K-means聚类算法通过反复进行聚类,寻找聚类中心,直到找到所有不同类别的中心点。由于在软件缺陷预测研究中只有两类,所以从理论上进行计算得到在最坏的条件下,需要调用的时间为「logn+1」「或log(n+1)」,n表示样本的数量。
2.2.4获取关键信息数据
设Y I (D)为数据集D的关键性数据集。该集合表示分类边界面附近的子集。
这部分数据由于数量少容易被错分,但又包含了建立分类器的重要信息,为了能够正确获得这部分数据集,可利用支持向量机技术。SVM是监督分类器,能够很大限度的减少错误与其上线。能够找到问题的最大超平面。
两阶段主动学习法需要获得关键性数据集,需要考虑两个类的分类问题,即:y∈{1,-1}的线性SVM函数如下:

在标准化数据集后,样本满足g(x)>=1,点x到超平面距离为| w × x + b | / || w ||。支持向量是最接近超平面H的店,满足|g(x)|=1。因此,两类中最接近样本的距离等于2/||w||。所以,寻找最优超平面可描述为:
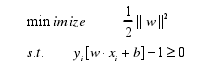
在使用拉格朗日乘子方法后,优化问题等价于
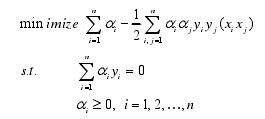
在本算法中建立的SVM分类器伪代码如下

- 总结感悟
3.1本文总结
软件预测是软件行业中十分重要的内容,本文只是展示了基于机器学习的软件缺陷预测的部分内容,实乃冰山一角,软件的发展离不开软件工程师与科研人员的努力,模型的建立更离不开无数科研人才的智慧。本文立足于机器学习,主要讲述了机器学习中基于主动学习的软件预测缺陷,重点描述了马樱博士的科研成果——两阶段主动学习法,该方法对之前传统的软件预测技术进行了改进和研发,提高了软件缺陷预测的效率。
3.2行业未来工作
(1)研究软件模块的内部结构表示方法
针对无本地训练数据的情况,提高软件缺陷预测模型的性能的方法以及在跨领域项目上的预测性能等。
(2)研究半监督学习方法在软件缺陷预测领域的应用
半监督学习犹如直推式半监督方法,基于图理论的半监督方法等。今后的研究可以比较各种半监督方法的预测性能
(3)软件噪音处理和数据偏斜研究
在软件进行预测或者进行机器学习的时候,由于一些不关键数据等各种原因往往会产生噪音,导致实验数据偏斜,我们仍然需要攻克这一难关,使得噪音对预测的影响接近于无
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树首页概览208470 人正在系统学习中
来源:风褛襟花
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!