5月13日-15日,由全球最大中文IT社区CSDN主办的“2016中国云计算技术大会”(Cloud Computing Technology Conference 2016,简称CCTC 2016)在北京新云南皇冠假日酒店隆重举行,这也是本年度中国云计算技术领域规模最大、海内外云计算技术领袖齐聚、专业价值最高的一场云计算技术顶级盛宴。本次大会以“技术与应用、趋势与实践”为主题,聚焦最纯粹的技术干货分享,和最接地气的深度行业案例实践,汇聚国内外顶尖技术专家,共论最新的云计算技术实践与发展趋势。
大会第三天,在中国Spark技术峰会下午场,来自聚效广告、 新浪微博、英特尔亚太研发有限公司、Databricks、AdMaster等企业的七位嘉宾共同为Spark技术爱好者带来了一场关于Spark 2.0的技术盛宴。


XGBoost和MXNet已经有Spark版本,有一些API可以使用,性能测试表现不错,Failover的工作也正在进行。
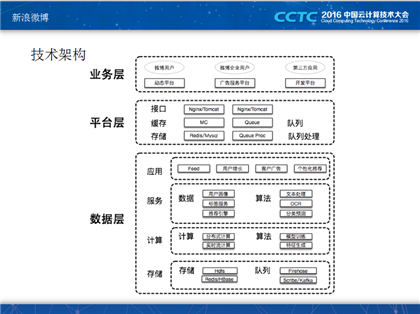
紧接着,他向大家介绍了feed场景,新浪微博的用户在登录微博之后,一般会发布一些微博,粉丝会在首页看到一些微博的信息我们称之为feed,feed的基本的流程是用户发微博之后,进行物料的存储,然后无聊帅选和聚合,经过排序最后进行feed 的输出。这其中存在一些基本的问题:物料的问题和排序的问题,物料的问题方面,通过引入了关系物料和非关系物料,然后引入个性化的内容来解决物料的问题,同时引入一些用户的质量来解决物料质量的问题;在排序的方面引入了样本、模型、特征来解决排序优化的问题。
接下来,他介绍了Feed中Spark的应用,算法方面,通过使用Spark MLlib进行建立内容质量、排序防抓站模型;特征方面,通过Spark Streaming抽取实时特征。

他重点介绍了ELK监控Hadoop集群负载性能的实现原理以及ELK和Ambari深度集成。ELK利用Logstash和logpreparer来收集Hadoop集群的负载相关日志,其数据来自YARN API、Spark作业日志等等,收集方式为:logpreparer负责准备日志文件,HDFS,REST API,logstash解析日志,存入ES;利用Elasticsearch来存储收集到的数据,通过设立文件TTL,定期清理过期数据;利用Kibana来分析数据和展示分析结果。演讲中,他建议大家利用Ambari来安装,部署和管理ELK:
- Ambari管理员可以通过Ambari Server在浏览器上实现;
- Ambari管理员可以通过Ambari Server的Service和Component管理功能对ELK的组件进行启动和停止操作;
- Ambari管理员可以通过Ambari Server动态的为Elasticsearch Component添加节点,从而扩展Elasticsearch的规模。

开场之初,他提到了如何利用 Spark SQL进行加速 SQL查询这个问题。除了内存管理数据、高速缓存感知计算、矢量化等操作之外,他向大家介绍了Spinach。Spinach 的项目是为了覆盖掉API和cache Layer这两层去解决问题,第一层不需要有额外的第三方的服务存在;第二点就是说我可以提供一个更细力度的缓存;第三所有的数据,数据是缓存在Off-heap Memory中,我们的Spinach是和API是跑在一个进程里面的,这些缓存是放在同一个力度上来做缓存的,这个是放在JAVA最底面一层,好处就是不会对GC带来影响,最后可以支持用户自定义的索引。
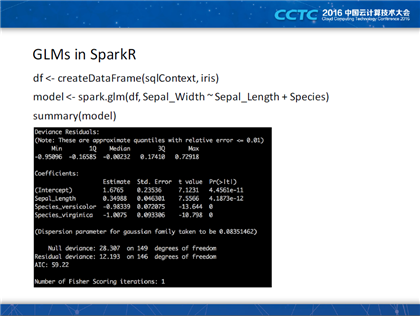
开场之初,他介绍了线性回归、逻辑回归等机器学习中的基础概念,并给出了自己的见解。他谈到线性回归和逻辑回归都是通用线性模型的特例。紧接着,他有详细解释了GLMs在SparkR和Spark MLlib中的使用差别,并并对加载训练数据、拟合模型等操作的代码进行了详细分析。
演讲中,他提到Spark本身作为一个一体化的大数据处理引擎,在一定的程度上已经比较好的支持这种多范式混合的流水线,可以在一个应用之内同时的去完成批处理、流处理、机器学习等等,但是其中还存在一些痛点:第一点,Spark Streaming是基于RDD和API来搭建的,但这是另外一套独立的API。无论是从计算的模型还是从API上两者都不是统一的,因此在用户复用代码的时只能复用函数的逻辑。第二天就是计算的函数以及RDD所存储的内容都是不透明的,很难进行针对性的优化。

在Spark 实时监控案例分析中,他介绍到通过AdMaster通过自己开发的 flume source、flume 消息加密算法、定义的 flume to kafka 算法、并发入库算法,可支持多种数据类型的收集,并且使得数据足够均匀,安全高效地支撑13w+/s 的吞吐量,足以应对实时监控的要求。在跨屏分析案例中,谈到如何通过多个屏目识别同一个用户的问题,他表示如果公司有账户的体系,比如说阿里、腾讯和百度,可以将账户体系打通;如果没有账户体系的话,就要另谋出路,比如可以采用收集Ip/imei/idfa/其它加密唯一信息 再加上机器学习加以实现。

演讲最后,他向在场的听众分享了数据流分析案例中的亮点,一是数据采集服务中,webservice与kafka、storm配合使用;二是算法服务,基于NLP服务和机器学习实现情感分析、分词等操作。
更多精彩内容,请关注直播专题2016中国云计算技术大会(CCTC),新浪微博@CSDN云计算,订阅CSDN云计算官方微信公众号。
相关资源:连续梁的弯矩计算软件V1.0绿色版_连续梁-其它代码类资源-CSDN文库
来源:仲浩
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!