在软件开发领域,任务指派和数据关联是一种常见业务需求,比如买卖订单的匹配,共享出行的人车匹配,及自动驾驶领域中目标追踪。
这都牵扯到一种技术,那就是数据关联,而匈牙利算法就是解决此类问题最典型的算法,也是今天本文的主题。
我们感性的认为目标之间的匹配好像一目了然的样子,但是计算机可不这样认为。计算机是理性的,如果要处理问题,一般我们会用数据结构来表示数据,栈、队列、树、图都很常用。
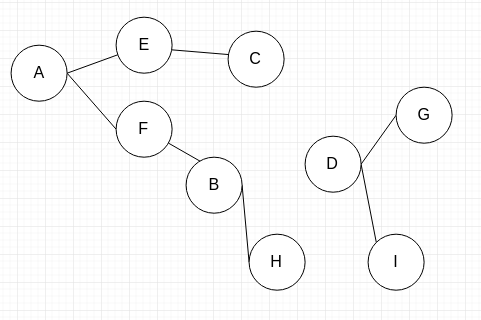

不过,这是一种特殊的图,叫做二分图。
二分图图最大的特点就是,图中的顶点可以分别划分到两个 Set 当中,每个 Set 中的顶点,相互之间没有边连接。
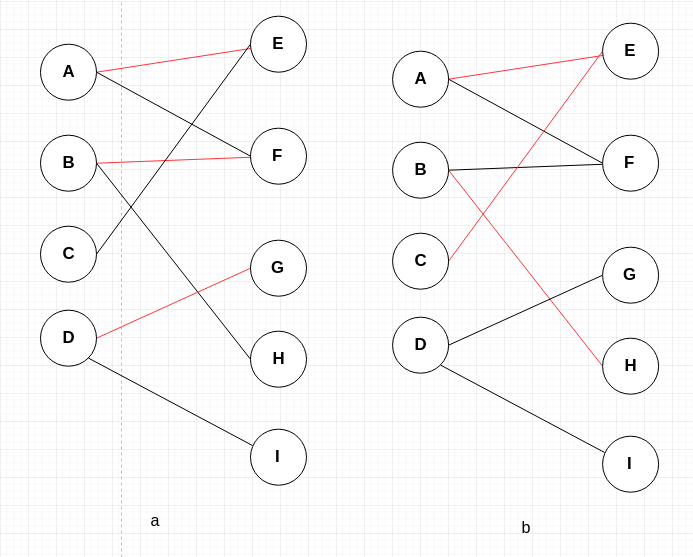
上图 a 中的红线可以是一个集合,而 b 不是。
最大匹配
按照定义,我们很容易知道,一个图中可以有许多匹配,而包含边数最多的那个匹配,我们称之为最大匹配。
完美匹配
如果一个匹配,它包含了图中所有的顶点,那么它就是完美匹配。
完备匹配
完备匹配的条件没有完美匹配那么严苛,它要求一个匹配中包含二分图中某个集合的全部顶点。比如,X 集合中的顶点都有匹配边。
匈牙利算法就是要找出一个图的最大匹配。
算法思想
其实匈牙利算法如果要感性理解起来是很容易的,核心就在于
冲突和协调
我们看看下图:
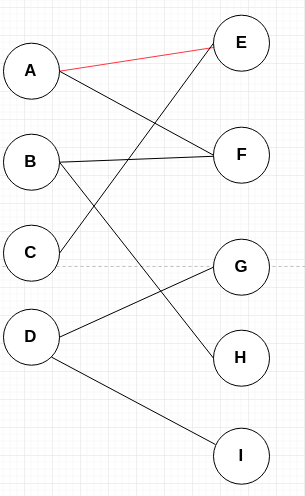
从顶点 A 开始,E 点可以匹配,那么就直接匹配。并将边 AE 加入到匹配中。
第 2 步
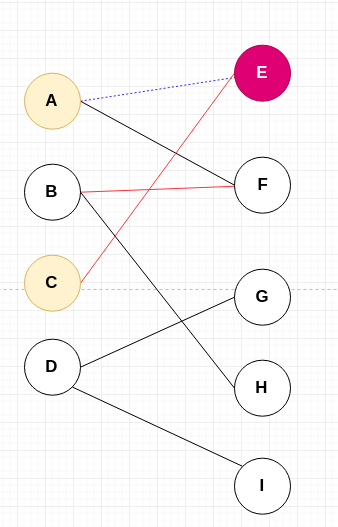
当 C 点开始寻求匹配时,可以发现 CE 和 AE 起冲突了。
前面讲到了冲突和协调两个关键词。
匈牙利算法是让CE 先匹配, AE 取消匹配,然后让 A 尝试重新匹配。
第 4 步
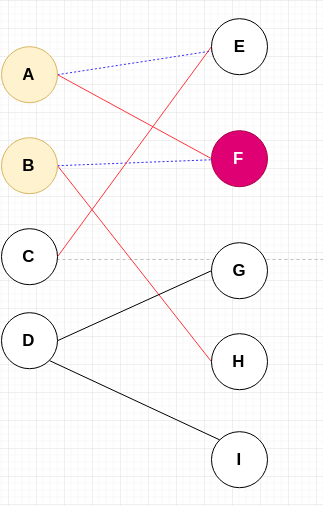
B 点寻求匹配的过程,没有再遇到冲突,所以,BH 直接匹配。
需要注意的是,这条路径是从顶点 C 出发的,发生了 2 次冲突,协调了两次,最终协调成功。
如果协调不成功的话,CE 这条路就不成功,它需要走另外的边,但是上图中 C 只和 E 有可能匹配,所以,如果协调不成功,C 将找不到匹配。
第 6 步

代码很简单,详情见注释,打印结果如下:
到这里,就可以了,匈牙利算法的思想和代码编写我们都掌握了。
但是,文章最后,我还是想用更学术的方式去描述和编写这个算法。
用学术的目的是让我们显得更科班,不能总是野路子凭灵感去弄是吧/p>
学术化的目的是为了让我们的思维更严谨,夯实我们的技术基础,这样遇到新的问题时,我们能够泛化解决它。
交替路与增广路
我们现在站在结果处回溯。
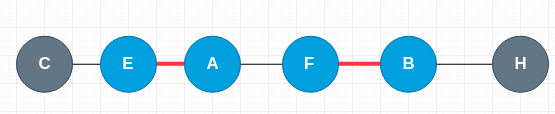
上面求得匈牙利的匹配结果如下图:

我们可以观察到,匈牙利算法要求得的匹配结果,可以用上图形式表示。
红实线表示两顶点匹配,灰色的虚线表示未匹配。
上面的路径中匹配的边和未匹配的边交替出现。
所以,我们的目标是去构建这样一条路径。
这涉及到两个概念:交替路和增广路。
什么是交替路/h4>
从未匹配的顶点出发,依次经过未匹配的边,匹配的边,未匹配的边,这样的路径就称为交替路。
重点是未匹配的点和未匹配的边开始
什么是增广路/h4>
从未匹配的顶点出发,按照交替路的标准寻找顶点,如果途经了另外一个未匹配的点,那么这条路径就是增广路。
增广路有一些重要的特征:
- 增广路中为匹配的边的数量要比匹配的边的数量多 1 条。
- 增广路取反(匹配的边变成未匹配,未匹配的边变成匹配)后,匹配的边的数量会加 1,从而达到匹配增广的目的。
而匈牙利算法其实就是就可以看做是一个不断寻找增广路的过程,直到找不到更多的增广路
。
下面图例说明:
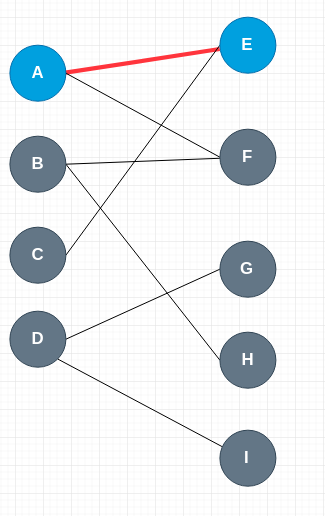
首先,从顶点 A 开始,如果要寻求增广路,它应该先走未匹配的边,可以选择 AE,因为 E 点也未匹配,所以 A –> E 符合增广路的定义,它就是一条增广路。
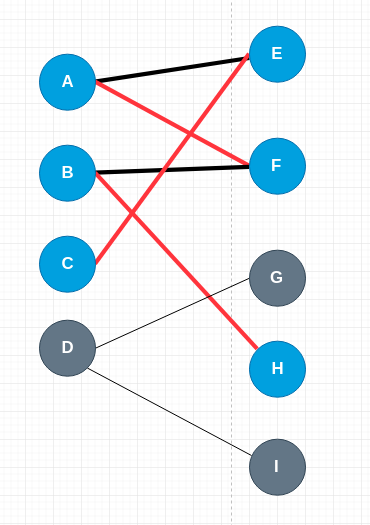
再从 C 点寻找增广路,它走未匹配的边,CE,然后走 EA,再走 AF,再走 FB,最后 BH,因为 H 是未匹配的点,所以 C–>E–>A–>F–>B–>H 就是一条增广路,如上图。
我们再对 D 顶点寻找增广路。
打印结果如下:
也许有同学会问,怎么没有看见对增广路取反/p>
其实,match_list 数组就保存了匹配关系,当改变其中的值顶点的匹配关系就变了,并不需要用一个真正的链表来表示增广路。
文章知识点与官方知识档案匹配,可进一步学习相关知识
来源:frank909
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!