一、什么是大数据
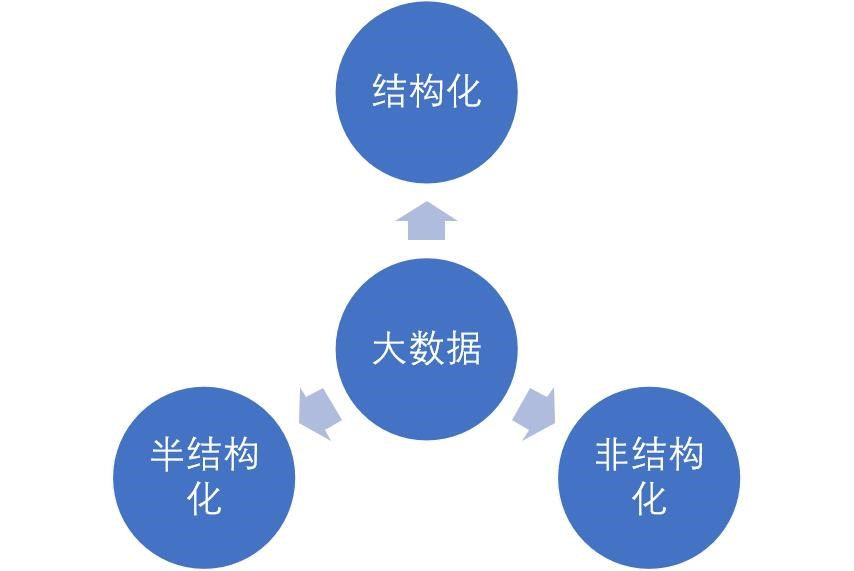
大数据是指利用常用软件工具捕获、管理和处理数据所耗时间超过可容忍时间的数据集。
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的应用:
阿里云存储模式:OSS,RDS
计算模式:ODPS,ADS(数据仓库会讲到)
数据仓库:星型模型,雪花模型。。。
银行,证券,基金,信托,期货,蚂蚁基金:写一些常用的sql:持票仓,交易表,损益表……用mapreduce算出我们常用的业务逻辑
说明个人数据:
手机号码,出生日期,家庭情况,上网习惯
三个大数据应用场景
游戏动画
视频软件
出行习惯

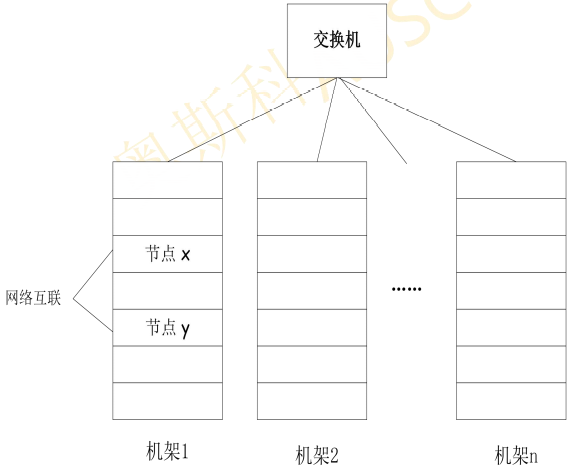
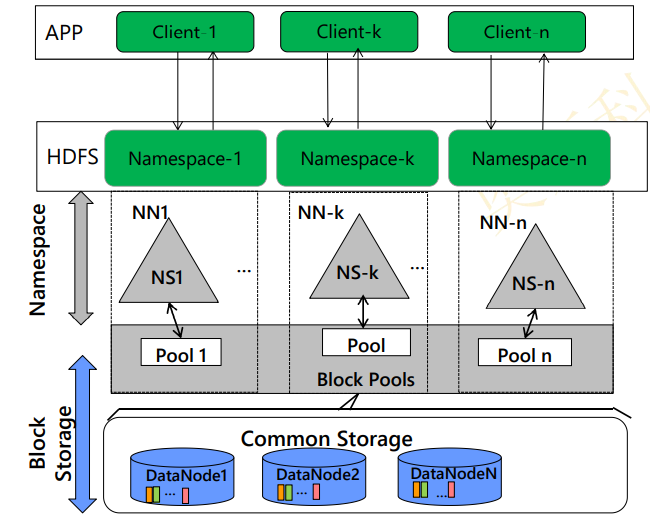
二、HDFS分布式文件系统和ZooKeeper、
1、字典与文件系统
3.2、基本架构
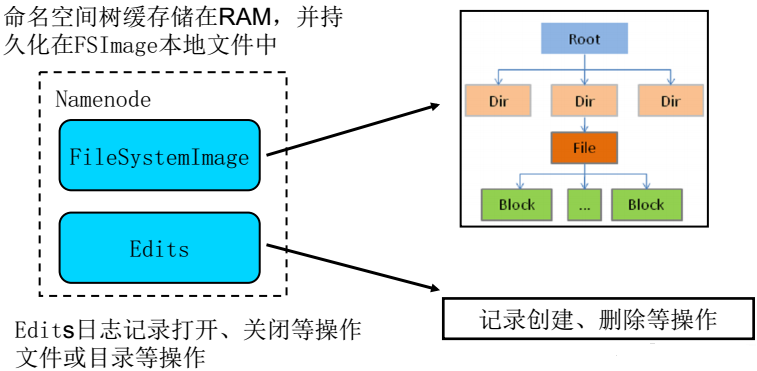
1、将文件的元数据保存在一个文件目录树中
2、在磁盘上保存为:fsimage 和 edits
- simage:镜像文件,记录文件系统目录树,是全量记录。
- editlog: 编辑日志,记录所有的读写操作,是增量记录。
3、保存datanode的数据信息的文件,在系统启动的时候读入内存。
Namenode存放文件系统树及所有文件、目录的元数据。元数据持久化为2种形式:
- namespcae image-
- edit log
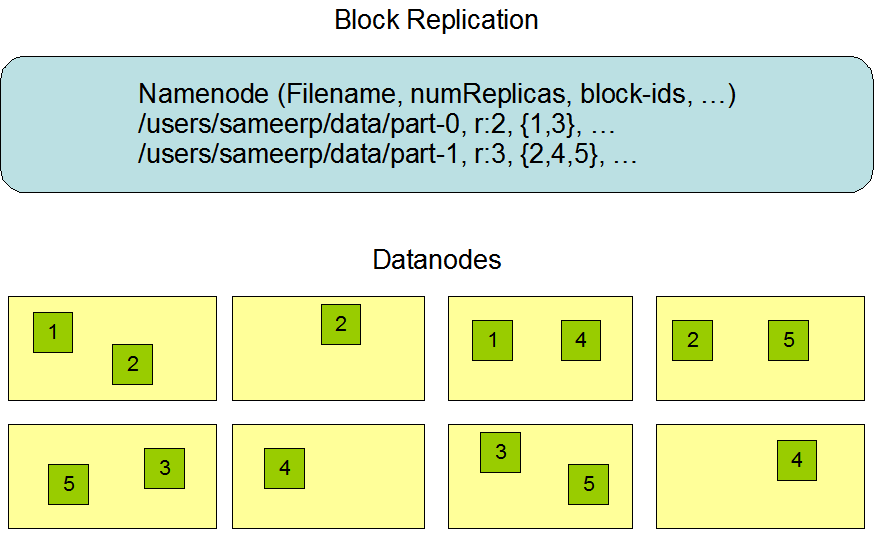
但是持久化数据中不包括Block所在的节点列表,及文件的Block分布在集群中的哪些节点上,这些信息是在系统重启的时候重新构建(通过Datanode汇报的Block信息)。
在HDFS中,Namenode可能成为集群的单点故障,Namenode不可用时,整个文件系统是不可用的。HDFS针对单点故障提供了2种解决机制:
三、HDFS体系结架概述

元数据持久化
HDFS数据完整性保障
HDFS主要目的是保证存储数据完整性,对于各组件的失效,做了可靠性处理。 l 重建失效数据盘的副本数据
DataNode向NameNode周期上报失败时,NameNode发起副本重建动作以恢复丢失副本。 l
集群数据均衡
HDFS架构设计了数据均衡机制,此机制保证数据在各个DataNode上分布是平均的。
元数据可靠性保证 p 采用日志机制操作元数据,同时元数据存放在主备NameNode上。 p 快照机制实现了文件系统常见的快照机制,保证数据误操作时,能及时恢复。 l 安全模式 p HDFS提供独有安全模式机制,在数据节点故障,硬盘故障时,能防止故障扩散。
HDFS架构其他关键设计要点说明
空间回收机制: 支持回收站机制,以及副本数的动态设置机制。
数据组织: 数据存储以数据块为单位,存储在操作系统的HDFS文件系统上。
访问方式: 提供JAVA API,HTTP方式,SHELL方式访问HDFS数据。
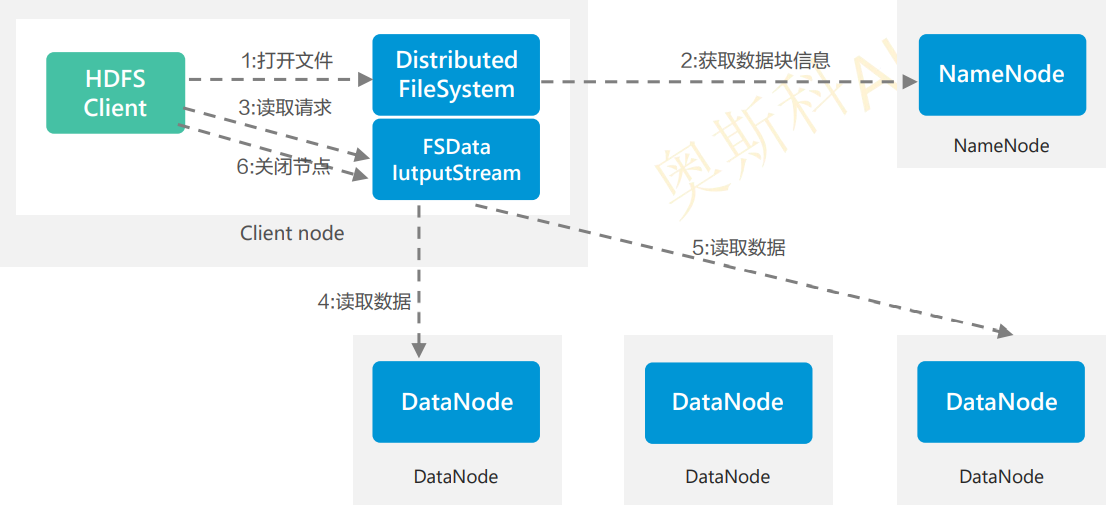
HDFS数据写入流程
Zookeeper
Zookeeper概述
ZooKeeper 分布式服务框架主要是用来解决分布式应用中经常遇到的一些数据管理问题, 提供分布式、高可用性的协调服务能力。
安全模式下ZooKeeper依赖于Kerberos和LdapServer进行安全认证,非安全模式则不依赖 于Kerberos与LdapServer。ZooKeeper作为底层组件广泛被上层组件使用并依赖,如 Kafka,HDFS,HBase,Storm等。
什么是Zookeeper
- 是Google的Chubby的一个开源实现版
- ZooKeeper
- 一个分布式的,开源的,用于分布式应用程序的协调服务(service)
- 主从架构
- Zookeeper 作为一个分布式的服务框架
- 主要用来解决分布式集群中应用系统的一致性问题
- 它能提供基于类似于文件系统的目录节点树方式的数据存储,
- Zookeeper 作用主要是用来维护和监控存储的数据的状态变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理
分布式通信有几种方式
1、直接通过网络连接的方式进行通信;
2、通过共享存储的方式,来进行通信或数据的传输
ZooKeeper使用第二种方式,提供分布式协调服务
来源:随波逐流非本意
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!