
实时美声:如何炼成好声音/p>
在日常的生活中我们经常听到人们说“这个男人的声音好有磁性”或者“这个女生的声音好甜美”这样的对好听的声音的赞美。但如果不是“天生丽质“或者经过专业的训练的声优或者播音员,很难把平时说话的声音改变为这些”好听“的感觉。而在平时的聊天、娱乐中,大家又想有个好声音来让大家更愿意甚至乐于听你说话或者唱歌。为了让用户的声音更好听,同时又不会改变原有的声音辨识度,声网Agora 首创了实时美声功能。在原有低延时、高音质的基础上,我们在该功能背后融合了更多声音美化的技术。
首先,为了捕捉到到“好的声音”,我们组建了一个好声音猎手团队,通过对声优、播音演员、歌唱演员、主播等大量好声音数据的特征分析,结合大众对好声音的审美取向和应用场景,对好声音进行了系统的分析。从语音声波产生的声学原理、空间声波传输的空间混响模型;心理学感知模型;韵律、人群差异的语言学等多个角度对什么是好声音、好声音的数学描述特征指标,进行了多个维度的分析并总结出不同种类好声音的一般规律。例如男性的磁性的声音一般在低频和高频能量较高、中频能量较低,温柔的声音往往会具备节奏缓慢、pitch 变化小、咬字模糊等特性。
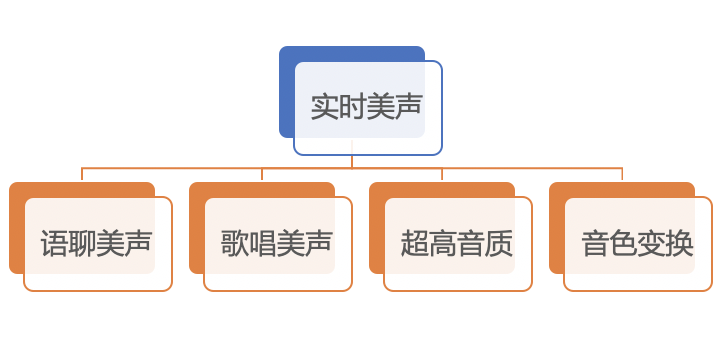
图2:美声分类
语聊美声:适用于语聊场景,实现对声音的美化,同时又不改变原声的辨识度。
歌唱美声:适用于歌唱场景,多维度地对歌声进行调整,使歌声更动听、更契合伴奏,同时又能保留歌手声音原有的特点。
超高音质:更清晰丰富的高音质效果,更加通用并且兼容各种场景,根据心理声学和掩蔽效应,调节声音频率分布,提升听觉体验。
音色变换:在语聊和歌唱场景下,让你的音色朝特定的方向改变。可根据不同的听众,选择不同的效果;或根据自己声音的特点,选择最适合自己的效果。
我们提供了在线试听的美声 Demo,大家可以在线体验到各种美声、音效https://www.agora.io/cn/audio-demo
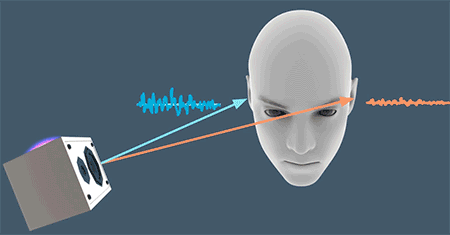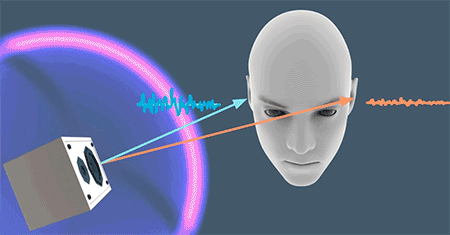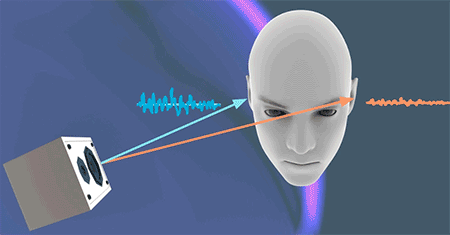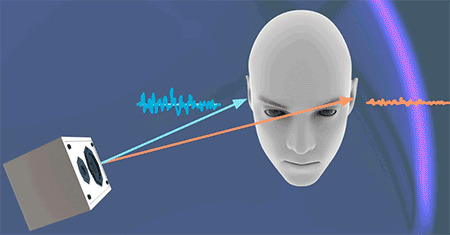
仅仅是通过双耳时差(ITD)还无法判断高频声源的位置,这是因为一些高频的声音会被由于物体遮挡而无法继续传递、扩散,比如人的头部。如上图的情况,左耳能听到的高频的声音就不如右耳“丰富”。这就是双耳水平差(Interaural level differences, ILD)。由于头部带来的声学屏障(acoustic shadow),会让左右耳听到的声音大小与频率产生差别,由此大脑会判断出声源方位。
另外,还有频谱效应(Spectral effects)。声音在到达后会因外耳结构而形成反射,从不同方向来的声音,反射效果也不同,大脑可以根据它来判断声源在垂直方向上的相对方位。
有了双耳时差和双耳水平差判断声源水平位置,然后利用耳廓的反射可以判断声源垂直的位置,大脑就可以判断声音在三维空间中的位置了。

图3:一些常见的 Ambisonics 话筒
原始的采集数据我们叫 A-format ,它是无法直接播放的,通过多通道转码成“多通道数据”(B-format),然后经过网络传输到远端,就可以通过耳机或者多声道的播放设备将其播放出来。目前声网的音频编解码传输就已支持 Ambisonics,同时我们对音频的高保真压缩,可把数据压缩在合理的带宽范围之内,又不会影响音质体验。
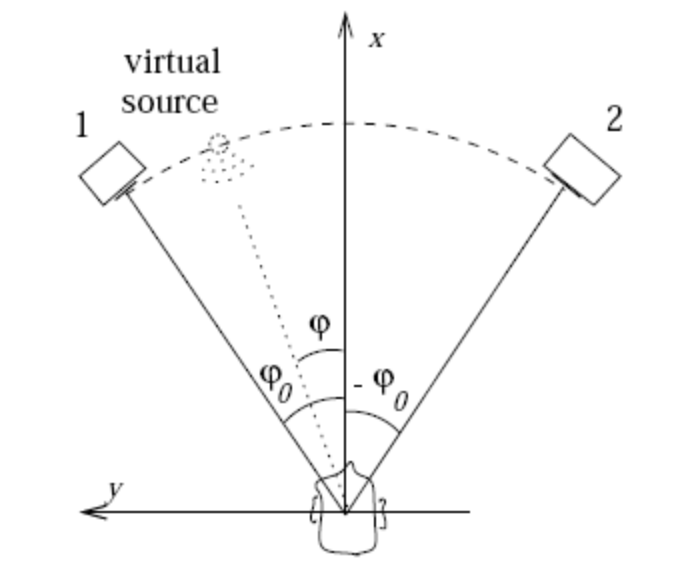
图5:Amplitude panning
Amplitude panning 没有考虑人耳形状带来遮蔽效果,也没有考虑声音传播的音色变化,所以实际使用时虽然可以判定出大致音源的方向和距离,但离真实听感差距比较大。为了达到更好的听感,声网的虚拟立体声采用了 HRTF(Head-related transfer function)技术,对音源到达双耳的传递函数进行建模 ,并结合真实采集的 HRIR(Head Related Impulse Responses)来准确的还原不同音源位置对实际听感的区别。使用 HRTF 技术的虚拟立体声更真实,对距离、角度的听力判断更准确。

相关阅读
详解低延时高音质:编解码篇
详解低延时高音质:回声消除与降噪篇
详解低延时高音质:丢包、抖动与 last mile 优化那些事儿

来源:声网
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!