拥抱人工智能,从机器学习开始
- 背景:
- 一、机器学习:
- 二、机器学习算法:
-
- 1. 线性回归:找到一条直线来预测目标值
- 2. 逻辑回归:找到一条直线来分类数据
- 3. K-近邻:用距离度量最相邻的分类标签
- 4. 朴素贝叶斯:选择后验概率最大的类为分类标签
- 5. 决策树:构造一棵熵值下降最快的分类树
- 6. 支持向量机(SVM):构造超平面,分类非线性数据
- 7. K-means:计算质心,聚类无标签数据
- 8. 关联分析:挖掘啤酒与尿布(频繁项集)的关联规则
- 9. PCA降维:减少数据维度,降低数据复杂度
- 10. 人工神经网络:逐层抽象,逼近任意函数
- 11. 深度学习:赋予人工智能以璀璨的未来
- 三、Anaconda:初学Python、
- 四、总结
背景:
自“阿尔法狗”(AlphaGo)完胜人类围棋顶尖高手后,有关人工智能(AI)的讨论就从未停歇。工业4.0方兴未艾,人工智能引领的工业5.0时代却已悄然苏醒。人工智能的火爆离不开互联网、云计算、大数据、芯片和软件等技术的发展,而深度学习的进步却是当今人工智能大爆炸的核心驱动。
作为一个跨学科产物,人工智能的内容浩如烟海,各种复杂的模型和算法更让人望而生畏。那么作为一个普通程序员,在已有语言技能的前提下,该如何拥抱变化,向人工智能靠拢何在自己的工作中应用人工智能习人工智能应该从哪里开始/p>
人工智能并非遥不可及,人人都可以做人工智能!人工智能是让机器像人一样思考,而机器学习则是人工智能的核心,是使计算机具有智能的根本途径。学习人工智能,首先要了解机器学习的相关算法。
本文我们将与大家一起探讨机器学习的相关算法,共同揭开人工智能的神秘面纱。
一、机器学习:
一种实现人工智能的方法
智能是现代生活中一个很常见的词,例如智能手机、智能家居产品、智能机器人等,但是不同的场合智能的含义也不一样。我们所说的“人工智能”(Artificial Intelligence, AI)则是指让机器像人一样思考,具备人类的智能。
从诞生至今,人工智能这个领域经历了一次又一次的繁荣与低谷,其发展上大体上可以分为“推理期”,“知识期”和“学习期”。推理期主要注重逻辑推理但是感知器过于简单;知识期虽然建立了各种各样的专家系统,但是自主学习能力和神经网络资源能力都不足。学习期机器能够自己学习知识,而直到1980年后,机器学习因其在很多领域的出色表现,才逐渐成为热门学科。近代,随着互联网、云计算、大数据的发展,以及GPU、芯片和软件技术的提升,深度学习开始兴起,拓展了人工智能的领域范围,也推动着社会从数字化向智能化的变革。
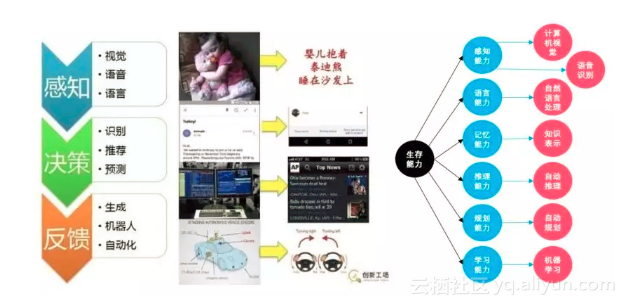

认识人工智能,还需要理清几个概念之间的关系:人工智能是一个大的概念,是让机器像人一样思考甚至超越人类;而机器学习是实现人工智能的一种方法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测;深度学习是机器学习的一种实现方式,通过模拟人神经网络的方式来训练网络;而统计学是机器学习和神经网络的一种基础知识。
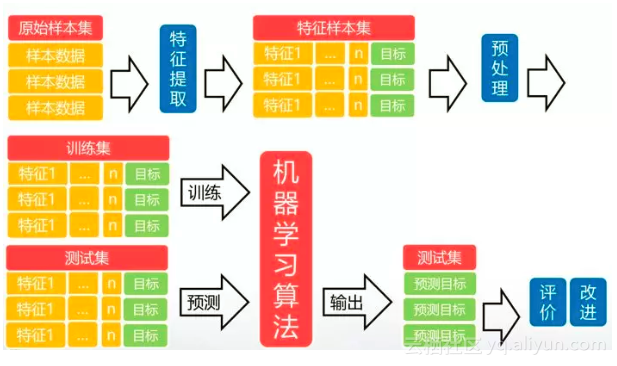
二、机器学习算法:
是使计算机具有智能的关键
算法是通过使用已知的输入和输出以某种方式“训练”以对特定输入进行响应。代表着用系统的方法描述解决问题的策略机制。人工智能的发展离不开机器学习算法的不断进步。
机器学习算法可以分为传统的机器学习算法和深度学习。传统机器学习算法主要包括以下五类:
回归:建立一个回归方程来预测目标值,用于连续型分布预测
分类:给定大量带标签的数据,计算出未知标签样本的标签取值
聚类:将不带标签的数据根据距离聚集成不同的簇,每一簇数据有共同的特征
关联分析:计算出数据之间的频繁项集合
降维:原高维空间中的数据点映射到低维度的空间中
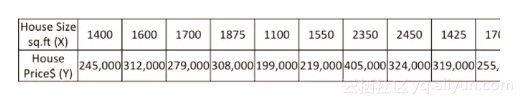
此类问题可以用回归算法来解决。回归是指确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,通过建立一个回归方程(函数)来估计特征值对应的目标变量的可能取值。最常见的是线性回归(Y= a X + b),即找到一条直线来预测目标值。回归的求解就是求解回归方程的回归系数(a,b)的过程,并且使误差最小。房价场景中,根据房屋面积和售价的关系,求出回归方程,则可以预测给定房屋面积时的售价。
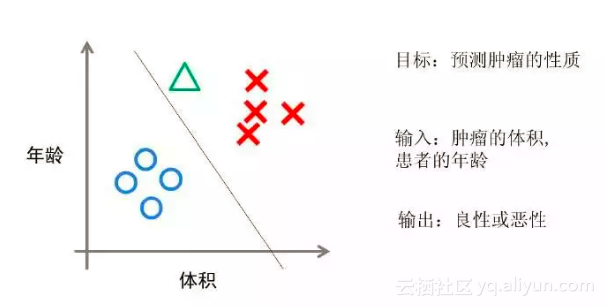
逻辑回归的应用也非常广泛,例如:
医学界:探索某个疾病的危险因素,根据危险因素预测疾病是否发生,与发生的概率。
金融界:预测贷款是否会违约,或放贷之前去估计贷款者未来是否会违约或违约的概率。
消费行业:预测某个消费者是否会购买某个商品,是否会购买会员卡,从而针对性得对购买概率大的用户发放广告,或代金券等等。
3. K-近邻:用距离度量最相邻的分类标签
一个简单的场景:已知一个电影中的打斗和接吻镜头数,判断它是属于爱情片还是动作片。当接吻镜头数较多时,根据经验我们判断它为爱情片。那么计算机如何进行判别呢/p>

进一步增加难度,当球没有明确的分界线,用一条直线已经无法将球分开,该怎么解决/p>
举个具体的例子,例如有一批人的年龄的数据,大致知道其中有一堆少年儿童,一堆青年人,一堆老年人。
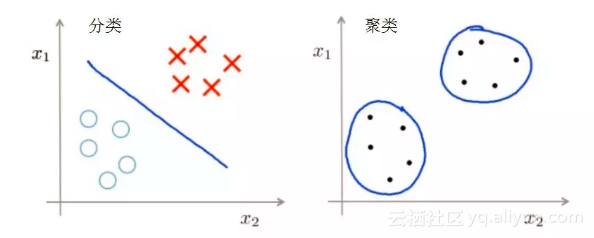
聚类就是自动发现这三堆数据,并把相似的数据聚合到同一堆中。如果要聚成3堆的话,那么输入就是一堆年龄数据,注意,此时的年龄数据并不带有类标号,也就是说只知道里面大致有三堆人,至于谁是哪一堆,现在是不知道的,而输出就是每个数据所属的类标号,聚类完成之后,就知道谁和谁是一堆了。
而分类就是,事先告诉你,少年儿童、青年人及老年人的年龄是什么样的,现在新来了一个年龄,输入它的年龄,输出她属于的分类。一般分类器是需要训练的,它才能识别新的数据。
K-Means算法是一种常见的聚类算法,其基本步骤为:
(1)随机生成k个初始点作为质心;
(2)将数据集中的数据按照距离质心的远近分到各个簇中;
(3)将各个簇中的数据求平均值,作为新的质心,重复上一步,直到所有的簇不再改变。
两个分类间隔越远,则聚类效果越好。
K-means算法的一个案例是:客户价值细分,精准投资。以航空公司为例,因为业务竞争激烈,企业营销焦点从产品中心转为客户中心;建立合理的客户价值评估模型,进行客户分类,进行精准营销,是解决问题的关键。
识别客户价值,通过五个指标:最近消费时间间隔R,消费频率F,飞行里程 M和折扣系数的平均值C,客户关系长度L(LRFMC模型)。采用K-Means算法对客户数据进行客户分群,聚成五类(需结合业务的理解与分析来确定客户的类别数量)绘制客户群特征雷达图。
客户价值分析:
重要保持客户:C、F、M较高,R低。应将资源优先投放到这类客户身上,进行差异化管理,提高客户的忠诚度和满意度。
重要发展客户:C较高,R、F、M较低。这类客户入会时长(L)短、当前价值低、发展潜力大,应促使客户增加在本公司和合作伙伴处的消费。
重要挽留客户:C、F 或 M 较高,R较高 或 L变小,客户价值变化的不确定性高。应掌握客户最新信息、维持与客户的互动。
一般和低价值客户:C、F、M、L低、R较高。这类客户可能在打折促销时才会选择消费。
K-means算法的一个比较有趣的案例是进行图像压缩。在彩色图像中,每个像素的大小为3字节(RGB),可以表示的颜色总数为256 256 256。利用K-means算法把类似的颜色分别放在K个簇中,因此只需要保留每个像素的标签,以及每个簇的颜色编码即可完成图像的压缩。
8. 关联分析:挖掘啤酒与尿布(频繁项集)的关联规则
20世纪90年代美国沃尔玛超市中,超市管理人员分析销售数据时发现 “啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中。经过调查发现,这种现象出现在年轻的父亲身上。在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲去超市买尿布时,往往会顺便为自己购买啤酒。如果在卖场只能买到两件商品之一,他很有可能会放弃购物而去另一家可以同时买到啤酒与尿布的商店。由此,沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同区域,让年轻的父亲可以同时找到这两件商品,从而获得了很好的商品销售收入。
“啤酒+尿布”故事中利用的就是关联算法,比较常见的一种关联算法是FP-growth算法。
算法中几个相关的概念:
频繁项集:在数据库中大量频繁出现的数据集合。例如购物单数据中{‘啤酒’}、{‘尿布’}、{‘啤酒’, ‘尿布’}出现的次数都比较多。
关联规则:由集合 A,可以在某置信度下推出集合 B。即如果 A 发生了,那么 B 也很有可能会发生。例如购买了{‘尿布’}的人很可能会购买{‘啤酒’}。
支持度:指某频繁项集在整个数据集中的比例。假设数据集有 10 条记录,包含{‘啤酒’, ‘尿布’}的有 5 条记录,那么{‘啤酒’, ‘尿布’}的支持度就是 5/10 = 0.5。
置信度:有关联规则如{‘尿布’} -> {‘啤酒’},它的置信度为 {‘尿布’} -> {‘啤酒’}
假设{‘尿布’, ‘啤酒’}的支持度为 0.45,{‘尿布’}的支持度为 0.5,则{‘尿布’} -> {‘啤酒’}的置信度为 0.45 / 0.5 = 0.9。
应用比较广泛,例如:
用于制定营销策略。如同啤酒与尿布的例子,超市如果将啤酒和尿布放在相邻的位置,会增加两者的销量。
用于发现共现词。在浏览器中输入”普元”时,浏览器自动弹出如”普元平台”,”普元EOS”等备选记录。
FP-growth算法一个简单的案例:通过购物车数据,分析商品之间的关联关系。
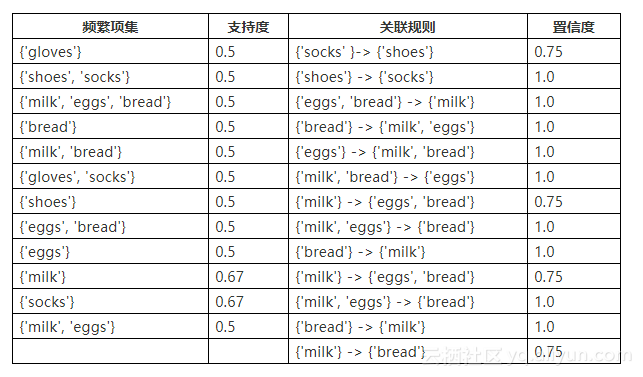
根据结果,可以分析出购买了鞋子,极有可能会同时购买袜子;购买了鸡蛋与面包,极有可能会购买牛奶。
9. PCA降维:减少数据维度,降低数据复杂度
降维是指将原高维空间中的数据点映射到低维度的空间中。因为高维特征的数目巨大,距离计算困难,分类器的性能会随着特征数的增加而下降;减少高维的冗余信息所造成的误差,可以提高识别的精度。
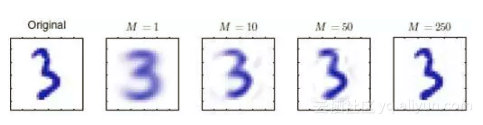
例如对数字进行降维,当使用1个特征向量的时候,3的基本轮廓已经保留下来了,特征向量使用的越多就越与原始数据接近。
10. 人工神经网络:逐层抽象,逼近任意函数
前面介绍了九种传统的机器学习算法,现在介绍一下深度学习的基础:人工神经网络。
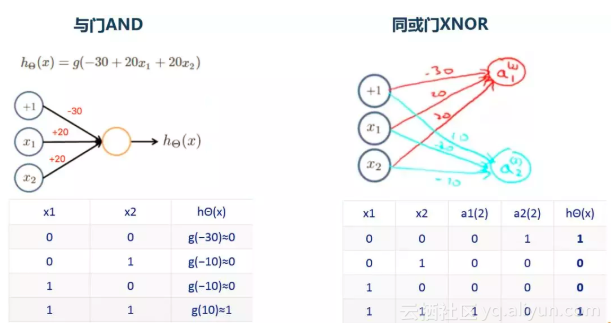
它是模拟人脑神经网络而设计的模型,由多个节点(人工神经元)相互联结而成,可以用来对数据之间的复杂关系进行建模。不同节点之间的连接被赋予了不同的权重,每个权重代表了一个节点对另一个节点的影响大小。每个节点代表一种特定函数,来自其他节点的信息经过其相应的权重综合计算。是一个可学习的函数,接受不同数据的训练,不断通过调整权重而得到契合实际模型,一个三层的神经网络可以逼近任意的函数。
多层神经网络的每一层神经元学习到的是前一层神经元值的更抽象的表示,通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。例如在图像识别中,第一个隐藏层学习到的是 “边缘”的特征,第二层学习由“边缘”组成的“形状”的特征,第三层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。
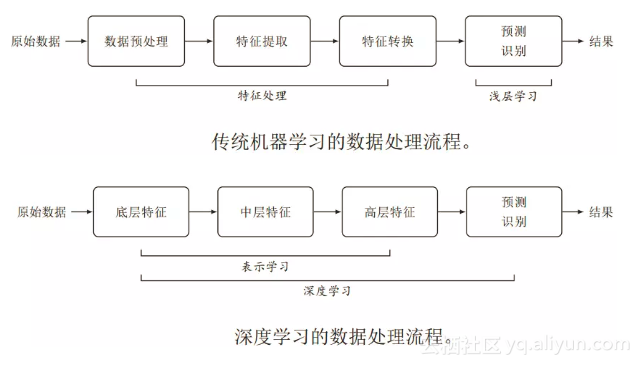
要提高一种表示方法的表示能力,其关键是构建具有一定深度的多层次特征表示 。一个深层结构的优点是可以增加特征的重用性,从而指数级地增加表示能力。从底层特征开始,一般需要多步非线性转换才能得到较为抽象的高层语义特征。这种自动学习出有效特征的方式称为“表示学习”。
深度学习就是一种基于对数据进行表征学习的方法,使用多层网络,能够学习抽象概念,同时融入自我学习,逐步从大量的样本中逐层抽象出相关的概念,然后做出理解,最终做出判断和决策。通过构建具有一定“深度”的模型,可以让模型来自动学习好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测或识别的准确性。
目前深度学习的应用十分广泛,例如图像识别、语音识别、机器翻译、自动驾驶、金融风控、智能机器人等。
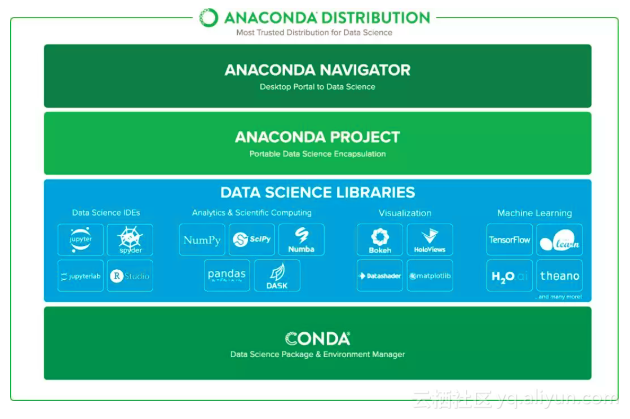
集成包功能:
NumPy:提供了矩阵运算的功能,其一般与Scipy、matplotlib一起使用,Python创建的所有更高层工具的基础,不提供高级数据分析功能
Scipy:依赖于NumPy,它提供便捷和快速的N维向量数组操作。提供模块用于优化、线性代数、积分以及其它数据科学中的通用任务。
Pandas:基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的,包含高级数据结构,以及和让数据分析变得快速、简单的工具
Matplotlib:Python最著名的绘图库
其中, Scikit-Learn是Anaconda中集成的开源机器学习工具包,主要涵盖分类,回归和聚类算法,可以直接调用传统机器学习的算法进行使用。同时Anaconda也兼容Google开发的第二代人工智能系统TensorFlow,进行深度学习的开发。
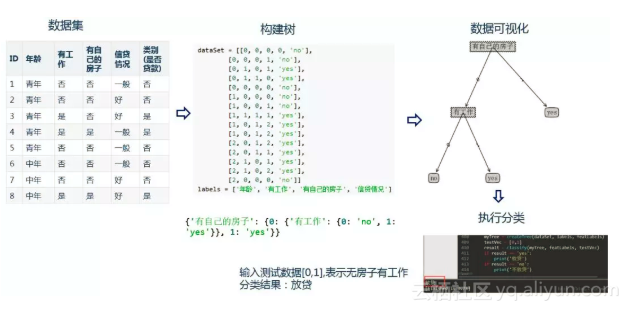
最后通过一个基于Python的决策树案例,来直观了解一下机器学习的过程。
贷款申请的决策树,用以对未来的贷款申请进行分类。
具体实现过程:
(1)准备数据集:从贷款申请样本数据表中,选取对训练数据具有分类能力的特征
(2)构建树:选择信息增益最大的特征作为分裂特征构建决策树
(3)数据可视化:使用Matplotlib对数据进行可视化
(4)执行分类:用于实际数据的分类。例如输入测试数据[0,1],它代表没有房子,但是有工作,分类结果为“房贷”。
四、总结
希望通过本次介绍,大家能够对机器学习涉及的算法有初步的认识,为以后进行相关人工智能方面的研究所有帮助。机器学习其实没有那么复杂,只是将统计学、概率论等数学知识应用在人工智能领域。借助现有的软件平台,可以轻松的调用已经集成的算法,让工程师不再为复杂的算法理论而烦恼,可以有更多的时间去开发和创新!
来源:52it.club
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!