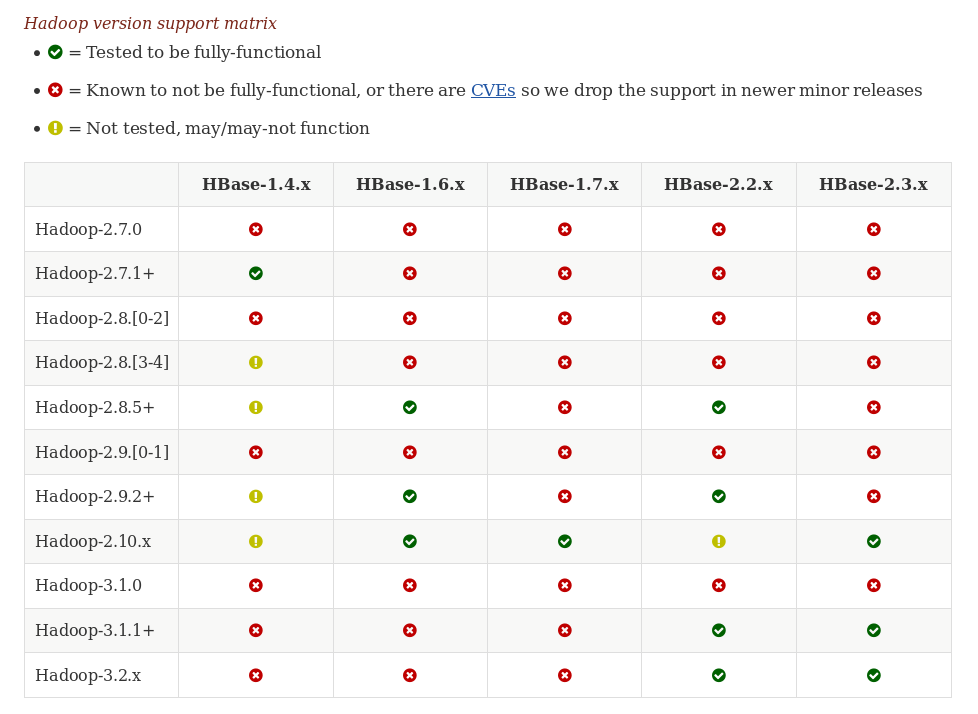
非生产环境,就使用一个新一点的版本,提前先踩踩坑,版本的选型真是一个头疼的问题,先看一下apache的官网的测试图:

伪分布式看这里:
配置之前:若是用伪分布式时,在本机必须生成key-gen 与ssh-copy-id到本机,且hosts中必须加入127.0.0.1 本机名并关闭防火墙这几步才可以,否则会报
ryan.pub: ssh: connect to host ryan.pub port 22: No route to host
ryan.pub: Warning: Permanently added ‘ryan.pub’ (ECDSA) to the list of known hosts.
先选好Spark:3.0.1
对应的Hadoop:3.2和2.7中选一个,综合上面的图,2.7无法使用HBase,只能选3.2了
#hadoop软件:
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1-src.tar.gz
#spark软件:
http://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz
#spark源码
http://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1.tgz
#hadoop源码
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
HBase:2.3.3
http://archive.apache.org/dist/hbase/2.3.3/hbase-2.3.3-bin.tar.gz
Hive: 3.1.2
http://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
ZooKeeper: 3.5.5
http://archive.apache.org/dist/zookeeper/zookeeper-3.5.5/apache-zookeeper-3.5.5-bin.tar.gz
Kafka:2.6-scala2.12
http://mirror.bit.edu.cn/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgz
Flume:1.9
http://mirror.bit.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
一次性将所有安装包全部传到linux01中,开始配置
集群环境配置:
| 主机名称/IP | spark | hadoop | mysql | hbase | hive | zookeeper | flume | kafka | redis |
| linux01.pub/192.168.10.10 | 1 | 1 | 1 | 1 | 1 | ||||
| linux02.pub/192.168.10.11 | 1 | 1 | 1 | ||||||
| linux03.pub/192.168.10.12 | 1 | 1 | 1 |
|
|||||
| linux04.pub/192.168.10.13 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| linux05.pub/192.168.10.14 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| linux06.pub/192.168.10.15 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
1、先在linux01上安装mysql
千万记住,安装前一定要删除本机所有的Mysql或Mariadb
直接参照此前写过的这篇,不再重复
https://blog.csdn.net/qq_36269641/article/details/109641947
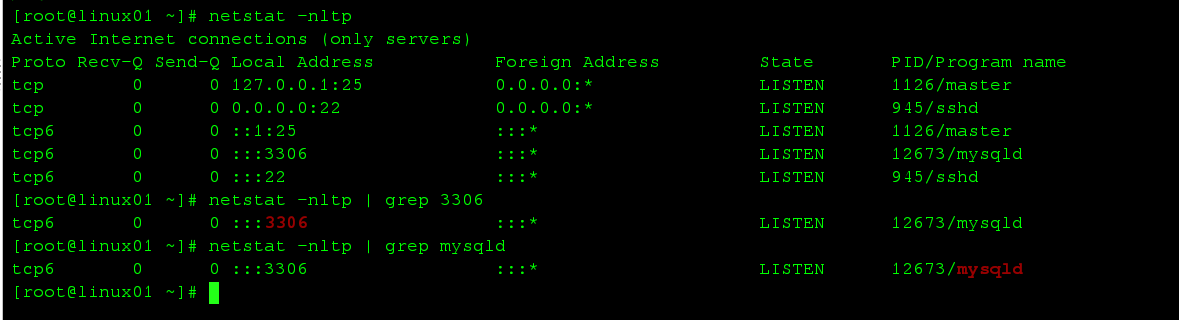
检查,mysql是否安装成功,可以用netstat, 如果没有可以用以下命令安装
# 安装网络工具
yum install -y net-tools
# 查看端口或程序
netstat -nltp |grep mysqld #或 3306
2、开始安装Spark:3.0.1与Hadoop3.2.1生态
之前写过一篇Hadoop3.1.1的:https://blog.csdn.net/qq_36269641/article/details/108986498
为了保险还是重新再来一遍
2.1 开始安装Hadoop3.2.1
hdfs是一切的基础,所以在所有机器上配置:namenode:linux01.pub secondary namenode:linux02.pub datanade:linux01~06.pub
#解压
tar -zxf hadoop-3.2.1.tar.gz -C /opt/apps/
2.1.1 配置环境变量,增加路径与登录用户:
vim /etc/profile
source /etc/profile
hadoop version

创建目录:临时文件目录、HDFS 元数据目录、HDFS数据存放目录,以后opt下的所有目录要全部分发到1-6台主机上去,所以统一在opt下创建
mkdir -p /opt/data/hdfs/name /opt/data/hdfs/data /opt/log/hdfs /opt/tmp
切换到配置文件目录下,开始配置hadoop
cd /opt/apps/hadoop-3.2.1/etc/hadoop
| core-site.xml | 核心配置文件 |
| dfs-site.xml | hdfs存储相关配置 |
| apred-site.xml | MapReduce相关的配置 |
| arn-site.xml | yarn相关的一些配置 |
| workers | 用来指定从节点,文件中默认是localhost |
| hadoop-env.sh | 配置hadoop相关变量 |
先修改hadoop-env.sh,加入java_home的变量,防止出错:
export JAVA_HOME=/home/apps/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.1.2 开始配置core: core-site.xml
2.1.3 配置HDFS:hdfs-site.xml
指定备用地址,副本数,元数据,数据位置,以及web网络访问
2.1.4 配置YARN: yarn-site.xml
yarn统一使用linux01.pub
来源:pub.ryan
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!