上一篇安装https://blog.csdn.net/weixin_42845306/article/details/112688405
飞桨的OCR模型分为检测、识别和分类,先看检测。
检测就是将(可能的)文本标定好坐标,简单说就是给图中的文本画框。
数据集制作及图片标注
首先制作训练集,找很多带文字的图片,放在一个文件夹里(这里叫img_50),注意图片的名字。
虽说可以任意,但最好还是得有规律。
然后是标定标签,方法有很多,这里用自带的PPOCRLabel,用法这里有详细介绍:
https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/PPOCRLabel/README_ch.md
大概用法就是安装pyqt(一个python中的可视化库),打开软件,载入放图片的文件夹,先半自动标注,然后手动调整,保存标记结果可以保存出一个label.txt里面密密麻麻放着坐标,保存识别结果可以把图片里面所有的文字全抠出来单独放进一个文件夹crop_img,作为识别训练集,还有对应的识别标签rec_gt.txt(识别这步下次再讲)。
注:原先的打开方式较为麻烦,每次都要输入代码,可以在PPOCRLabel文件夹下新建一个txt,输入然后保存成open.bat文件,以后每次打开就点这个文件就行了,

预训练模型安置
从网上下载预训练模型,比如https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV3_large_x0_5_pretrained.tar
解压一定要用这个命令:
tar -xf ./pretrain_models/MobileNetV3_large_x0_5_pretrained.tar
这样解压出来的才是很多个权值文件,右键解压会直接解压出一个大文件,无法使用。
将解压后的MobileNetV3_large_x0_5_pretrained模型文件夹放在PaddleOCR-dygraph下新建的pretrain_models文件夹中:
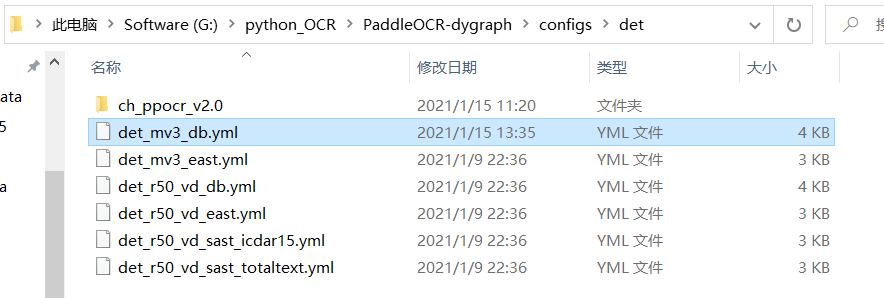
找到det_mv3_db.yml,这是检测模型MobileNetV3的参数训练设置,记事本打开。
里面的参数看着改,主要是这几点:
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained/
data_dir: ./train_data/img_50/
label_file_list:
– ./train_data/img_50/Label.txt
注意测试集和训练集的路径都要调整。
训练开始
在PaddleOCR-dygraph根目录打开cmd,输入以下其中之一命令即可测试
其实调整了.yml文件后,-o参数可以不写
训练进行中:
注意后面要写上模型的名字。
然后再调用命令训练,可以看到resume from

一切都可以从手册学到https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/detection.md
下一篇识别模型训练:https://blog.csdn.net/weixin_42845306/article/details/112726615
或者直接跳到:检测模型测试与评估(平均准确率、平均召回率、修改交并比IOU)
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树首页概览210539 人正在系统学习中
来源:非 常 道
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!