Elasticsearch宝典:从ELK到Elastic Stack
文/田雪松
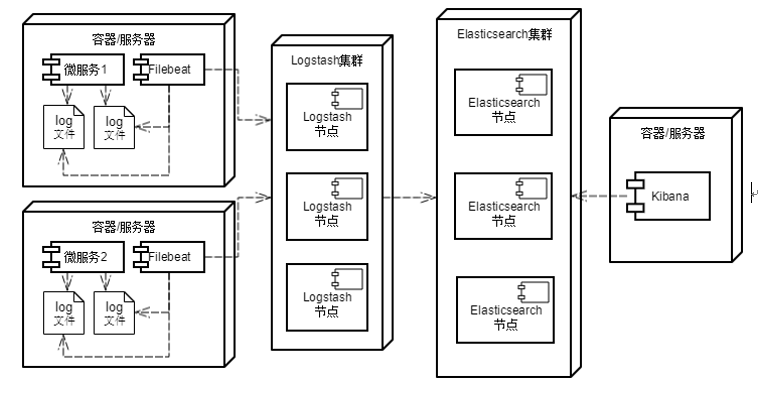

图1Elastic Stack收集日志
在典型的微服务应用场景中,日志文件分散不同的主机节点上。这种分散的日志文件不仅不利于查看,对于日后的数据分析和数据挖掘也是很大的阻碍。但是将这些日志数据集中写入到传统的关系型数据库中又不现实,因为日志数据是典型的大数据,大多数互联网应用一天产生的日志量就有几十G甚至上百G。传统的关系型数据库不仅存储不了这么大量的数据,而且随着数据量的增大查询数据也会变得越来越慢。而Elasticsearch不仅自身天然支持分片和复制,而且还可以通过倒排索引等机制提供了快速检索的能力,能够完美的解决大数据查询、存储和容灾等问题,所以使用Elastic Stack收集存储日志几乎是多数应用的备选方案之一。在图1.1中,Filebeat组件与微服务组件部署在同一台主机或同一个Docker容器中,它负责从微服务产生的日志文件中将采集出来并发送给Logstash。Logstash和Elasticsearch一般需要搭建成集群,以实现负载均衡和容灾容错。
Elastic Stack另一个典型应用场景是用于系统运行状态的监控。与收集日志不同的是,在这种应用场景下部署在主机节点上的Beats组件是Metricbeat或者Heartbeat,收集到的数据是系统度量数据和系统是否可达数据。这些监控数据不仅可通过Kibana轻松地实现可视化,还可以与Watcher组件或其它第三方应用结合起来实现报警功能。
除了组合在一起使用,Elastic Stack中的每一种组件又可以独立使用,或者是与第三方应用结合在一起使用。一种典型的应用场景是与Kafka等第三方MQ组件结合使用,以防止瞬间流量爆发导致的系统崩溃,如图2所示:
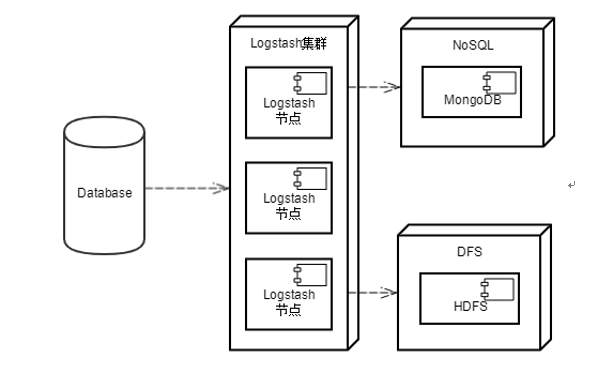
图3 Logstash使用
另一方面,Beats组件也可以跳过Logstash直接将数据发送给Elasticsearch,甚至是类似Redis、Kafka这样的第三方数据源。在更多的应用场景中,Elasticsearch则会被单独拿出来使用。Elasticsearch在很多时候都被视为一种基于文档的NoSQL数据库,这与MongoDB的定位完全相同,所以Elasticsearch的应用场景比其它组件更加广泛。可能惟一不会独立使用的组件就是Kibana,因为至少到目前它还是基于Elasticsearch的可视化工具,所以一般都需要与Elasticsearch共同使用。
总之,无论是整体应用Elastic Stack组件,还是单独应用其中的任意一个组件,Elastic Stack都可以完全胜任。

(节选自《Elastic Stack应用宝典》)
从此开始,我们将以最简单的方式快速浏览这些开源软件,并按图1的形式安装部署一套使用Elastic Stack收集日志文件的系统。如果有分布式环境,可以将它们分别部署在不同主机节点上,但要保证节点之间的通信正常。如果主机内存充裕,将它们安装在同一台主机也没有问题。为了降低复杂度,Logstash集群和Elasticsearch集群都只部署一个节点。所有Elastic Stack的软件,都可以在Elastic官方网站找到,具体地址是https://www.elastic.co/downloads。当然,Elastic Stack的这些组件也可以通过Docker镜像的方式启动。但为了体检原汁原味的部署过程,建议读者还是通过直接安装的方式部署这些组件。
Elastic Stack所有开源软件的源代码都在Git Hub上,如果想查看源代码,可以到https://github.com/elastic/查找。
来源:吕萧条
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!