林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
摘要:本文将使用Python3.4爬网页、爬图片、自动登录。并对HTTP协议做了一个简单的介绍。在进行爬虫之前,先简单来进行一个HTTP协议的讲解,这样下面再来进行爬虫就是理解更加清楚。
一、HTTP协议
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP的请求响应模型
HTTP协议永远都是客户端发起请求,服务器回送响应。见下图:
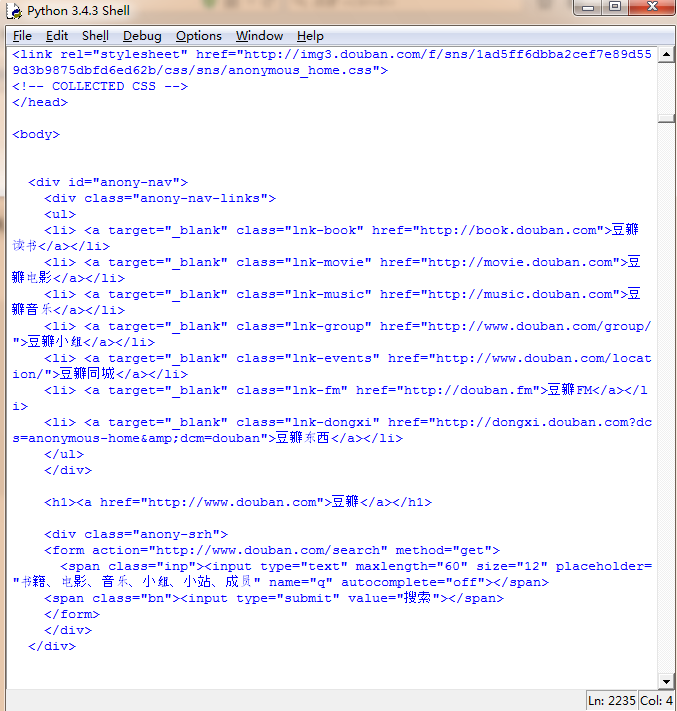

这中间到底发生了什么事呢我们打开Fiddler来看看吧:
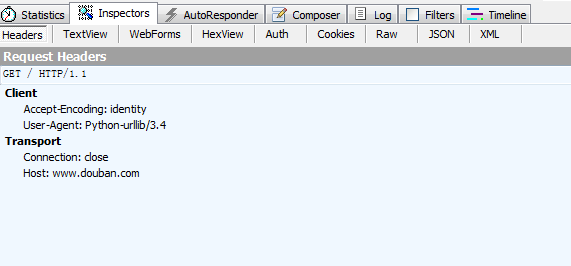
很简单的一个报头,然后再来看看响应回来的html

来看看请求报头,就是和我们设置的一个样。
再来一个复杂一点的请求报头:
看看生成 的结果:
3、爬取网站上的图片
前面我们可以爬网页了,下一步我们就可以批量的自动下载该网页上的各种数据了~,比如,这里我要下载该网页上的所有图片
这是正在运行的过程:
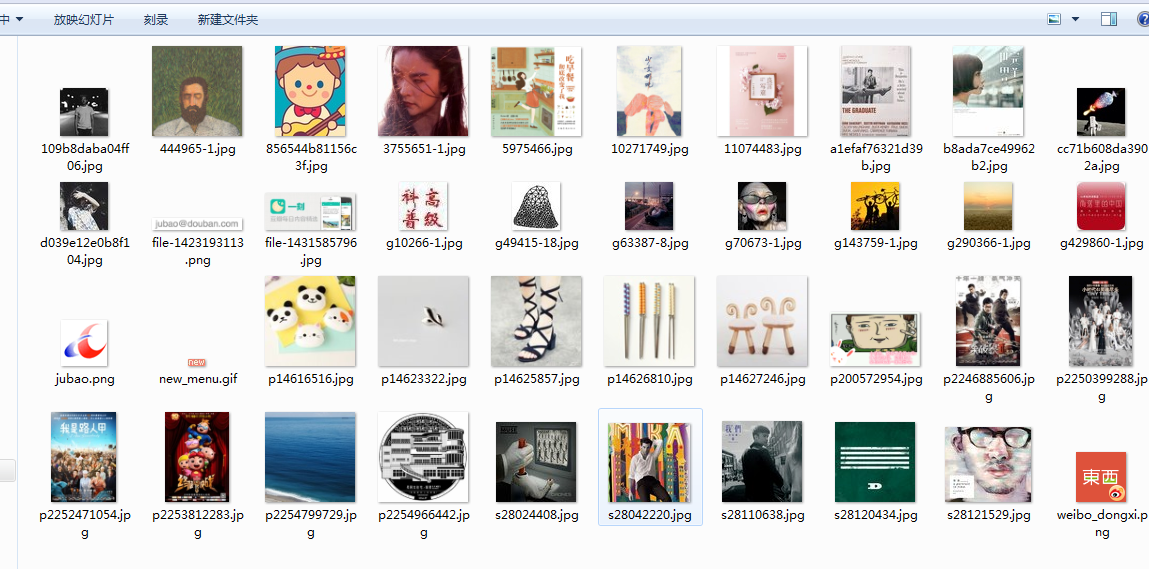
真实的网页上的图片
4、保存爬取回来的报文
比如:
来源:Evankaka
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!