背景
- 目前 机器学习平台 后端采用k8s架构进行GPU和CPU资源的调度和容器编排。总所周知,k8s的后端核心存储使用etcd进行metadata持久化存储。机器学习平台采取External etcd topology结构进行etcd的HA部署。

问题记录
- 2020-01-06 运维同学反馈2019年12月中旬etcd慢日志监控出现大量的告警记录,而且告警呈上升趋势。

问题分析
- 2020-01-06 运维同学反馈告警问题时,当时怀疑etcd 集群磁盘latency性能问题,通过etcd metrics接口dump backend_commit_duration_seconds 和 wal_fsync_duration_seconds,latency区间在128ms。etcd官方文档what-does-the-etcd-warning-apply-entries-took-too-long-mean 建议排查磁盘性能问题,保证 “p99 duration should be less than 25ms”。和运维同学讨论,先将etcd设置的慢日志阈值调整到100,继续跟踪告警问题。
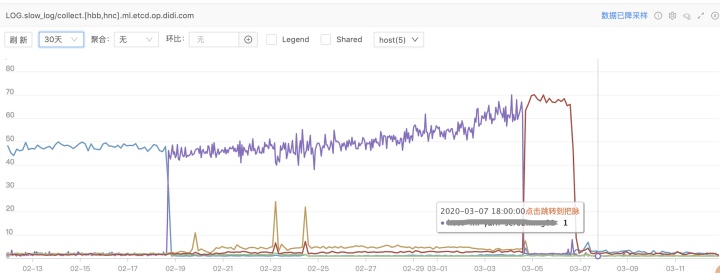
- 2020-01-20 运维同学继续反馈慢日志告警,调整到100个告警阈值,慢日志告警数量还是呈上升趋势。查看每台etcd服务的监控,发现告警集中在某一台etcd服务上,当etcd服务重启时,告警会发生迁移;告警值会继上一个etcd服务重启后的数,继续上涨。


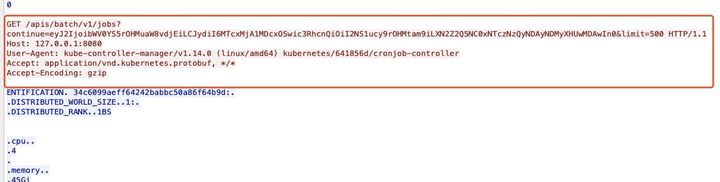
- 查看cronjob_controller的代码,发现不是使用的 JobInformer 而是通过clientset list了所有namespace下的job。当前机器学习平台k8s集群,全部namespace下的job,一次list 分页查询会返回慢日志。
参考资料
- Options for Highly Available topology
- Set up a High Availability etcd cluster with kubeadm
- etcdserver: read-only range request took too long with etcd 3.2.24
- etcd namespace metrics
- what-does-the-etcd-warning-apply-entries-took-too-long-mean
作者:童超【滴滴出行资深软件开发工程师】
- 现在注册滴滴云,得8888元立减红包
- 7月特惠,1C2G1M云服务器 9.9元/月限时抢
- 滴滴云使者专属特惠,云服务器低至68元/年
- 输入大师码【7886】,GPU全线产品9折优惠
滴滴云-为开发者而生 滴滴云使者 文章知识点与官方知识档案匹配,可进一步学习相关知识Java技能树首页概览91960 人正在系统学习中
来源:「已注销」
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!