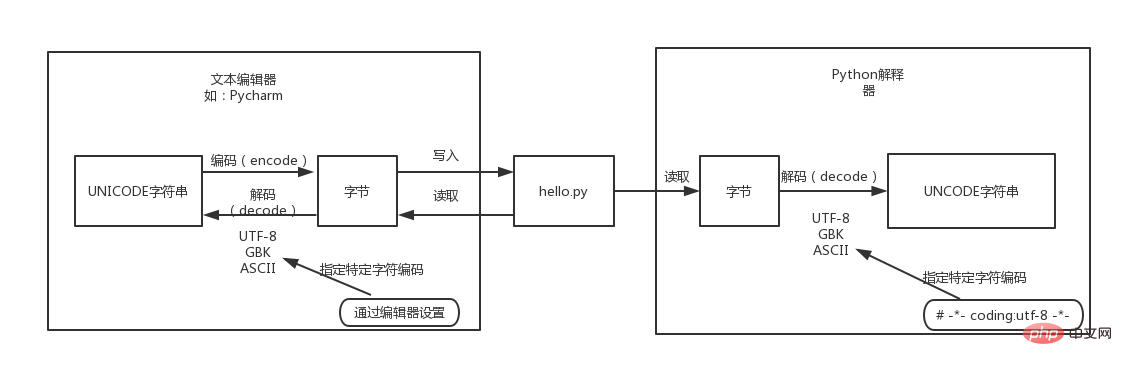
 PyCharm等IDE开发工具指定的项目工程和文件的字符编码: 它的主要作用是告诉Pycharm等IDE开发工具保存文件时应该将字符转换为怎样的字节表示形式,以及打开并展示文件内容时应该以什么字符编码将字节码转换为人类可识别的字符。
PyCharm等IDE开发工具指定的项目工程和文件的字符编码: 它的主要作用是告诉Pycharm等IDE开发工具保存文件时应该将字符转换为怎样的字节表示形式,以及打开并展示文件内容时应该以什么字符编码将字节码转换为人类可识别的字符。
Python源代码文件头部指定的字符编码,如*-* coding:utf-8 -*-: 它的主要作用是告诉Python解释器当前python代码文件保存时所使用的字符编码,Python解释器在执行代码之前,需要先从磁盘读取该代码文件中的字节然后通过这里指定的字符编码将其解码为unicode字符。Python解释器执行Python代码的过程与IDE开发工具是没有什么关联性的。
那么这里为什么又要谈起字符编码的问题呢/p>
或者换个问法,既然从上面已经指定了字符编码,为什么对文件进行读写时还要指定字符编码呢前面的描述可以看出:上面两个地方指定的是Python代码文件的字符编码,是给Python解释器和Pycharm等程序软件用的;而被读写文件的字符编码与Python代码文件的字符编码没有必然联系,读写文件时指定的字符编码是给我们写的程序软件用的。这是不同的主体和过程,希望我说明白了。
读写文件时怎样指定字符编码呢/p>
上面解释了读写文件为什么要指定字符编码,这里要说下怎样指定字符编码(其实这里主要讨论是读取外部数据时的情形)。这个问题其实在上面的文件读取示例中已经使用过了,这里我们再详细的说一下。
首先,再次看一下Python2和Python3中open函数的定义:# Python2open(name[, mode[, buffering]])# Python3open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
可以看到,Python3的open函数中多了几个参数,其中包括一个encoding参数。是的,这个encoding就是用来指定被操作文件的字符编码的。# 读操作with open(‘song.txt’, ‘r’, encoding=’utf-8′) as f:
print(f.read())# 写操作with open(‘song.txt’, ‘w’, encoding=’utf-8′) as f:
print(f.write(‘你好’))
那么Python2中怎样指定呢ython2中的对文件的read和write操作都是字节,也就说Python2中文件的read相关方法读取的是字节串(如果包含中文字符,会发现len()方法的结果不等于读取到的字符个数,而是字节数)。如果我们要得到 正确的字符串,需要手动将读取到的结果decode(解码)为字符串;相反,要以特定的字符编码保存要写入的数据时,需要手动encode(编码)为字节串。这个encode()和decode()函数可以接收一个字符编码参数。Python3中read和write操作的都是字符串,实际上是Python解释器帮我们自动完成了写入时的encode(编码)和读取时的decode(解码)操作,因此我们只需要在打开文件(open函数)时指定字符编码就可以了。# 读操作with open(‘song.txt’, ‘r’) as f:
print(f.read().decode(‘utf-8’))
# 写操作with open(‘song2.txt’, ‘w’) as f:
# f.write(u’你好’.encode(‘utf-8’))
# f.write(‘你好’.decode(‘utf-8’).encode(‘utf-8’))
f.write(‘你好’)
文件读写时有没有默认编码呢/p>
Python3中open函数的encoding参数显然是可以不指定的,这时候就会用一个”默认字符编码”。
看下Python3中open函数文档对encoding参数的说明:encoding is the name of the encoding used to decode or encode thefile. This should only be used in text mode. The default encoding isplatform dependent, but any encoding supported by Python can be
passed. See the codecs module for the list of supported encodings.
也就是说,encoding参数的默认值是与平台有关的,比如Window上默认字符编码为GBK,Linux上默认字符编码为UTF-8。
而对于Python2来说,在进行文件写操作时,字节会被直接保存;在进行文件读操作时,如果不手动进行来decode操作自然也就用不着默认字符编码了。但是这时候在不同的字符终端打印的时候,会用当前平台的字符编码自动将字节解码为字符,此时可能会出现乱码。如song.txt文件时UTF-8编码的,在windows(字符编码为GBK)的命令行终端进行如下操作就会出现乱码:>>> with open(‘song.txt’, ‘r’) as f:
… print(f.read())
…
鍖嗗寙閭e勾鎴戜滑 绌剁珶璇翠簡鍑犻亶 鍐嶈涔嬪悗鍐嶆嫋寤/p>
鍙儨璋佹湁娌℃湁 鐖辫繃涓嶆槸涓€鍦冩儏涓婇潰鐨勯泟杈/p>
鍖嗗寙閭e勾鎴戜滑 涓€鏃跺寙蹇欐拏涓句互鎵垮彈鐨勮瑷€
鍙湁绛夊埆浜哄厬鐜
我们应该尽可能的获取被操作文件的字符编码,并明确指定encoding参数的值。
以上就是python怎么读写文件操作的详细内容,更多请关注php中文网其它相关文章!
本文原创发布php中文网,转载请注明出处,感谢您的尊重!
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树进阶语法文件209413 人正在系统学习中 相关资源:翠雨方工作备忘录工具v2.31中文绿色版-其它代码类资源-CSDN文库
来源:编程大乐趣
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!