数据科学平台是慧都提供的数据挖掘、预测分析解决方案,平台拥有简单的图形界面和高级分析能力,利用强大的建模、评估和自动化功能发现结构化和非结构化数据中的趋势,使得企业和分析师增加生产力,分析大数据以获取预测性洞察,制定有效的业务战略。数据科学平台可按照企业实际需求完全定制。
数据科学平台是提供的数据挖掘、预测分析解决方案,平台拥有简单的图形界面和高级分析能力,利用强大的建模、评估和自动化功能发现结构化和非结构化数据中的趋势,使得企业和分析师增加生产力,分析大数据以获取预测性洞察,制定有效的业务战略。数据科学平台可按照企业实际需求完全定制。
主要算法(并不仅限于本案例)
1.Logistic回归
Logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。
优点:计算代价不高,易于理解和实现;
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
适用情景:LR的好处是输出值自然地落在0到1之间,并且有概率意义,但处理不好特征之间相关的情况。虽然效果一般,却胜在模型清晰,背后的概率学经得住推敲。它拟合出来的参数就代表了每一个特征对结果的影响,是一个理解数据的好工具。
2.决策树(decision tree)
决策树是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
优点:容易解释,非参数型
缺点:趋向过拟合,可能或陷于局部最小值中,没有在线学习。
适用情景:数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。同时它抗噪声的能力较低,换句话说,它很容易被“脏数据”影响的分类器。因为决策树最终在底层判断是基于单个条件的,往往只要有一小部分“脏数据”就可以影响学习效果。受限于它的简单性,决策树更大的用处是作为一些更有用的算法的基石。
3.随机森林
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。
优点:不会过拟合,能够展现变量的权重,具有很好的抗干扰能力
缺点:可能由于叠加掩盖真实的结果,对小数据或者低维数据分类效果差,学习效率慢。
适用情景:数据维度相对低(几十维),同时对准确性有较高要求时。因为不需要很多参数调整就可以达到不错的效果,不知道用什么方法的时候都可以先试一下随机森林。
4.支持向量机(SVM)
支持向量机是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的推广能力 。
优点:在非线性可分问题上表现优秀
缺点:非常难以训练,很难解释
适用情景:SVM在很多数据集上都有优秀的表现。相对来说,SVM尽量保持与样本间距离的性质导致它抗攻击的能力更强。和随机森林一样,这也是一个拿到数据就可以先尝试一下的算法。
5.朴素贝叶斯(Naive Bayes)
在机器学习中,朴素贝叶斯分类器是一个基于贝叶斯定理的比较简单的概率分类器,其中朴素是指的对于模型中各个特征有强独立性的假设,并未将 feature 间的相关性纳入考虑中。
优点:快速、易于训练、给出了它们所需的资源能带来良好的表现
缺点:如果输入变量是相关的,则会出现问题
适用情景:需要一个比较容易解释,而且不同维度之间相关性较小的模型的时候。可以高效处理高维数据,虽然结果可能不尽如人意。
6.KNN
kNN算法又称为k近邻分类(k-nearest neighbor classification)算法,是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
优点:简单,易于理解,易于实现,无需估计参数,无需训练
缺点:懒惰算法,对测试样本分类时的计算量大,可解释性较差。
适用情景:适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)。特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类
7.线性回归
线性回归是最为人熟知的建模技术之一,通常也是预测模型的首选技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。
优点:适合多因素模型,简单,方便,计算结果唯一,可以准确地计量各个因素之间的相关程度与回归拟合程度的高低。
缺点:需要选择合适的输入变量,且输入变量不能有相关性,且有较高的局限性(响应变量和预测变量必须存在线性关系才能使用线性回归)。
适用情景:如果输入数据符合回归模型的假设条件时,此种方法为最简单明了,预测效果最佳的方法。任何数据质量不高或者数据模型选取不当的行为,都会导致学习的结果异常。
汽车制造企业案例:设备运维预测
案例客户为国内一家汽车制造企业,旗下畅销车型销量一直位列国内同级别前三位,工厂各产线常年处于全负荷运转的状态。此外,工厂拥有数量众多的现代化生产设备,如冲压设备、焊装设备、涂装设备、总装设备等,企业设备管理科对各种设备维护检修压力巨大,设备配件的备件工作也始终是困扰客户的难题。
经过多次去客户现场实地考察以及和设备管理人员的深入沟通,为客户量身定制了设备运维预测分析平台解决方案,方案依托于数据科学平台打造,基于客户的业务目标,利用机器学习算法,结合业务对象模型对特征值(采集的设备各参数)进行数据探究和特征项的预处理,通过不断迭代的过程构建设备维护及故障预测模型,再结合测试数据集对构建的模型进行评估。
预测平台的诞生,使得设备的维护不再像此前只是遵循固定的维护时间表,而是用预测模型判断设备实际的运行状况是否需要维护,有效降低维护的频率,从而减少工厂设备维护的支出,设备配件备件人员也可按照预测情况进行科学的备件。除此之外,平台还可根据历史数据对设备的突发故障进行预测和预警,降低设备宕机的风险。
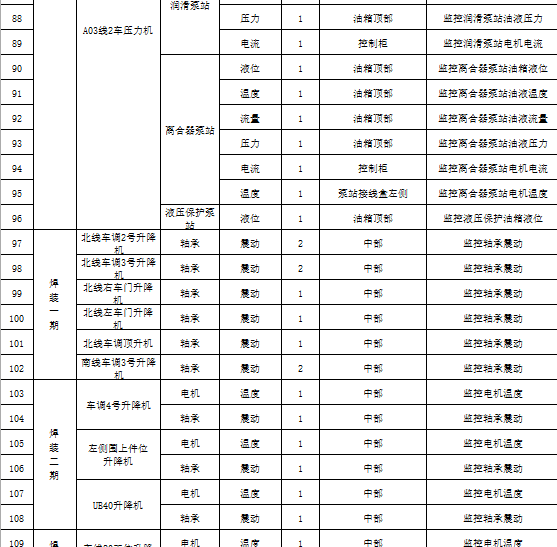
设备参数类型截图:

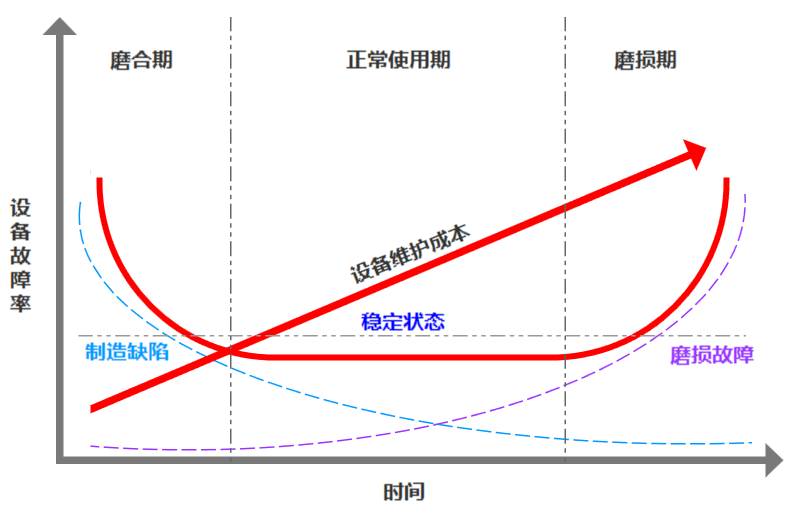
经过对工厂设备数据的分析及考证,设备故障率随时间变化趋势如下:
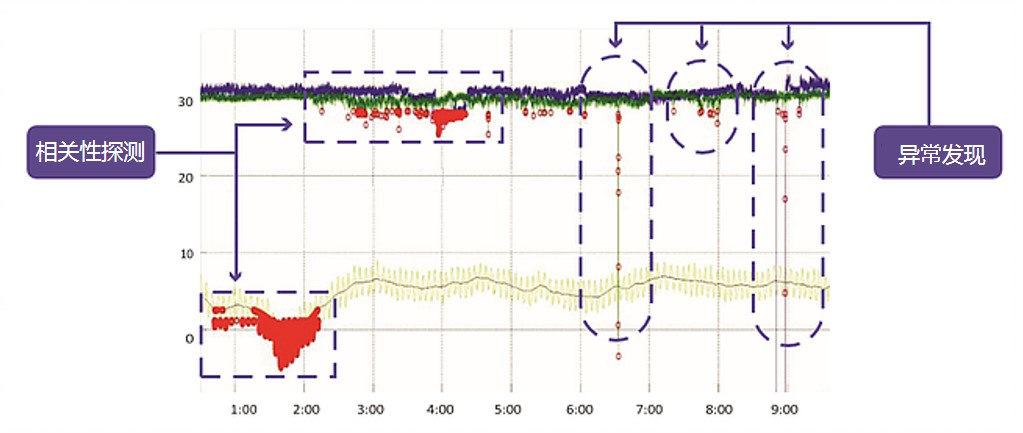
平台截图如下:
关于大数据分析平台
大数据分析平台「GetInsight升级发布,将基于企业管理驾驶舱、产品质量分析及预测、设备分析及预测等大数据模型的构建,助力企业由传统运营模式向数字化、智能化的新模式转型升级,抓住数据经济的发展势头,提供管理效能,精准布局未来。了解更多,请联系在线客服。
大数据专业团队为企业提供商业智能大数据平台搭建,免费业务咨询,定制开发等完整服务,快速、轻松、低成本将任何Hadoop集群从试用阶段转移到生产阶段。
欢迎拨打热线或咨询在线客服,我们有专业的大数据团队,为您提供免费大数据相关业务咨询!
标签:
来源:慧都
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!