项目目的:预测客户的交易价值。数据内容:4459条已知客户的交易价值和客户的属性(具体内容不知道,有可能是性别、年龄、收入、交税等等,每一个用户有4993条属性)。步骤:数据分析、特征值选取、模型建立、调试。
项目目的:预测客户的交易价值
数据来源:https://www.kaggle.com/c/santander-value-prediction-challenge
数据内容:4459条已知客户的交易价值和客户的属性(具体内容不知道,有可能是性别、年龄、收入、交税等等,每一个用户有4993条属性)

步骤:
- 数据分析
- 特征值选取
- 模型建立
- 调试
数据分析

有4459行,4993列,其实中1845列为float类型,3147列为int类型,有1列为object(应该为用户id)
特征值选取
观察发现特征值数量较大
初步处理:去掉常数列,去掉重复列
数据由4993变为4732
由于特征值太多,难以作图分析
直接使用所有特征值
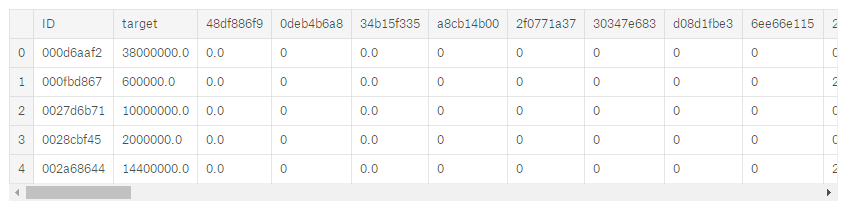
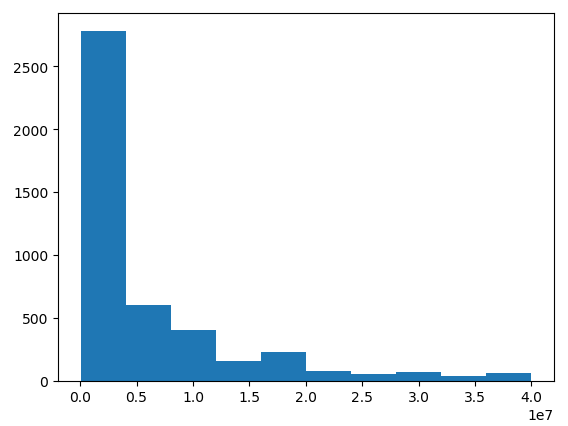
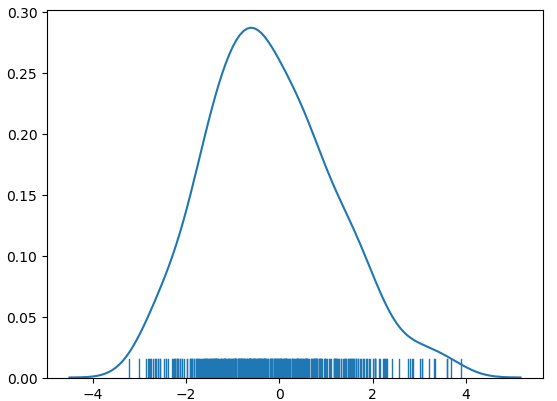
对需要预测值分析,观察数据分布(下图左),大部分数据集中在左侧,做log处理使数据更符合高斯分布(下图右)。通常高斯分布的数据预测更准确(原因不是很清楚,个人理解是如果有较大值出现,预测偏差一点,loss改变很大,对拟合不利)。
方法1
可能存在问题,样本太少,有可能过拟合。先看下效果在说吧。
首先建立了一个4层的dnn网络(详见test_dnn.py)
预测结果分析
对测试集进行测试
衡量标准为为均方根
计算方法:sqrt((预测值–原始值)**2/样本数)
Rms=1.84
下图为预测误差分布图
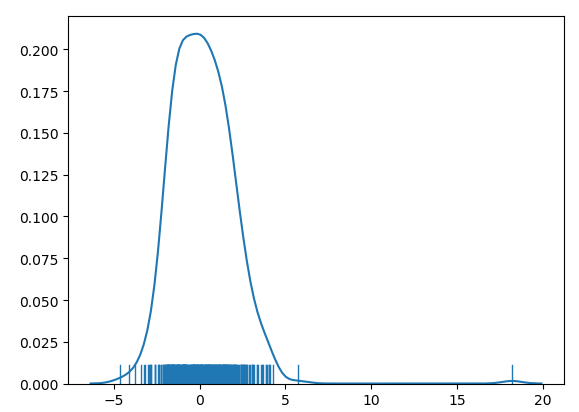
结果分析:效果不理想,预测值与真实值差距较大,有一个值偏离非常大
原因分析:
1. 模型结构不够理想
2. 超参数的设置
3. 样本太少,有200w的参数但是样本只有4000+,过拟合问题严重(在20次迭代后,就发生过拟合了)

方法2
使用lightgbm
直接使用lightgbm库(能用,但是对调参还需要学习)
详见test_lightgbm.py
预测结果分析
对测试集进行测试
衡量标准为均方根
Rms=1.35
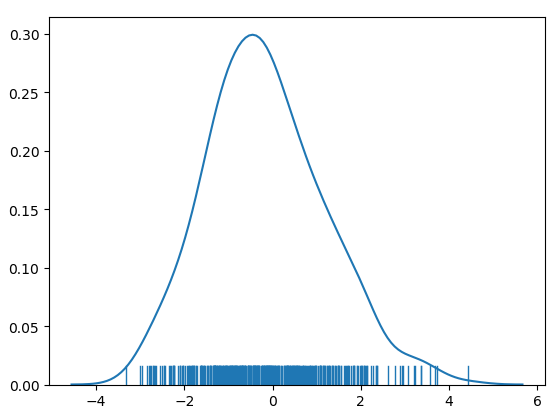
结果分析:效果依旧不理想,但是比dnn较好,而且没有偏移非常大的值
原因分析:
1. 依旧存在过拟合
2. 模型参数设置
方法3
使用xgboost
方法同上
预测结果
Rms=1.38
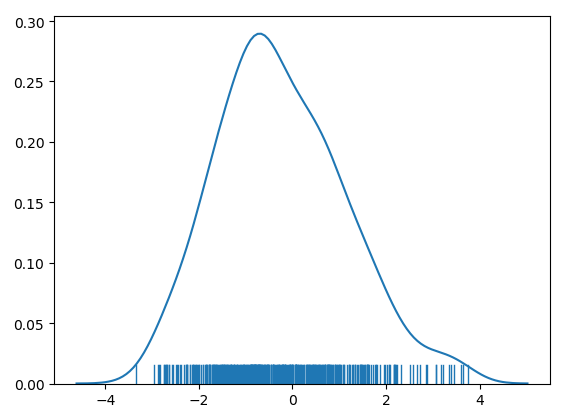
结果分析:效果依旧不理想
原因分析:
1. 2000次迭代次数不够,模型还未收敛
2. 模型参数设置
方法4
使用catboost
方法同上
预测结果
Rms=1.47
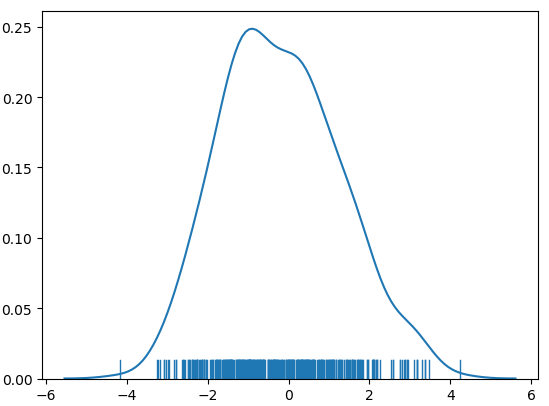
结果分析:效果依旧不理想
方法5
使用集成学习的思想,将上面的方法混合使用
将3个学习器的结果根据权重求和,得到最后结果
Rms=1.36
结果分析:
使用4种方法对预测目标进行建模,其中dnn由于数据太少,很早就发生了过拟合
Xgboost,lightgbm,catboost效果比dnn要好很多,但是对价值预测依然存在偏差。但是结合kaggle的论坛帖子,由于数据特点在不使用leak的情况下 这已经是不错的预测。由于调参修改的时间需求较大就不进行了,这里只是一个验证,验证结果为Xgboost,lightgbm,catboost在数据量较少的场景,效果是非常好的。
大数据分析平台,将学习、推理、思考、预测、规划等能力赋予企业数据,让数据驱动决策,创造最高业务价值。
欢迎拨打热线或咨询在线客服,我们将帮您转接大数据专业团队,并发送相关资料给您!
标签:
来源:慧都
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!