语法是用来描述语言的一套规则,因此研究规则的格式是很自然的。这就是我们在这个9部分系列的第4部分中所要做的。
在继续之前,请务必首先查看第1部分、第2部分和第3部分!
语法
语法是用来描述语言的一套规则,因此研究规则的格式是很自然的。然而,典型语法中还有几个元素可以引起进一步的关注。其中一些原因是因为语法也可以用来定义其他职责或者执行一些代码。
典型的语法问题
首先,我们将讨论在解析中可能遇到的一些特殊规则或问题。
缺少的Tokens
如果你阅读语法,你可能会遇到许多其中只定义了几个tokens的东西,而不是全部。就像这个语法一样:
NAME : [a-zA-Z]+greeting : "Hello" NAME
token “你好”没有定义,但既然你知道一个解析器处理tokens,你可能会问自己这怎么可能。答案是有些工具会为您生成字符串文字的对应token,以节省您一些时间。
请注意,这可能只在某些条件下才有可能。例如,使用ANTLR,如果您定义了单独的词法分析器和分析器语法,则必须自己定义所有的tokens。
左递归规则
在解析器的上下文中,一个重要的特性是支持左递归规则。这意味着一条规则从对自身的引用开始。有时候,这个参考也可能是间接的;也就是说,它可能出现在第一个引用的另一个规则中。
考虑例如算术运算。一个加法可以被描述为由加号(+)分隔的两个表达式,但是加法的操作数可以是其他的加法。
addition : expression '+' expressionmultiplication : expression '*' expression// an expression could be an addition or a multiplication or a numberexpression : multiplication | addition | [0-9]+
在这个例子中,表达式通过规则的加法和乘法包含对自身的间接引用。
此描述也匹配多个添加如5 + 4 + 3。这是因为它可以解释为表达式(5)(’+’)表达式(4 + 3)(规则加法:第一个表达式对应于选项[0 -9] +,第二个是另外一个)。然后4 + 3本身可以分为两个部分:表达式(4)(’+’)表达式(3)(规则加法:第一个和第二个表达式都对应于选项[0-9] +)。
该问题是左递归规则可能不能用于一些解析器生成器。另一种选择是长链表达,也关心运营商的优先级。不支持这些规则的解析器的典型语法看起来与此类似:
expression : additionaddition : multiplication ('+' multiplication)*multiplication : atom ('*' atom)*atom : [0-9]+
正如你所看到的,表达式是按照优先顺序的相反顺序来定义的。因此,解析器会将低优先级的表达式放在最低级别的表达式中;因此,他们将首先执行。
一些解析器生成器支持直接的左递归规则,但不支持间接的。请注意,通常,问题是不支持左递归规则的解析算法。因此,解析器生成器可以将以正确的方式写成左递归的规则转换成使其与其算法一起工作。在这个意义上,左递归支持可能是(非常有用的)语法糖。
左递归规则是如何转换的
规则转换的具体方式因语法分析器的不同而不同, 然而,逻辑保持不变。表达式分为两组:一组有运算符和两个操作数和原子。在我们的例子中,唯一的原子表达式是一个数字([0-9] +),但也可以是括号((5 + 4))之间的表达式。这是因为在数学中,括号被用来增加表达的优先级。
一旦拥有了这两个组,就可以维护第二组成员的顺序,并颠倒第一组成员的顺序。原因是人类以先到先得的原则推理:按优先顺序编写表达式比较容易。
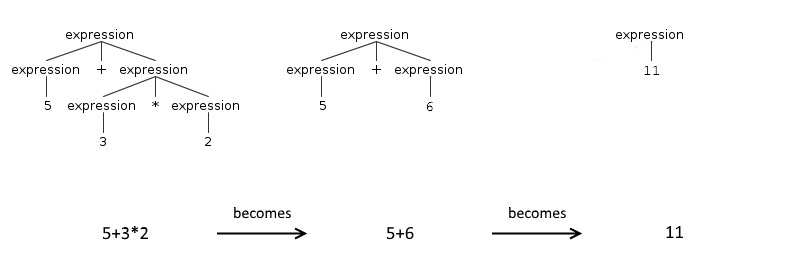

然而,解析的最终形式是一棵树,它运行在一个不同的原理上:你开始在树叶上工作,并在这个过程结束时,根节点包含最终结果——这意味着在解析树的原子表达式在底部,而带有运算符的那些则以相反的顺序出现。
谓语
谓语(有时称为句法或语义谓词)是特殊的规则,只有在满足某个条件的情况下才能匹配。该条件是用编写语法的工具所支持的编程语言中的代码定义的。
它们的优点是它们允许某种形式的上下文相关的解析,这有时是不可避免的匹配某些元素。例如,它们可以用来确定定义一个软关键字的字符序列是否被用在关键字的位置(即前一个关键字后面可以跟着一个关键字),还是一个简单的标识符。
缺点是它们减慢了解析速度,并且使语法依赖于所述编程语言。那是因为条件是用编程语言表达的,必须检查。
嵌入式操作
嵌入式操作辨认每次匹配规则时执行的代码。由于规则被代码所包围,它们有明显的缺点,使得语法难以阅读。此外,就像谓语一样,它们打破了描述语言的语法和操纵解析结果的代码之间的分离。
不太复杂的解析生成器经常使用操作作为在节点匹配时轻松执行某些代码的唯一方法。使用这些解析器世代,唯一的选择是遍历树并自己执行正确的代码。更高级的工具反而允许使用访问者模式(visitor pattern)在需要的时候执行任意代码,并且管理树的遍历。
它们也可以用来添加特定的tokens或更改生成的树。虽然不美观,但这可能是处理像C这样的复杂语言或像Python中的空白这样的特定问题的唯一实用方法。
请继续关注第5部分,我们将主要讨论语法格式。
本文原作者:Gabriele Tomassetti翻译:Elyn
推荐阅读:
展望2018年:基于AI人工智能的移动应用程序开发将如何发展
开发一个聊天机器人(Chatbot)应用程序需要花费多少钱/h5>
PS: 更多人工智能、大数据相关视频、培训、公开课,请关注【学院】!
关于人工智能技术的最新资讯和相关开发工具推荐,请<咨询在线客服>!

标签:人工智能解析器语法解析NLP自然语言处理
来源:慧都
声明:本站部分文章及图片转载于互联网,内容版权归原作者所有,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!